突发奇想
先说说我为什么要写这篇文章,在这之前,我遇到了一个问题,就是复制不了PDF的文字内容,而我偏偏又想获取到。
我尝试了很多办法,先是将PDF转成Word文档,这样就可以从文档中把内容复制出来了,但是这些格式转换的工具基本都收费,自然就不用再考虑了。
我还想过将要复制的文字部分截图下来,然后发到手机上,通过手机QQ的提取文字内容功能将文字提取出来然后复制:
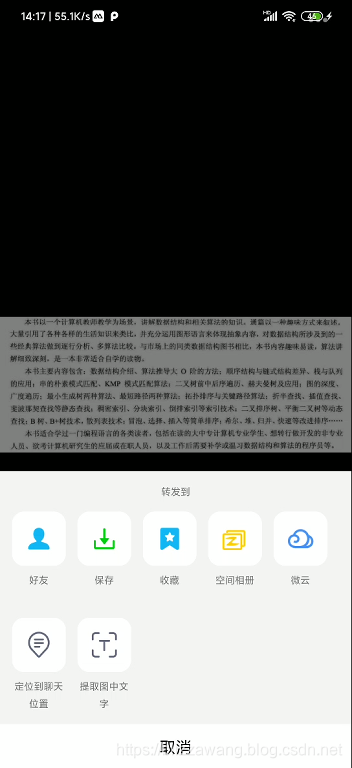

效果很好,也实现了我的需求,但是未免太麻烦了,要截图,还要发到手机上,于是我陷入了深深的思考,我能不能自己实现这样的功能呢?
学编程为了什么,就是解决问题嘛,所以,我考虑了一下,QQ是如何实现这个功能的。毫无疑问,是文字识别,通过一张图片,然后识别图片里的文字,最后显示出来。
准备工作
搞清楚原理之后,就要解决该如何实现文字识别呢?自己实现显然不现实,自己也不会啊,在百度上搜索了一下,我决定使用百度提供的文字识别API。为了使整个过程变得简便,最终决定使用Python语言实现整个过程。
申请百度识别API
我们先来申请一下百度的文字识别API。
百度搜索百度AI开放平台:
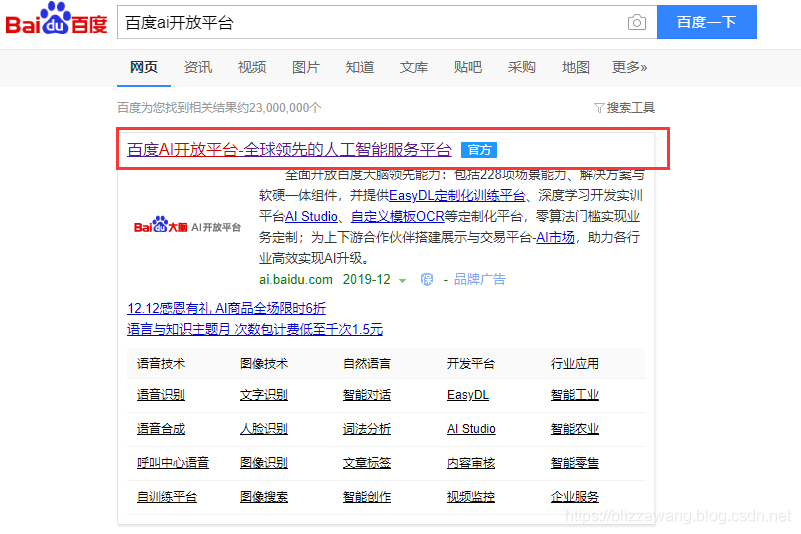
点第一个官方链接,进去后点击控制台:
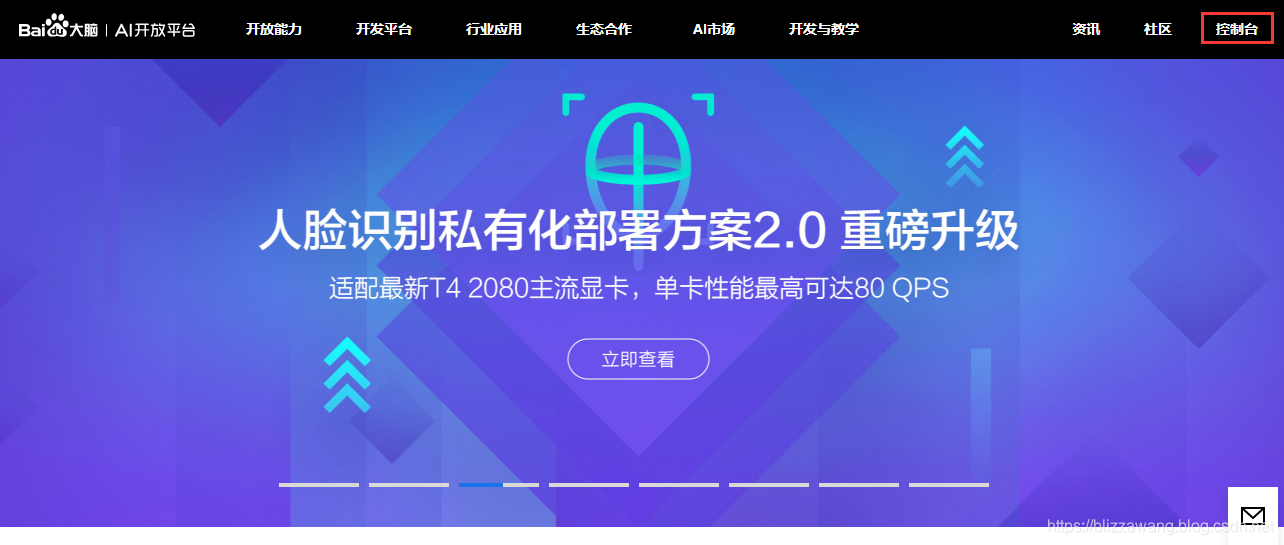
然后会让你注册,有账号的话登录就可以了,登录之后就可以看到控制台,点击左侧导航栏中的文字识别:
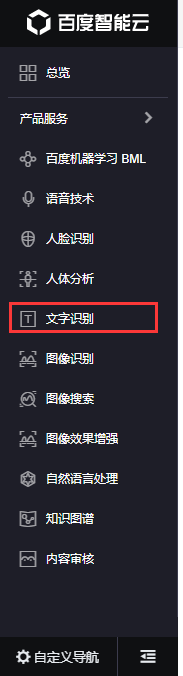
然后点击创建应用,信息随便填一填就好了,我这里已经创建好了:
