上一篇介绍了ANR问题的相关知识,本篇介绍如何分析ANR问题。下面链接是我之前分析的一个ANR问题实例,实战与理论结合更容易理解。
https://blog.csdn.net/qq_43804080/article/details/99978439
如何分析ANR问题
与Native Crash或者Java Crash发生时简单明确的崩溃堆栈不同,分析ANR问题时需要通盘考虑,综合log中各方面的信息,找出是系统原因还是应用原因导致ANR。片面地分析应用程序堆栈或者CPU信息通常都只能得出令人啼笑皆非的错误结论。
在一份标准的slog中,通常有以下文件可用于分析ANR的原因:
system.log 包含ANR发生时间点信息、ANR发生前的CPU信息,还包含大量系统服务输出的信息。
main.log 包含ANR发生前应用自身输出的信息,可供分析应用是否有异常;此外还包含dalvik输出的GC信息,可供分析内存回收的速度,判断系统是否处于低内存或内存碎片化状态。
event.log 包含AMS与WMS输出的应用程序声明周期信息,可供分析窗口创建速度以及焦点转换情况。
kernel.log 包含kernel打出的信息,LowMemoryKiller杀进程、内存碎片化或内存不足,mmc驱动异常都可以在这里找到。
trace.log 包含ANR发生时的应用堆栈信息、PS信息和meminfo信息。根据定制需要,还可以包含ANR发生时的system_server堆栈、SurfaceFlinger堆栈、文件句柄状况等信息。
tomestone 有些应用的ANR是由于之前应用已经崩溃导致的,需要注意以下在ANR发生前如果在tomestone文件夹中此应用已经发生了Native Crash,那么ANR很有可能就是由此导致的。
Dropbox 该文件会把snapshot中的信息备份一份,如果因为某些原因导致snapshot文件丢失,可以尝试在dropbox中寻找ANR发生时的堆栈信息。
System.log中的信息
ANR第一时间点
在分析ANR时首先要寻找的就是ANR的第一时间点。参见以下log,可以看到第一个黄色标记处有“Input event dispatching timed out sending to …”字样,这就是ANR发生的第一时间点。在明确了这个时间点后,才能根据不同ANR的类型分析在超时时间段内系统和应用有什么异常信息。例如广播超时需要分析第一时间点前10秒(后台广播60秒)的广播队列信息;窗口转换超时需要分析第一时间点前5秒的窗口焦点转换过程和event.log中的窗口生命周期信息。通过ANR第一现场的时间和ANR类型,可以找到出错时间段,压缩需要分析的时间范围。
“ANR in”信息
通常分析ANR问题时第一件事就是打开system.log,找到“ANR in”信息,然后大致了解一下发生ANR的是什么应用,CPU占用情况如何。接下来会详细讲解这段log中包含的诸多信息。
需要特别注意的是“ANR in”并不是ANR发生的第一时间点。它是在输出ANR应用堆栈和主要系统服务堆栈、ps、meminfo等信息后,ANR进程马上就要被杀死时才被输出的。如果ANR发生时输出的debug信息较多,或者当时的CPU或I/O资源比较紧张,“ANR in”可能在ANR发生的第一时间点之后10秒甚至20秒才被输出。
这部分log中的信息主要有:
1、 ANR进程名称与PID:进程名和PID是找到发生ANR的应用的主要依据,但是有两种例外情况。如果PID为0,说明应用在发生ANR之前就已经被LowMemoryKiller杀死或者已经崩溃。这种情况下应用程序无法处理广播或按键消息,因此出现ANR。
