一、浏览器架构
1、User Interface 用户界面
主要提供用户与Browser Engine交互的方法。其中包括:地址栏(address bar)、向前/退后按钮、书签菜单等等。浏览器除了渲染请求页面的窗口外的所有地方都属于The User Interface
2、Browser Engine 浏览器引擎
协调(主控)UI和the Rendering Engine,在他们之间传输指令。 提供对The Rendering Engine的高级接口,一方面它提供初始化加载Url和其他高级的浏览器动作(如刷新、向前、退后等)方法。另一方面Browser Engine也为User Interface提供各种与错误、加载进度相关的消息。
3、Rendering Engine 渲染引擎
为给定的URL提供可视化的展示。它解析JavaScript、Html、Xml,并且User Interface中展示的layout。其中关键的组件是Html解析器,它可以让Rendering Engine展示差乱的Html页面。 值得注意:不同的浏览器使用不同的Rendering Engine。例如IE使用Trident,Firefox使用Gecko,Safai使用Webkit。Chrome和Opera使用Webkit(以前是Blink)
4、Networking 网络
基于互联网HTTP和FTP协议,处理网络请求。网络模块负责Internet communication and security,character set translations and MIME type resolution。另外网络模块还提供获得到文档的缓存,以减少网络传输。为所有平台提供底层网络实现,其提供的接口与平台无关
5、JavaScript Interpreter JS解释器
解释和运行网站上的js代码,得到的结果传输到Rendering Engine来展示。
6、UI Backend 显示后端
用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口
7、 Data Storage 数据持久层
属于持久层,浏览器需要在硬盘中保存并管理类似cookie、书签、偏好设置等各种数据
8、 XML Parser XML解析器
XML解析器可以将XML文档解析成文档对象模型(Document Object Model,DOM)树。 XML解析器是浏览器架构中复用最多的子系统之一,几乎所有的浏览器实现都利用现有的XML解析器,而不是从头开始创建自己的XML解析器
这里可能会产生一个疑问:功能相似的HTML解析器和XML解析器为什么前者划分在渲染引擎中,后者作为独立的系统?
原因:XML解析器对于系统来说,其功能并不是关键性的,但是从复用角度来说,XML解析器是一个通用的,可重用的组件,具有标准的,定义明确的接口。相比之下,HTML解析器通常与渲染引擎紧耦合。
注:如下是Chrome架构的简单示意图

Chrome 架构图
二、浏览器工作流程
1、页面加载过程
在介绍浏览器渲染过程之前,我们简单介绍下页面的加载过程,有助于更好理解后续渲染过程。
- 浏览器根据 DNS 服务器得到域名的 IP 地址
- 向这个 IP 的机器发送 HTTP 请求
- 服务器收到、处理并返回 HTTP 请求
- 浏览器得到返回内容
- 返回内容其实就是一堆 HMTL 格式的字符串。接下来就是浏览器的渲染过程。
2、渲染引擎的工作流程
1、HTML(XML)解析器
解析HTML(XML)文档,主要作用是将HTML(XML)文档转换成DOM树
2、CSS 解析器
CSS 解析是把 CSS 规则应用到 DOM 树上,为DOM中的各个元素添加显示相关属性的过程,构建CSSOM tree
3、JavaScript 解释器
使用JavaScript可以修改网页的内容、CSS规则等。JavaScript解释器能够解释JavaScript代码,并通过DOM接口和CSSOM接口来修改网页内容、样式规则,从而改变渲染结果
4、Render Tree 渲染树
渲染引擎将DOM tree(元素对象)与CSSOM tree(样式规则)进行结合从而生成Render tree(渲染树)
5、Layout 布局
布局则是针对渲染树,计算其各个元素的大小、位置等布局信息
6、Painting 绘图
使用图形库将布局计算后的渲染树绘制成可视化的图像结果(绘制页面像素信息)
7、Display 显示
浏览器将各层的信息发送给GPU,GPU将各层合成,显示在屏幕上
注1:渲染引擎的另一种图示
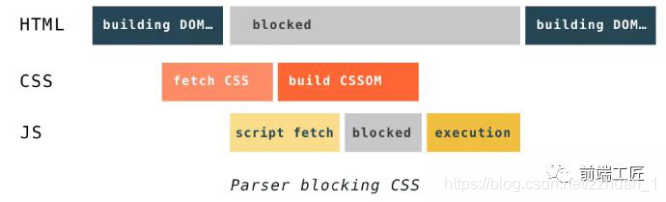
注2:浏览器如果渲染过程中遇到JS文件怎么处理?
渲染过程中,如果遇到 <script>就停止渲染,执行 JS 代码。因为浏览器渲染和 JS 执行共用一个线程,而且这里必须是单线程操作,多线程会产生渲染 DOM 冲突。JavaScript的加载、解析与执行会阻塞DOM的构建,也就是说,在构建DOM时,HTML解析器若遇到了JavaScript,那么它会暂停构建DOM,将控制权移交给JavaScript引擎,等JavaScript引擎运行完毕,浏览器再从中断的地方恢复DOM构建。
也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件,这也是都建议将 script 标签放在 body 标签底部的原因。当然在当下,并不是说 script 标签必须放在底部,因为你可以给 script 标签添加 defer (延迟加载)或者 async(一步下载) 属性
参考链接(英文):《Inside look at modern web browser》 https://developers.google.com/web/updates/2018/09/inside-browser-part1
参考链接(中文):《图解浏览器的基本工作原理》 https://zhuanlan.zhihu.com/p/47407398
参考链接:《浏览器的工作原理:新式网络浏览器幕后揭秘》 https://www.html5rocks.com/zh/tutorials/internals/howbrowserswork/
参考链接:《一文看透浏览器架构》https://www.cnblogs.com/qcloud1001/p/10431325.html
参考链接:《现代浏览器工作原理》http://chuquan.me/2018/01/21/browser-architecture-overview/
参考链接:《浏览器页面渲染机制-前端原理剖析》https://blog.csdn.net/zzhuan_1/article/details/90199891
参考链接:《web页面渲染解析原理》https://blog.csdn.net/zuiziyoudexiao/article/details/77171227
end
