应用多项逻辑回归(Multinomial Logistic Regression, MLR)和线性判别分析((Linear Discriminant Analysis, LDA)来识别英文字母。
一.数据集
数据集来源:http://archive.ics.uci.edu/ml/datasets/letter+recognition
数据集data文件中共有17列20000行,其中第1列是英文字母,其余16列是对应的数字特征,共20000条数据。
- 将data文件转换为csv文件,如下图:

- 把letter列中的A-Z,26个字母转换为数字变量对应1-26。
- 割训练集和测试集,这里用的是7:3。
- 分别应用多项逻辑回归和线性判别方法训练。
- 输出训练的准确率和测试的准确率。
二. 结果
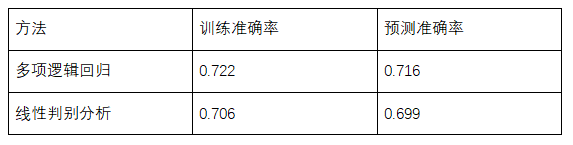
-
逻辑回归结果

-
线性判别分析结果

三.代码
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from sklearn.svm import SVC
#先将data文件转换为csv
path = "C:\\Users\\asus\\Desktop\\Python\\letter-recognition.data"
Cname = ['letter','1','2','3','4','5','6','7','8','9','10','11','12','13','14','15','16']
#Name of columns
data = pd.read_csv(path , header = None, names = Cname)
help(pd.read_csv) # help
m, n = data.shape #DataFrame的维数
print('m =', m)
print('n =', n)
print (data.head())
print (data.tail())
path = "C:\\Users\\asus\\Desktop\\Python\\letter.csv"
data.to_csv(path, na_rep = 'NA', index = False, header = True)
data = pd.read_csv(path)
data.columns
m, n = data.shape
print('m = ', m)
print('n = ', n)
print(data.letter.value_counts())
X = data.drop(['letter'], axis = 1)
y = data["letter"]
y = y.replace({'A':1,'B':2,'C':3,'D':4,'E':5,'F':6,'G':7,'H':8,'I':9,'J':10,
'K':11,'L':12,'M':13,'N':14,'O':15,'P':16,'Q':17,'R':18,'S':19,'T':20,'U':21,
'V':22,'W':23,'X':24,'Y':25,'Z':26}) x_train, x_test, y_train, y_test = train_test_split(X, y,
train_size = 0.7, random_state = 120)
#逻辑回归
lr = LogisticRegression()
lr.fit(x_train, y_train)
print ("\nLogisticRegression - Train accuracy:", round(accuracy_score(y_train,
lr.predict(x_train)), 3))
print ("\nLogisticRegression - Test accuracy:", round(accuracy_score(y_test,
lr.predict(x_test)), 3))
print ("\nLogisticRegression - Test Classification Report\n", classification_report(y_test,
lr.predict(x_test)))
#线性判别分析
ld = LinearDiscriminantAnalysis()
ld.fit(x_train, y_train)
print ("\nLogisticRegression - Train accuracy:", round(accuracy_score(y_train,
lr.predict(x_train)), 3))
print ("\nLogisticRegression - Test accuracy:", round(accuracy_score(y_test,
lr.predict(x_test)), 3))
print ("\nLogisticRegression - Test Classification Report\n",
classification_report(y_test, lr.predict(x_test)))