由于原生Bug,窗口获取焦点超时导致的ANR可能会报告在错误的应用上,这主要是因为焦点应用和焦点窗口不同步导致的,请参考1.2.2节。
2、 ANR类别:可以据此判断ANR超时时间,决定需要回溯多久查找ANR的原因。比如用户输入时间处理超时回溯5秒,广播超时回溯10秒。
3、 CPU平均负载:表示一、五、十分钟内有多少进程在等待CPU调度。单核手机一般不超过10,四核手机不超过14。如果CPU负载太高应用程序主线程长时间得不到CPU时间片就会发生ANR甚至Watchdog重启。
4、 CPU统计时间段:ago和Later分别表示 ANR 发生前后一段时间内的 CPU 使用率,并不是某一时刻的值。需要注意的是,这个统计本身也会收到CPU负载高的影响,可能无法统计到ANR发生之前的CPU状况。
5、 进程CPU占用率:单核手机上,如果进程CPU占用率较高,且截取到的是ANR发生之前的CPU情况,那么ANR可能与CPU占用率有关。
6、 页错误数量:分为次要页错误和主要页错误,分别表示内存与缓存的命中情况。页错误过高说明内存频繁换页,会导致分配内存与GC速度显著变慢。
7、 新增进程:ANR发生前出现大量的新增进程说明可能广播风暴或密集的延时重启。
8、 总CPU占用率:在单核设备上可以保证准确,在支持热插拔的设备上一般不准确。
9、 线程CPU占用率:可配合snapshot中的应用调用堆栈分析单个进程CPU占用率高问题。
在分析System.log时,应当注意应用发生ANR之前是否出现了OutOfMemory错误、Java Crash或者Native Crash。此外还应当注意应用相关的服务是否出现了异常,比如acore被LMK杀死contact就会发生ANR,camera handler发生崩溃会导致camera发生ANR。
Main.log中的信息
Mian.log中主要是应用输出的信息,相对System.log而言会比较散乱。从中挖掘ANR的关键信息需要一定的耐心。在分析时应当关注以下几个方面。
1、反复打出相同log:如果应用CPU占用率很高,且反复打出相同log,很可能是出现死循环。
2、 应用输出的log是否存在异常:如下例,Camera尝试分配26214400 Byte显存,但是从16:42:16开始申请直到16:42:27才分配完毕,这段时间主线程一直被阻塞,因此发生ANR。在应用程序容易出现性能问题的关键点适度添加log,对查找ANR问题非常有帮助。
3、 是否有多个应用都打出相同的异常信息:有时一些ANR问题是由共同的底层问题导致的。如下例,每次ANR前log中都会报出io异常,且多个应用都有相同现象。分析后发现问题出现在kernel中的mmc驱动。
4、 GC时间是否过长:如果GC花费的时间占据了ANR超时时间的一半以上,就需要考虑是由于系统内存极端不足或内存碎片化导致ANR。注意计算GC时间时仅能计算超时时间段内ANR应用主线程GC时间,再加上WAIT_FOR_CONCURRENT_GC的时间。
2.3 调用堆栈中的信息
AMS会抓取ANR发生瞬间应用程序全部线程的调用堆栈,供开发人员分析阻塞位置。
很多人看调用堆栈时都会首先去找“held by”,看看是不是死锁。但ANR并不一定由死锁造成,如何从千奇百怪的堆栈信息中判断ANR的原因呢,主要应注意以下几个方面。
2.3.1 线程状态
1、 线程状态:作为运行在Linux上的系统,Android对标准POSIX本地线程状态进行了进一步的封装,使之可以更准确地描述虚拟机内部的状态。参见下表:
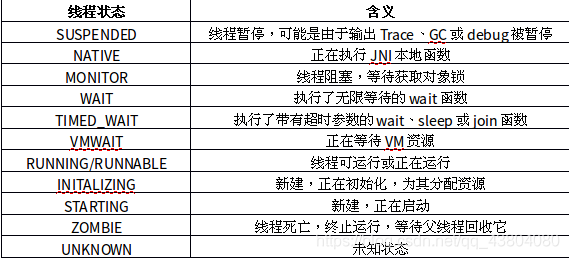
SUSPENDED状态的含义是线程暂停,但是绝不能看到应用程序主线程处于SUSPENDED,就说是系统/Dalvik/CPU/内核/底层将应用主线程暂停导致ANR。必须依据调用堆栈,具体问题具体分析。
