一.卷积神经网络简介
卷积神经网络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的网络结构之一。CNN在CV和NLP领域都有很广泛的应用,相较于传统的算法,CNN避免了复杂的前期预处理过程(提取人工特征等),可以直接输入原始数据。CNN能够实现上述独特功能的原因是它使用了局部连接(Sparse Connectivity)和权值共享(Shared Weights)的方法。
CNN对BP神经网络的改进和升级,其底层依然和BP神经网络相似,采用神经元计算,并将神经元分为隐含层,输出层等。对于BP神经网络的相关内容,可以参考:NLP学习01–BP神经网络
下图是一个很经典的示例,CNN在图像处理中的应用,左边是全连接,右边是局部连接。
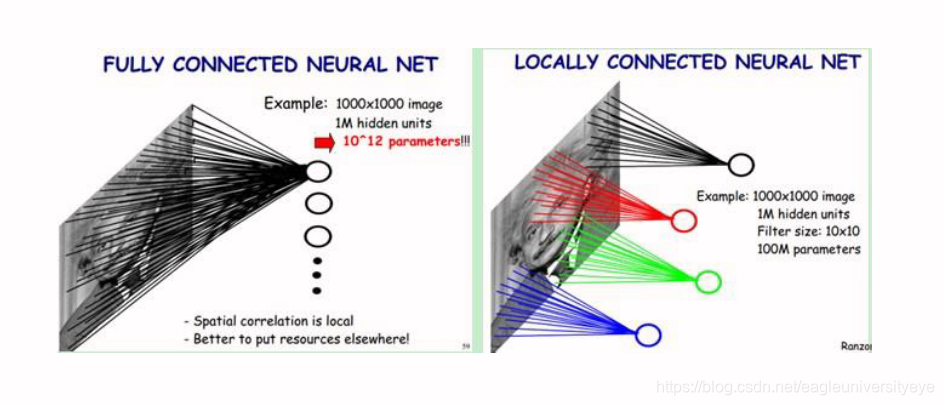