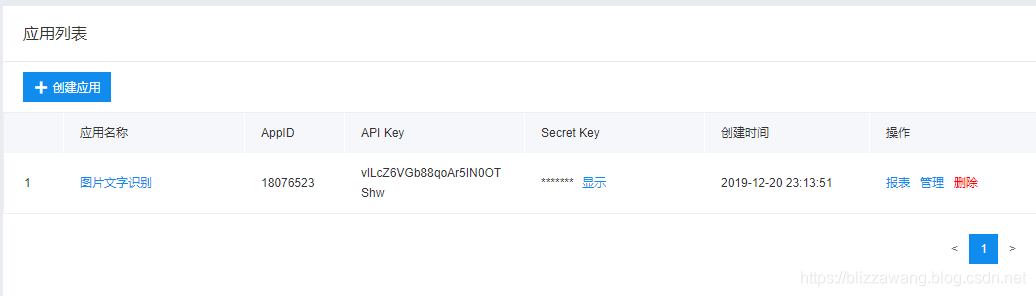
创建好了就先放着,这三个数据到后面是有用的。
模块介绍
在写代码之前,我得先介绍一下要使用的模块,先来说说我想实现的功能:
首先通过截图(QQ截图、微信截图、电脑自带的截图工具都可以)截取需要的文字内容,然后将图片保存到电脑中,接着通过文字识别把图片中的文字进行提取,最后输出。
先给大家看看效果:
大致功能就是这样,大家也可以根据自己的想法进行拓展。
keyboard
先来介绍一下keyboard模块,因为我们要直接获取到截图的图片,肯定不能自己去保存,那样太麻烦,我们要截图完成后自动将图片进行保存,所以我们先监听到键盘的输入。
先安装keyboard模块,在cmd窗口执行指令:
pip install keyboard
来体验一下这个模块。
import keyboard
keyboard.wait(hotkey = 's')
print("键盘按下了's'")
通过该模块的wait函数可以等待键盘输入,函数参数表示等待的热键,意思是说当执行该程序后,程序会一直等待,直到你键盘按下了’s’程序才会继续执行。
我们运行该程序,然后按下’s’,运行结果如下:
键盘按下了's'
学会了这个,接下来的事情就很简单了,我这里用的是QQ的截图,快捷键为:Ctrl + Alt + A,所以我们要监听该快捷键,代码如下:
import keyboard
print("开始截图")
keyboard.wait(hotkey = 'ctrl+alt+a')
print("键盘按下了'ctrl+alt+a'")
keyboard.wait(hotkey = 'enter')
print("键盘按下了'enter'")
