语法分析程序分为自顶向下和自底向上两种。
语法分析程序的基本目标如下:
1.能够清楚而准确地报告发现的错误,如错误的位置和性质。
2.能够迅速地从错误中恢复过来,以便继续诊断后面可能存在的错误。
3.错误处理功能不应该明显地影响编译程序对正确程序的处理效率。
自顶向下分析方法是一种面向目标的分析方法,该方法从文法开始符开始,试图推导出与输入符号完全匹配的句子。该方法又分为确定的和不确定的两种。
有效的无回溯的自顶向下分析程序常称之为预测分析程序。
由于分析时对输入符号串的扫描是自左向右进行的,为保证能够按照扫描的顺序去匹配输入的符号串,采用最左推导好些。但是这种方法要消除左递归,同时回溯浪费时间较多。
下面介绍FIRST集的求法:
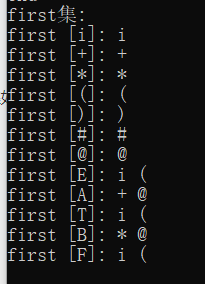
1.终结符的FIRST集是其本身
2.非终结符的FIRST集是由其推出的开头终结符或者空串
3.非终结符A如果能推出非终结符B并且B不在A能推出的终结符之后,则将B的FIRST集并入A的FIRST集
例如:
其中@表示空串
终结符:
i + * ( ) #
非终结符
E A T B F
产生式:
E→TA
A→+TA|@
T→FB
B→ * FB|@
F→(E)|i
求出的FIRST集如下:
非递归预测分析程序用到:一个输入缓冲区。一个分析栈。一张分析表。其核心是预测分析程序,此外还有输出流。
注意:这里分析的符号串只能含有终结符,并且要消除左递归。从开始符开始推,根据预测分析表的式子推即可,推不动或者与符号串不匹配就是语法错误。
下面介绍FOLLOW集的求法:
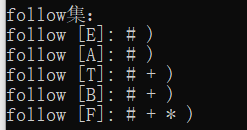
1.终结符没有FOLLOW集
2.对于产生式:A->aBC,将除去空串的First(C)加入Follow(B)中
3.对于产生式:A->aB或者A->aBC,(其中C可以推导出空串,C=>空串),则将Follow(A)加入Follow(B)中
4.把所有的FOLLOW集都补上美元符号。
注意:2.3中的C可以是终结符也可以是非终结符
例如:
其中@表示空串
终结符:
i + * ( ) #
非终结符
E A T B F
产生式:
E→TA
A→+TA|@
T→FB
B→ * FB|@
F→(E)|i
求出的FOLLOW集如下:
对于G中的每一个产生式, A -> α ,执行以下2步:
for ∀ a ∈ FIRST(α),
{
将 A -> α 填入 M [A, a ];
if(ε ∈ FIRST(α))
{
∀ a ∈ FOLLOW (A) , 将 A -> ε 填入 M [A, a ];
}
}
注意:a可以是空串
例如:
其中@表示空串
终结符:
i + * ( ) #
非终结符
E A T B F
产生式:
E→TA
A→+TA|@
T→FB
B→*FB|@
F→(E)|i
求出的预测分析表如下:

编译原理与技术(第二版)个人总结3

猜你喜欢
转载自blog.csdn.net/GodGump/article/details/103653615
今日推荐
周排行