对于一个1000 × 1000的输入图像而言,如果下一个隐含层的神经元数目为10^6个,采用全连接则有1000 × 1000 × 10^6 = 10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级
尽管减少了几个数量级,但参数数量依然较多。而权值共享则可以继续减少参数。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个10 × 10的局部图像,因此有10 × 10个权值参数,将这10 × 10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10 × 10个权值参数,也就是卷积核(也称滤波器)的大小,如下图
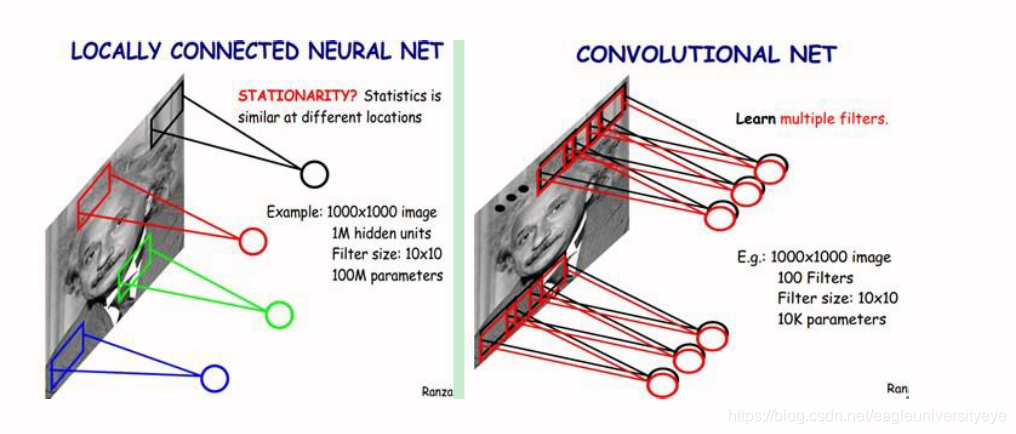