print("结束截图")
运行之后,我们正常执行一次截图操作,看下运行结果:
开始截图
键盘按下了'ctrl+alt+a'
键盘按下了'enter'
结束截图
这样监听截图操作就完成了。
ImageGrab
这是一个非常优秀的图像处理库,我们通过它来保存截取的图片,先安装一下该模块:
pip install Pillow
这是PIL(全程:Pillow)包下的一个模块,所以我们把Pillow包下载好,要用到该模块的一个函数,代码如下:
import keyboard
from PIL import ImageGrab
print("开始截图")
keyboard.wait(hotkey = 'ctrl+alt+a')
print("键盘按下了'ctrl+alt+a'")
keyboard.wait(hotkey = 'enter')
print("键盘按下了'enter'")
# 保存剪切板快照
image = ImageGrab.grabclipboard()
image.save('screen.png')
print("结束截图")
使用也很简单,先通过keyboard模块的wait函数等待我们截图,当按下enter后截图结束,使用ImageGrab模块的grabclipboard函数将截图获取出来,该函数的功能是抓取当前剪切板的快照,然后封装成image返回,接着用image的save函数进行保存,若只写文件名,则图片将保存在当前目录。
现在我们运行一下项目,然后随意截取一张图片:

虽然这样实现了截图的保存,但细心的同学肯定能发现,第一次截图的时候报错了,然而第二次截图的时候,保存的却是第一次截图的内容,这是为什么呢?