线程处于SUSPENDED有三种原因:正在运行的线程需要输出调用堆栈、正在GC、或者被调试程序暂停。
当输出一个线程的调用堆栈时,如果线程正处于NATIVE、MONITOR、WAIT、TIMED_WAIT、VMWAIT这样的安全状态时、可以直接输出线程的调用堆栈。这是由于处于上述状态的应用并没有在运行,而是在等待某个锁或者远程调用返回。而处于RUNNING/RUNNABLE状态的线程处于一种不安全的状态,必须先将其挂起,转为SUSPENDED才能输出调用堆栈。这就好像不能给一辆行驶中的卡车换轮胎,必须先把卡车停下来。
如果线程是由于正在GC而处于SUSPENDED状态,那么线程的调用堆栈中就一定能显式地看到GC相关的方法,如下面例子中的黑体字。系统内存紧张或内存碎片化时,GC速度慢确实会导致ANR,但主线程直接阻塞在GC上比较少见。在实际操作中应当结合main.log中dalvik打出的GC时间信息分析,如果发生ANR的应用在超时时间段内GC花费的时间之和超过2.5秒,就需要怀疑是GC太慢导致ANR。
此外,调试程序时设置断点也会使线程处于SUSPENDED状态,这时堆栈信息会显示dsCount=1。但调试程序时不会报告ANR,对此种情况不再赘述。
2.3.2 调用堆栈状态
由应用原因引发ANR的原因通常可分为四大类:死锁、阻塞、死循环、低性能。
2、 执行Binder调用时的调用堆栈
3、 主线程被上锁的调用堆栈
有极少数应用如Gallery3D和Camera会给自己的主线程上一个无限等待的锁,在子线程完成特定操作后由子线程解锁主线程。理论上讲子线程应当很快解锁,但在系统负载高的时候很容易导致ANR。
这种情况下snapshot中可见主线程调用堆栈处于Wait状态,主线程held by tid=1自己等待自己。解决这个问题需要在子线程中添加log,检查解锁不及时的原因。
需注意仅有主线程给自己上无限等待锁才会导致ANR,子线程这样做是常见操作,不会导致ANR。
4、 主线程阻塞的调用堆栈
除了各种死锁之外,阻塞也是导致ANR的一个重要原因。如下例,应用程序主线程正在进行IO操作,获取SD卡剩余空间但是向JNI层的调用却没有返回。如果出现这样的调用堆栈,且CPU信息中显示IOWait非常高,就要考虑是由I/O读写速度慢导致的ANR。此例中结合Kernel.log发现是由mmc驱动错误影响I/O速度阻塞主线程导致ANR。
5、出现死循环的调用堆栈
如果在程序设计中对输入参数合法性检查不严格,代码(特别是字符串拆分操作)可能会陷入死循环。这类问题的特征在于应用程序用户空间的CPU占用率很高,往往接近100%。调用堆栈处于SUSPENDED状态(这说明在开始输出堆栈前它一直处于RUNNING)。此时就需要参照调用堆栈分析代码,在怀疑发生死循环的位置添加debug信息检查输入参数合法性,待重现后找到死循环的原因再加以修改。
6、 低性能的调用堆栈
就以往项目的经验而言,前期由应用死锁、阻塞导致的ANR较多,项目中后期问题主要集中在性能上。由于手机内存、I/O性能存在瓶颈,或是程序算法或流程设计不合理等原因,在压力测试中会出现很多由性能问题导致的ANR。当发生这类问题时,程序并不会一直阻塞在一个特定位置,而是非常缓慢地前行。主线程看上去和阻塞很相似,但通常会停在一个被频繁调用的原生公共模块,通常是窗口绘制或布局相关的方法上。
低性能问题通常比较难以判断,应当主要关注以下几个特征。
1、 meminfo中剩余内存在20M以下
2、 System.log中发生ANR的应用Kernel空间CPU占用率非常高
3、 system.log中的主要页错误超过600次/秒