这大概就是CNN的一个神奇之处,尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 = 10^4(100各卷积核,每个卷积核有100个权值)个而已。另外,偏置参数也是共享的,同一种滤波器共享一个
相比于BP神经网络,卷积神经网络CNN的结构要更加复杂,其由输入层、卷积层、激活层、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC
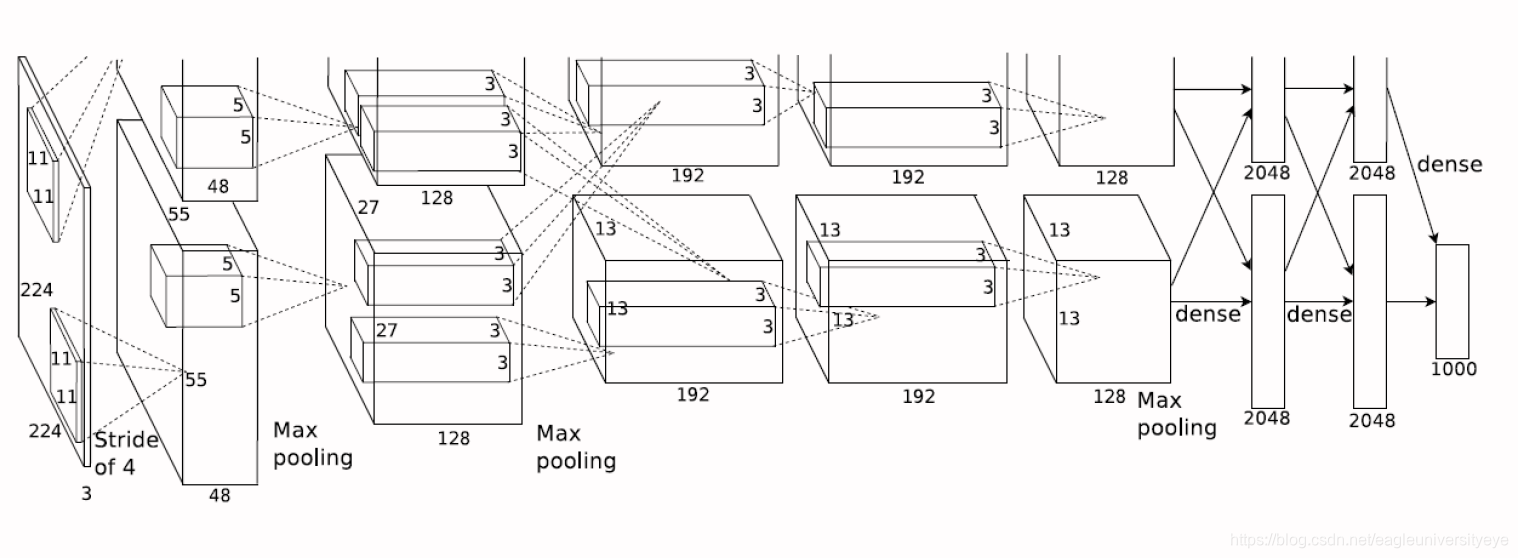
二.卷积神经网络CNN的工作原理
2.1 卷积层
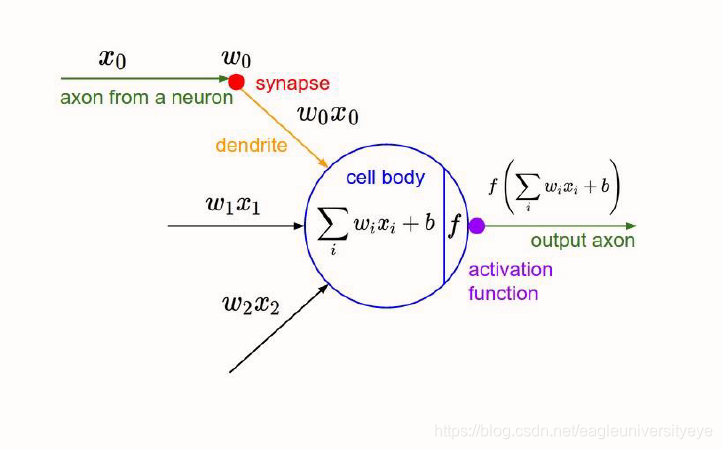
卷积层是卷积核在上一级输入层上通过逐一滑动窗口计算而得,卷积核中的每一个参数都相当于传统神经网络中的权值参数,与对应的局部像素相连接