这是因为grabclipboard函数有一个缓存的问题,操作太快,有时候它就会读取上一次的内容,因为第一个没有读取到图像,所以报错了。
问题找到了,该如何解决呢?既然是操作太快导致读取了缓存,那就让它慢一点呗,我们加上一个时间的延迟就可以了,代码修改如下:
import keyboard
from PIL import ImageGrab
import time
print("开始截图")
keyboard.wait(hotkey = 'ctrl+alt+a')
print("键盘按下了'ctrl+alt+a'")
keyboard.wait(hotkey = 'enter')
print("键盘按下了'enter'")
time.sleep(0.1) # 因为读取截取内容会有一个延迟,导致读取到的是上一次的截图,这里我们主动延迟
# 保存剪切板快照
image = ImageGrab.grabclipboard()
image.save('screen.png')
print("结束截图")
这里在保存剪切板快照之前进行了0.1秒的延迟,就能很好地解决这个问题,使用sleep函数需要导入time模块,下载模块指令:
pip install time
到这里,截取的图片就保存完毕了。
baidu-aip
下面介绍百度的文字识别API。
关于文字识别API的介绍,大家可以查看百度官方的技术文档,我这里只介绍需要使用到的。
AipOcr
AipOcr是OCR的Python SDK客户端,为使用OCR的开发人员提供了一系列的交互方法。
from aip import AipOcr
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
这三个数据都在之前的应用管理里面呢,粘贴进来就可以了。
这样便创建了客户端,还可以对客户端进行一些配置,比如连接的超时时间等等,这里就不做配置了。
