单pod单IP模型
该网络模型的目标是为每个pod分配一个Kubernetes集群私有网络地址段(譬如10.x.x.x)的IP地址,通过该IP地址,pod能够跨网络与其他物理机、虚拟机或容器进行通信,pod内的容器全部共享这pod的网络配置,彼此之间使用localhost通信,就仿佛它们运行在一个机器上一样。
为每个pod分配一个IP地址的另一个好处是用户不再需要显式为相互通信的pod内的容器创建Docker link,况且Docker link也无法解决容器的跨宿主机通信问题。我们称Kubernetes的这种网路模型为单pod单IP模型。在该模型中,从端口分配、网络通信、域名解析、服务发现、负载均衡、应用配置和迁移等角度,pod都能够被简单地看成一台独立的虚拟机或物理机,这就大大降低了用户应用从虚拟机或物理机向容器迁移的成本,甚至还能够与原先的网络基础设施兼容。
在这种网络环境下,在任意一个Kubernetes集群中的容器内调用ioctl发起一个获取其网卡IP地址的请求时,它所获得的IP地址和其他与它通信的容器看到的IP地址是一样的,即Kubernetes为每个pod分配的IP地址都在一个非NAT(网络地址转换)的扁平化网络地址空间中(这一点非常重要,因为NAT将网络地址空间分段的做法,不仅引人了额外的复杂性,还带来了破坏自注册机制等问题)。这个扁平网络加上单pod单IP原则,就构成了Kubernetes的网络模型。
注意,Kubernetes的网络模型中的扁平网络并不是由Kubernetes保证,而是由用户来保证的。也就是说,用户要么使用某种IaaS(最典型的就是GCE)来实现pod的扁平化网络空间,要么借助网络工具(如OpenVSwich等)手动创建好这样的网络。当然,不管哪种方法,Kubernetes都会使用iptables完成pod内容器端口在宿主机上的端口映射,发往宿主机端口的流量会被转发至对应pod中的容器,而从pod发往宿主机外部的流量需要使用宿主机的IP地址进行源地址转换。
pod和网络容器
单pod单IP模型的实质是Kubernetes将IP地址应用到pod范围,同一个pod内的容器共享包括IP地址在内的网络namespace。这意味着同一个pod内的容器能够在localhost上访问各自的端口,而且这些容器可能会发生端口冲突。在每个pod中有一个网络容器(有时候也称为pod基础容器或者infra容器),该容器先于pod内所有用户容器被创建,并且拥有该pod的网络namespace, pod的其他用户容器使用Docker的–net=container:<id>选项加入
该网络namespace,这样就实现了pod内所有容器对网络栈的共享。
接下来,Kubernetes每次在上述pod内创建用户容器时,都会指定该网络容器名作为其POD参数(最终映射成为Docker命令的net参数)。这样Docker会先找到这个网络容器进程的PID,进而获得其网络namespace和进程间通信namespace的文件描述符(fd )。然后,用户容器就在自己的proc/{PID}/ns/目录下创建一个硬链接文件net,指向网络容器的上述网络namespace,从而实现对网络容器netns的共享。
实现Kubernetes的网络模型
Kubernetes的网络模型里pod必须都处在一个扁平化的网络地址空间中,即需要满足如下3个假设(个别依据实际应用场景而分隔的特殊网段除外):
- 所有容器之间的通信无需经过NAT。
- 所有集群节点与容器、容器与集群节点的通信无需经过NAT。
- 容器本身看到的容器IP地址与其他容器看的IP地址是一样的。
这就意味着用户不能只是启动两台运行Docker容器的minion节点然后指望Kubernetes能让他们建立连接:用户需要自己帮助Kubernetes完成网络模型的实现,并保证最终的网络满足以上3个基本条件。
GCE上的实现
作为Kubernetes的原生支撑平台,GCE可以说是唯一一个能够无缝对接Kubernetes网络的IaaS了。在实现上,GCE集群配置了高级路由功能,为每个虚拟机都分配了一个子网(默认是/24,即254个IP地址),所有发往该子网的网络流量都将直接路由给虚拟机而不需要经过网络地址转换。该子网中的IP地址是除分配给虚拟机的用于访问外网的“主”IP之外的IP地址,如果使用“主”IP地址访问外网需要经过网络地址转换。该子网中还存在一个名为cbr0的网桥(为了与docker0网桥区别开),该网桥只会对终点不是Kubernetes集群虚拟网络的外部网络流量进行网络地址转换。cbr0网桥可以通过Docker的–bridge参数传入。
GCE实现Kubernetes网络模型的流程如下所示:
-
首先,在启动Docker时附加自定义选项:DOCKER_OPTS="–bridge cbr0 --iptables=false"。
-
然后,使用SaItStack统一在每个工作节点上中创建cbr0网桥:
cbr0: container bridge.ensure: - cidr:{{ grains['cbr-cidr'] }} - mtu: 1460这样一来,Docker将从cbr-cidr子网的地址空间中为每个pod分配一个IP地址,这些IP地址在GCE集群范围(网络地址段为10.0.0.0/8)内都是可路由的。pod内的容器可以通过cbr0网桥访问集群内的其他容器和工作节点。但是,GCE本身对这些IP地址一无所知,因此不会在它们访问外网时进行网络地址转换。对于那些从pod内的容器发往外网(即非10.0.0.0/8的IP地址段)的流量,应用以下防火墙规则。