,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个偏置参数),得到卷积层上的结果
高纬度卷积
2.2 激活层
激活层将卷积层的输出作为输入参数,通过激活函数进行计算得出结果作为下一层的输入
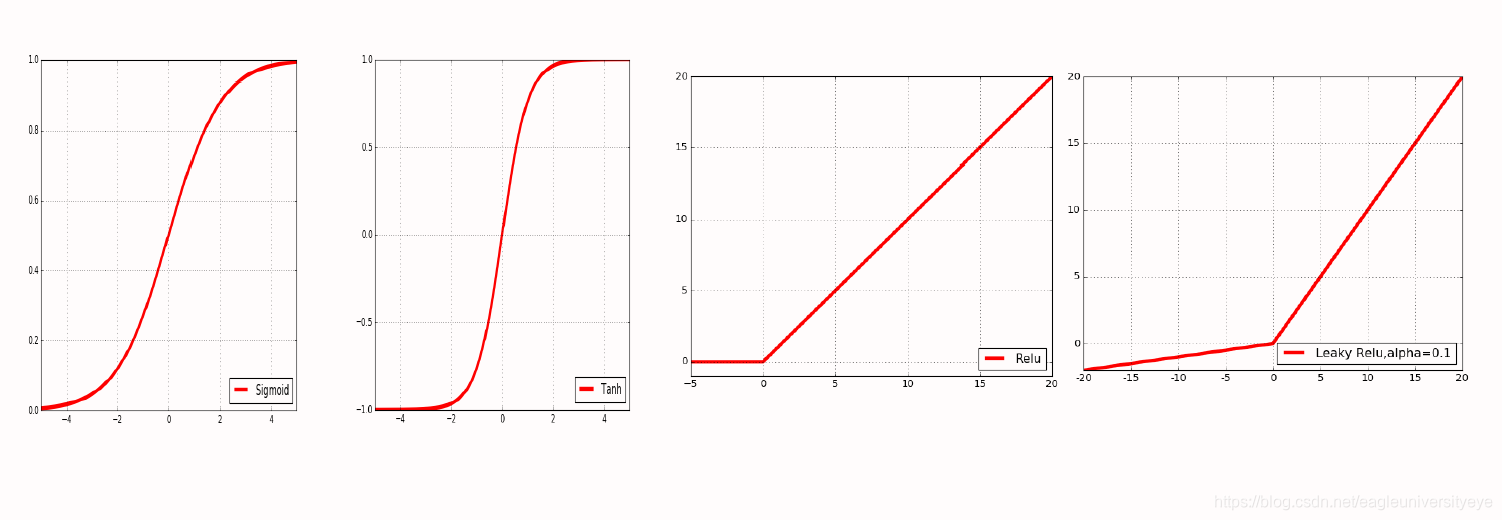
常用的激活函数有:
Sigmoid(S形函数)
Tanh(双曲正切,双S形函数)
ReLU
Leaky ReLU
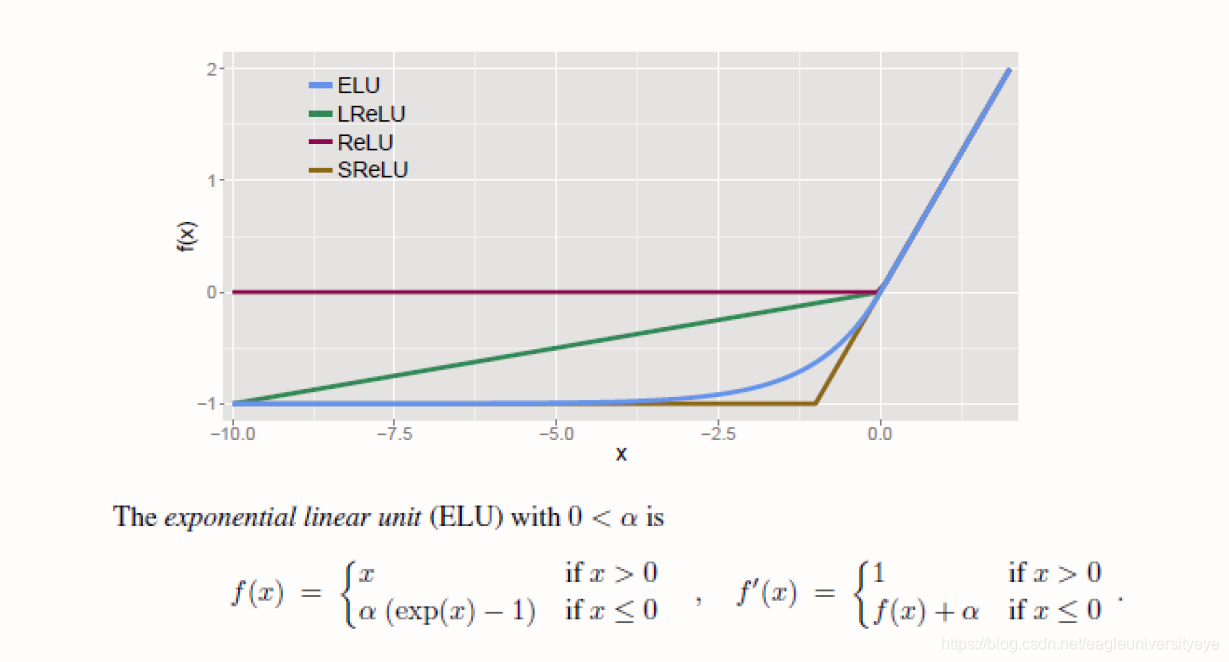
ELU
Maxout
常用的激活函数的图像:
2.3 池化层
在池化层中,进行压缩减少特征数量的时候一般采用两种策略:
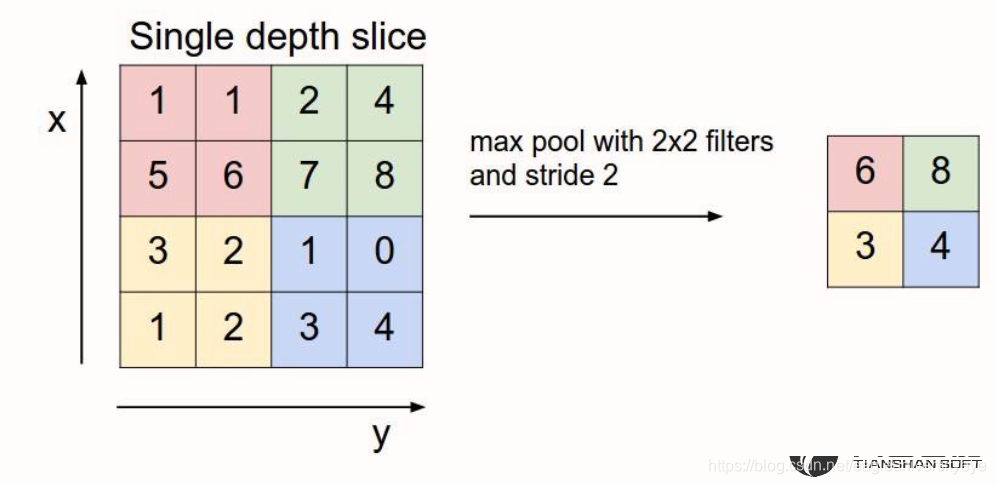
Max Pooling:最大池化(最常用)