通用文字识别
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('example.jpg')
这段代码是从官方文档中复制过来的,意思很简单,get_file_content函数通过一个图片的路径将图片转换成二进制数据进行返回,这里的image即为指定图片的二进制数据,有了二进制数据后,就能进行文字识别了。
- basicGeneral
- basicAccurate
这两个方法都可以进行文字识别,不过basicAccurate方法是高精度版本的,具体用哪个方法看大家喜好。
下面来测试一下我们能否成功提取到图片文字,比如下面的一张图片:

from aip import AipOcr
# 调用百度API识别图片内容
APP_ID = '18076523'
API_KEY = 'vlLcZ6VGb88qoAr5IN0OTShw'
SECRET_KEY = '8KzHr2AvEREYGGwdwIMFZSwTUoPB6LC4'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY) # 生成一个对策
# 获取图片的二进制数据
def get_file_content(filePath):
with open(filePath,'rb') as fp:
return fp.read()
image = get_file_content('screen.png')
# 调用文字识别(高精度版)
text = client.basicAccurate(image)
print(text)
运行结果:

成功获取到文字内容,我们先来处理一下这些数据。
log_id我们不管,words_result_num应该是识别的文字数量,它把图片中的文字拆分成了几个小块,这里一共四块,文字内容存放在列表words_result中,每个列表由一个字典组成,文本内容的键为words,所以接下来取出文本内容就很简单了:
from aip import AipOcr
# 3、调用百度API识别图片内容
APP_ID = '18076523'
API_KEY = 'vlLcZ6VGb88qoAr5IN0OTShw'
SECRET_KEY = '8KzHr2AvEREYGGwdwIMFZSwTUoPB6LC4'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY) # 生成一个对策
# 获取图片的二进制数据
def get_file_content(filePath):
with open(filePath,'rb') as fp:
return fp.read()
image = get_file_content('screen.png')
# 调用文字识别(高精度版)
text = client.basicAccurate(image)
# 处理返回的数据
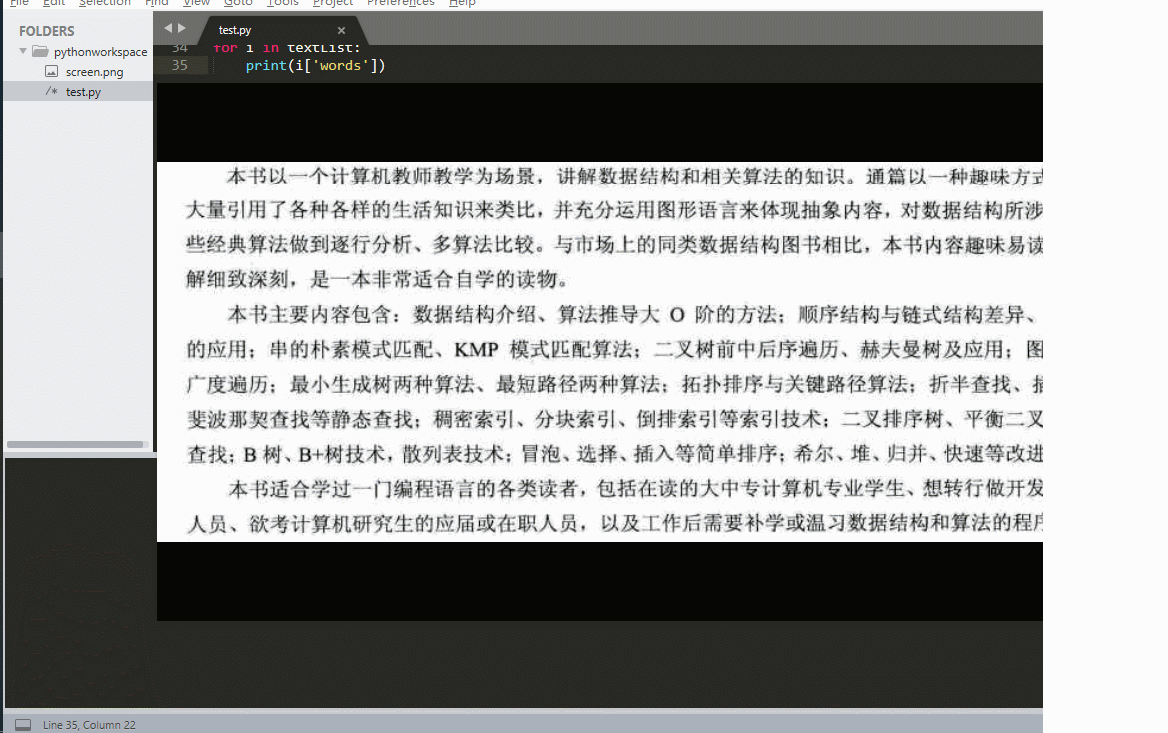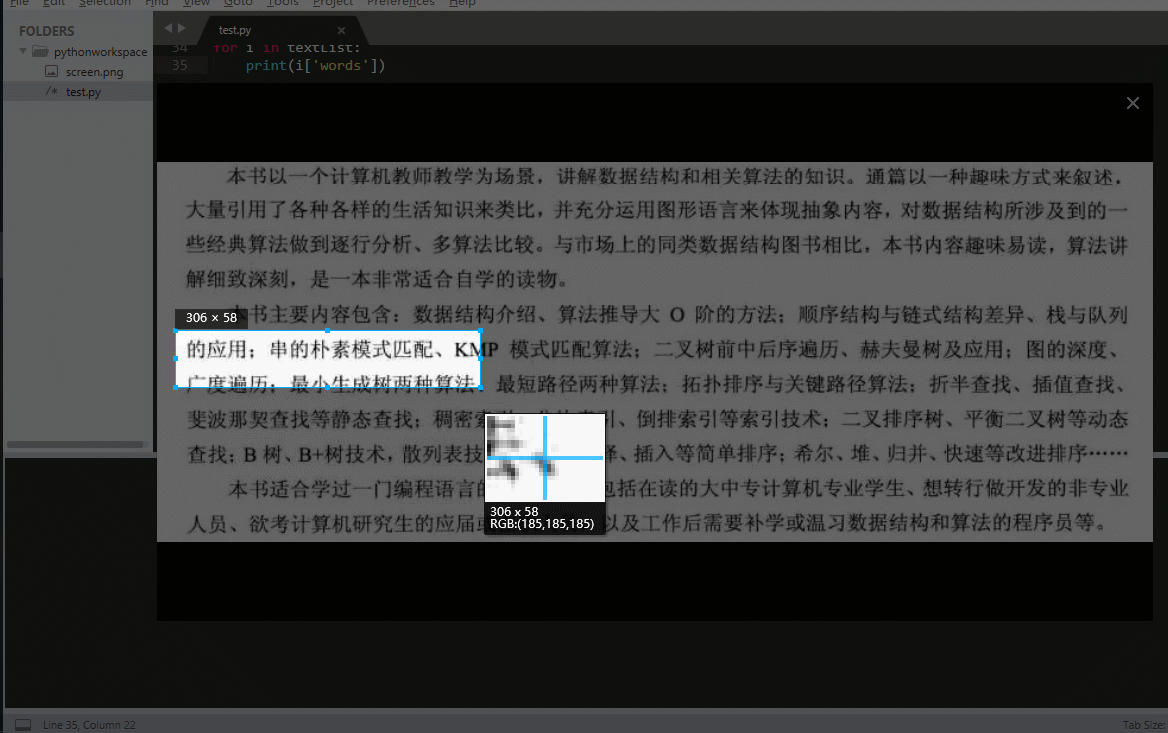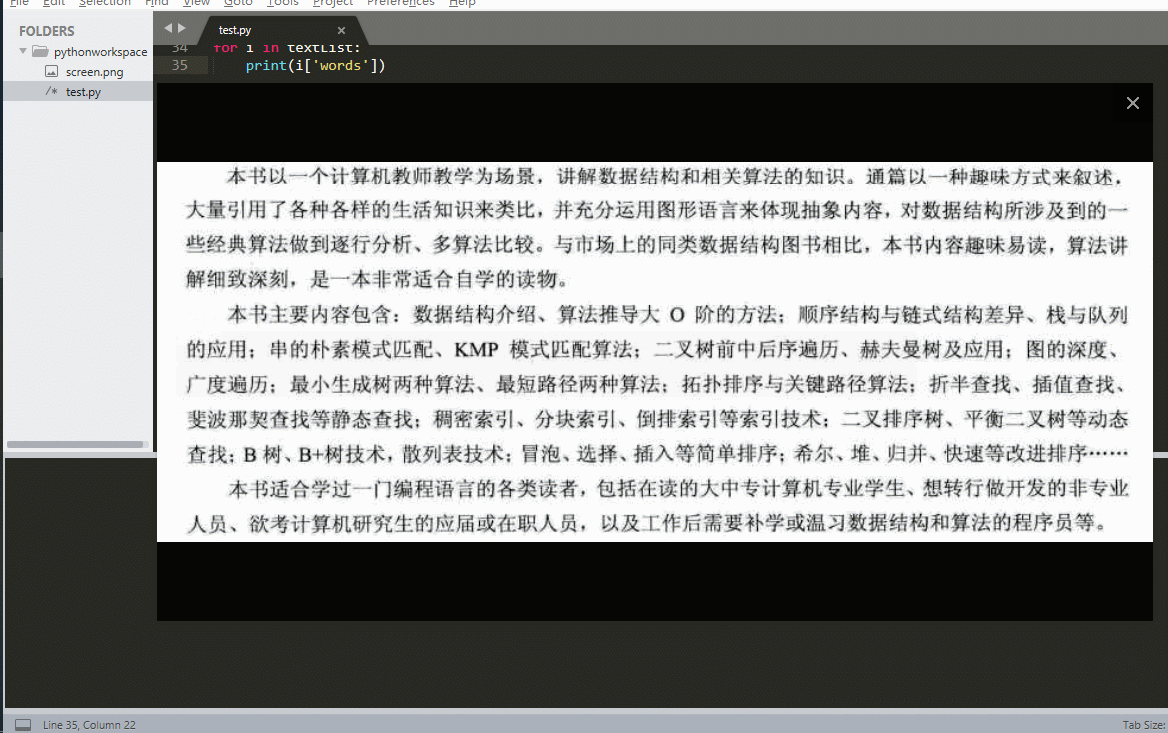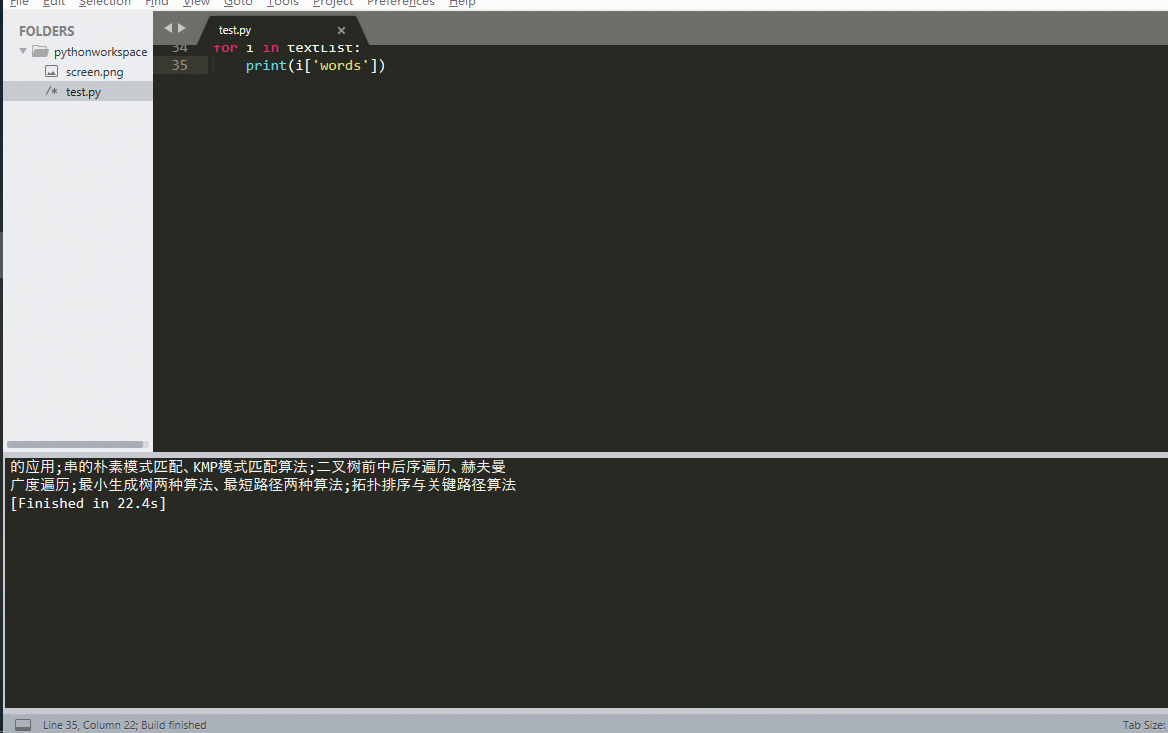
textList = text['words_result']
for i in textList:
print(i['words'])
运行结果:

到这里,图片的文字识别我们也掌握了。
程序源代码
下面是程序的所有代码:
import time
import keyboard
from PIL import ImageGrab
from aip import AipOcr