iptables -t nat -A POSTROUTING ! -d 10.0.0.0/8 -o eth0 -j MASQUERADE即将发往外网的IP包源地址修改成宿主机第一块网卡eth0的IP地址,这样就实现了pod IP地址的外部可路由性。
-
最后,还需要启用内核的IP包转发功能,以便内核能够为连接到网桥上的容器处理IP包。
sysctl net.ipv4.ip-forward=1完成以上所有步骤后,GCE集群中的pod就能够互相通信并访问互联网。
OpenVSwitch GRE/VxLAN方式
本节将简单介绍如何使用OpenVSwitch的tunnel方式建立跨宿主机pod的网络连接。OpenVSwitch ( OVS )的tunnel类型可以是GRE或VxLAN,在需要大规模的网络隔离的应用场景下,推荐使用VxLAN。这里我们使用Vagrant搭建的Kubernetes的例子,其网络拓扑图如图所示。
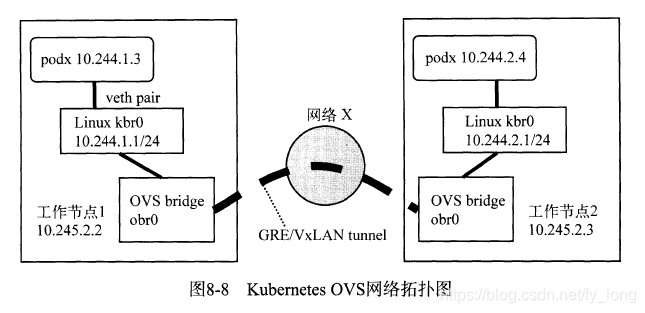
这种做法的具体实现细节如下:
- 将默认的docker0网桥用一个Linux网桥kbr0替换,并使每个工作节点获得一个IP地址空间为10.244.x.0/24的子网。工作节点上的Docker配置成使用kbr0网桥而不是docker0网桥。
- 创建一个OVS网桥(obr0)并作为一个端口添加到kbro网桥上。所有的宿主机上的OVS网桥通过GRE/VxLAN tunnel连接在一起,这样就实现了每个工作节点的网络互联。因此,所有跨宿主机的pod流量都会通过OVS网桥进入GRE/VxLAN tunnel。
- 每个OVS网桥上启用STP(生成树)模式来避免GRE/VxLAN tunnel的回路。
- 在每个工作节点上设置防火墙规则,允许所有目的地址是10.244.0.0/16,且从obr0网络接口进来的IP数据包。
其他实现
除了以上列举的几个实现外,还有其他一些网络方案能够用于实现Kubernetes的单pod单IP模型,例如Flannel, Weave, Calico等,有兴趣的读者可以自行实践,这里不再赘述。
kubernetes网络插件
Kubernetes通过一个名为NetWorkPlugin的接口定义了网络插件,系统运行时具体采用的网络插件名称可通过kubelet的启动参数–network-plugin以及–network-plugin-dir传递进来。从代码实现的角度来看,网络插件实质上就是Golang中的一个interface,提供了对pod网络进行配置的一些方法。目前kubelet一共支持3种网络插件模式,即Exec、 CNI以及kubenet。在默认的情况下,即启动kubelet组件时不指定network-plugin的参数,kubelet所使用的网络插件的名称就是"kubernetes.io/no-op",此时,用户需要按照上文所介绍的那样,根据情况选择合适的网络方案,提前设置好Kubernetes的基本网络模型。在pod创建的时候,kubelet会认为当前的环境已是扁平化的网络。如果使用了network-plugin,那么用户pod在创建的过程中,需要通过具体的network-plugin来设置pod的网络环境。
kubelet中的网络插件的接口主要声明了以下几个方法:
- Init:初始化插件,在其他方法被调用之前,初始化方法会被调用一次。
- Name:返回插件的名称。
- Status:得到容器的ipv4以及ipv6的网络状态。
- SetUpPod:在pod的infra器(上文中提到的pod的网络容器)创建之后被调用,此时Pod中的其他容器还没有启动起来,这个方法的主要功能是将pod中的infra容器加人到一个网络中。
- TearDownPod: pod的infra容器被删除之前,调用该方法,将pod的infra容器从网络中删除。
目前可以用来配置pod网络的network-plugin包括CNI, Exec, kubenet三种。
CNI ( Container Network Plugin )规范由CoreOS提出,并被Kubernetes采纳。当前containernetworking/cni项目实现了CNI接口规范。containernetworking/cni项目针对Linux container的网络配置提供了指定的接口以及具体的插件实现。宏观上来看,cni所做的很简单,就是将容器加人到一个网络中,并且保证容器之间的连通性。具体的实现方案由底层的不同cni插件来实现,有兴趣的读者可以参考github.com/containernetworking/cni,了解libcni的具体实现细节。
如果选择插件的方式为exec , kubelet会到指定的目录下去寻找可执行的二进制文件,这个二进制文件对于kubelet来说就是第三方插件,为了便于kubelet调用,对应的二进制插件所支持的命令必须包括init, setup, teardown, status,执行参数必须满足格式:<action> <pod_ namespace> <pod_ name> <docker_id_ of_infra_ container>。
kubenet插件的功能与–configure-cbr0的参数类似,它会创建一个名为cbr0的网桥,并且为每个pod创建一个veth pair,其中一端连接在cbr0网桥上,另一端会与pod相连并且被分配到一个ip地址作为pod的ip地址。