4、 main.log中发生ANR的应用的GC速度大于200ms
5、 event.log中创建应用进程所需时间超过1秒,窗口生命周期个方法执行迟缓
6、kernel.log中ANR时间点附近频繁调用LowMemoryKiller杀死进程
7、kernel.log中有内存碎片log
8、一份log中多个模块反复出现ANR,但是出现问题时的堆栈各不相同
分析性能问题应注意避免几种错误做法:
1、 只看调用堆栈:程序缓慢运行时抓取的调用堆栈经常会“恰好”停在一个被频繁调用调用的公共模块上,有点像玩击鼓传花,停在哪行代码上并不意味这行代码阻塞了整个程序的运行。不能看到调用堆栈在进行窗口布局就说程序卡在WMS里,看到调用堆栈正在绘制字体就说程序卡在libskia库里面。阻塞只是导致ANR的原因之一,而不是全部。
7、 NativePollOnce调用堆栈
有时trace文件会输出一个NativePollOnce调用堆栈,这是一个正常的堆栈,当应用程序处于空闲状态消息循环等待下一个输入事件时就会显示这样的堆栈。绝对不是“主线程阻塞在消息循环上”,更不是“阻塞在Framework里”。
出现这个现象就要考虑ANR可能不是由于主线程阻塞导致,可能是由Framework或系统原因导致ANR。比如WMS焦点切换出现问题或者Kernel冻结用户空间等等。
Event.log中的信息
Event.log中主要是ActivityManager和WindowManager打出的信息。在分析由性能问题导致的ANR时,应用程序可能并没有死锁或者阻塞,而是在OnCreate中浪费4秒,留给OnResume执行的时间已经不够了。分析这类问题时就不能简单地看应用程序主线程堆栈停在哪里,而是要分析窗口生命周期各个方法的执行时间,找到运行迟缓的部分。Event.log中需要关注的信息主要有:
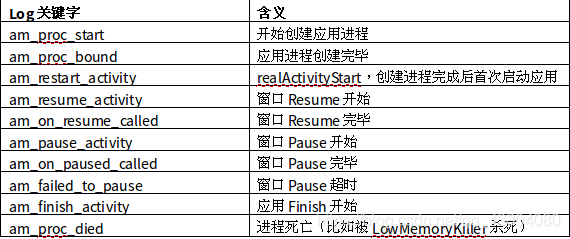
在掌握了以上窗口生命周期log后,就可以从event.log中分析究竟是哪一个过程慢导致ANR发生,见下例。
1、创建进程慢:正常情况下启动应用创建进程所需的时间应当是300~500ms,在系统内存碎片化分配不出连续内存段或者CPU变频不正常时进程创建速度就会明显变慢,下面log中am_proc_start到am_proc_bound一共花费了4.5秒才创建出一个进程。这就可以排除应用问题,转而查找底层原因。
2、窗口创建缓慢:log中可见,进程启动速度正常,但是用了6秒才完成Resume走到am_on_resume_called。如果单一应用反复出现此现象,就需要在应用的声明周期方法中分段添加log查找执行缓慢的代码;如果多个应用随机出现此现象,就需要对系统整体性能进行分析,查找阻塞点。
3、窗口Pause慢:log中可见,SlideshowEditActivity在05:14:57就已经收到AMS的am_pause_activity命令,但直到05:15:08才完成am_on_paused_called走完Pause流程。对于单一应用而言,前一个窗口Pause不下去新窗口就没法Resume出来,焦点长时间处于null状态就会触发窗口焦点转换ANR。这个例子需要应用检查窗口Pause慢的原因。
Kernel.log
Kernel.log主要包含HAL层和Kernel层的信息,对于平时惯于分析system.log和mian.log的程序员而言,其中的信息会比较难于理解。其实在分析ANR过程中,大多数时候仅需要注意以下几个基本点即可。
1、 LowMemoryKiller:Android系统的内存管理原则是,允许启动尽可能多的应用,当内存不足时再由Kernel中的LowMemoryKiller根据特定算法杀死后台应用,为前台应用释放内存。