# 1、截取图片
keyboard.wait(hotkey='ctrl+alt+a') # 键盘输入的触发事件
keyboard.wait(hotkey='enter')
time.sleep(0.1) # 因为读取截取内容会有一个延迟,导致读取到的是上一次的截图,这里我们主动延迟
# 2、将图片保存到电脑上
image = ImageGrab.grabclipboard()
image.save('screen.png') # 将截取的图片进行保存
# 3、调用百度API识别图片内容
APP_ID = '18076523'
API_KEY = 'vlLcZ6VGb88qoAr5IN0OTShw'
SECRET_KEY = '8KzHr2AvEREYGGwdwIMFZSwTUoPB6LC4'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY) # 生成一个对策
# 获取图片的二进制数据
def get_file_content(filePath):
with open(filePath,'rb') as fp:
return fp.read()
image = get_file_content('screen.png')
# 调用文字识别(高精度版)
text = client.basicAccurate(image)
textList = text['words_result']
for i in textList:
print(i['words'])
效果在刚开始就演示过了,它可不光能复制PDF文字的内容,因为在哪里都可以进行截图操作,所以诸如一些百度文库的地方,无法复制文字内容,就可以通过这种方式曲线复制。
最后
最后我想说的是,要把学习当做自己的乐趣,编程是灵活的,自己遇到一些问题的时候,可以想着自己制作一些小工具,既解决了自己的问题,又能够从中学到很多知识,何乐而不为呢?