小内存设备上由LowMemoryKiller导致的ANR通常有两种,一种是应用刚刚收到一个广播消息就被LMK杀死,消息无人处理导致广播超时发生ANR。因此分析广播超时ANR时需要注意在超时时间段内应用是否被LMK杀死。针对此问题可以修改AMS,当报出广播超时ANR前首先检查应用是否已经被杀死,如果应用已死就不再报出ANR。
另一种是LMK杀死了前台应用依赖的后台服务或Provider,比如杀死acore会影响Contact,杀死CameraHandler等等。
2、 内存碎片或内存耗尽:当小内存设备高强度运行数个小时之后,内存会逐渐碎片化,较大的连续内存段越来越少,剩下的都是4kB、16kB的零碎内存段。这时如果应用程序需要分配一个32kB的连续内存段,Kernel就只能尝试调用LMK杀死一些后台进程来释放内存。如果释放内存花费时间过长就会导致等待内存分配的应用发生ANR。如下利:sh尝试分配order=2即4Kb*2^2=16kB的连续内存段,但此时内存已经碎片化,只有4kB和8kB的内存可用了。如果在ANR发生前后Kernel.log中出现了大量“invoked oom-killer”信息,就要考虑调整LMK回收策略更积极地释放内存,以减少由于系统性能问题导致ANR的概率。
3、一些特殊异常信息:就像上层应用和服务会发生Java Crash和Native Crash,Kernel中同样会出现各式各样的崩溃和异常。在分析ANR时需要注意在超时时间段内Kernel中的log有没有明显的异常信息,像下面两个例子分别是由mmc驱动错误和UBIFS assert failed导致ANR。需要指出的是,查找由Kernel引发的ANR需要较多的实践经验,千万不能在kernel.log中看到一段奇怪的log就认为它是ANR的原因,这样不仅不利于及时解决问题,还会给Kernel增加额外的工作量。
trace.log中的信息
根据不同项目的定制情况不同,trace还能输出很多ANR发生时的系统状态信息,如纵内存信息、连续内存段数量、线程信息、文件句柄和磁盘使用量、binder状态、wakelock分配情况等等。其中和分析ANR相关的主要是内存信息和线程信息这两部分。
1、 内存信息
内存信息是指用cat /proc/meminfo指令读出的内核信息,仅需要关注前4项。
MemTotal: 403784 kB 所有可用内存大小,即物理内存减去内核占用、预留内存和显存
MemFree: 3068 kB 完全空闲的内存
Buffers: 3140 kB 用于文件缓存的内存
Cached: 43772 kB 被高速缓冲存储器使用的内存大小
在计算剩余内存时应该用MemFree+Cached,根据经验值,如果两者之和小于20M,就是说明系统处于极低内存状态,应用很可能出现由低内存导致的ANR。
2、 线程信息
ANR发生时AMS会通过ps -t命令输出线程的状态信息,需要注意分析进程是否启动了数量异常的子线程,比如Launcher和Gallery3D出现过启动了500+子线程的例子;发生ANR时各个应用的内存使用量;是否启动了一些异常的进程,比如同时启动5个Monkey进程一起跑。
此外还应注意线程的运行状态,其中S、R都是PS中常见的正常线程状态。需要特别注意的是D状态,在D状态说明进程处于不可中断的睡眠状态,此时它不会响应任何外部信号,甚至无法用Kill杀死进程。
处于此状态的线程通常是在等待I/O,比如磁盘I/O、网络I/O或者外设I/O。线程短时间处于D状态是正常现象,但是在I/O瓶颈较严重的手机上如果应用连续几秒或者更长时间都处于D状态无法响应外部信号,就会导致ANR。