Average Pooling:平均池化
最大池化原理图:
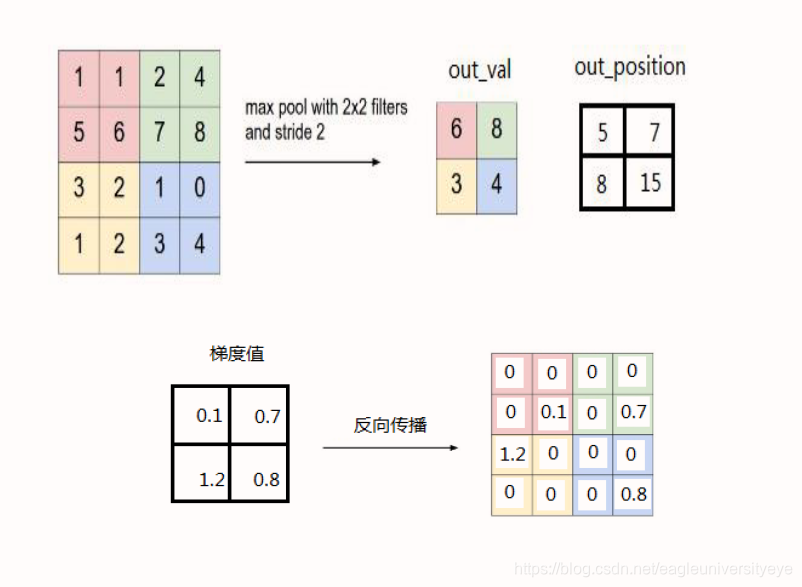
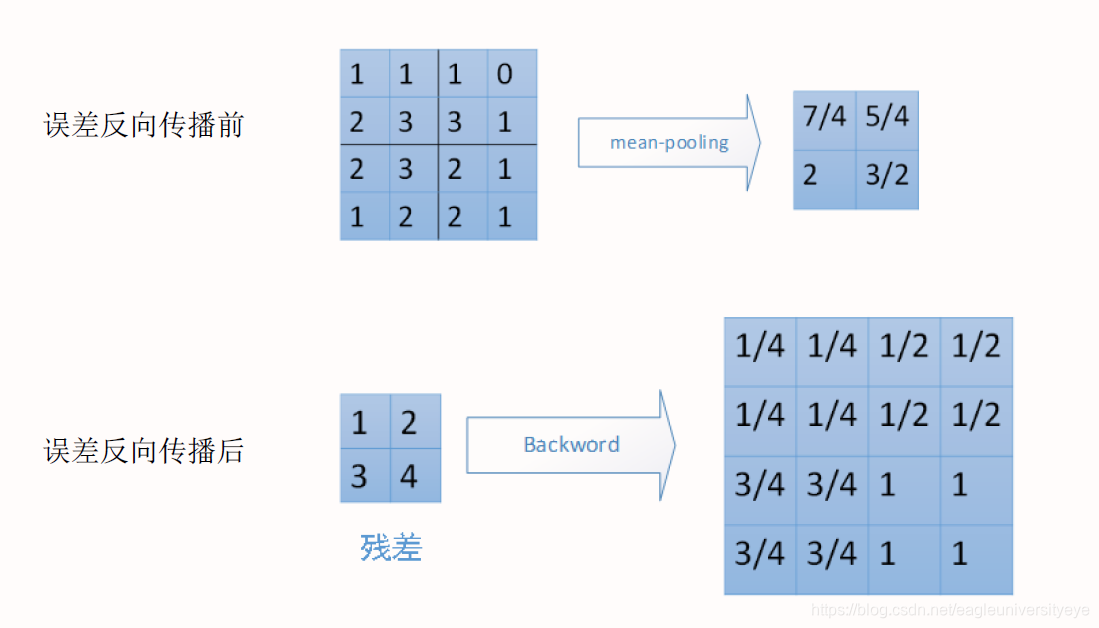
池化层误差反向传播
Maxpool 采用最大池化的池化层反向传播,除最大值处继承上层梯度外,其他位置置零
 平均池化,把残差平均分成2*2=4份,传递到前边小区域的4个单元即可。
平均池化,把残差平均分成2*2=4份,传递到前边小区域的4个单元即可。
2.4 正则化和Dropout
正则化是通过给cost函数添加正则项的方式来解决过拟合,Dropout是通过直接修改神经网络的结构来解决过拟合。
正则化
Regularization:正则化,通过降低模型的复杂度,通过在cost函数上添加一个正则项的方式来降低overfitting,主要有L1和L2两种方式。
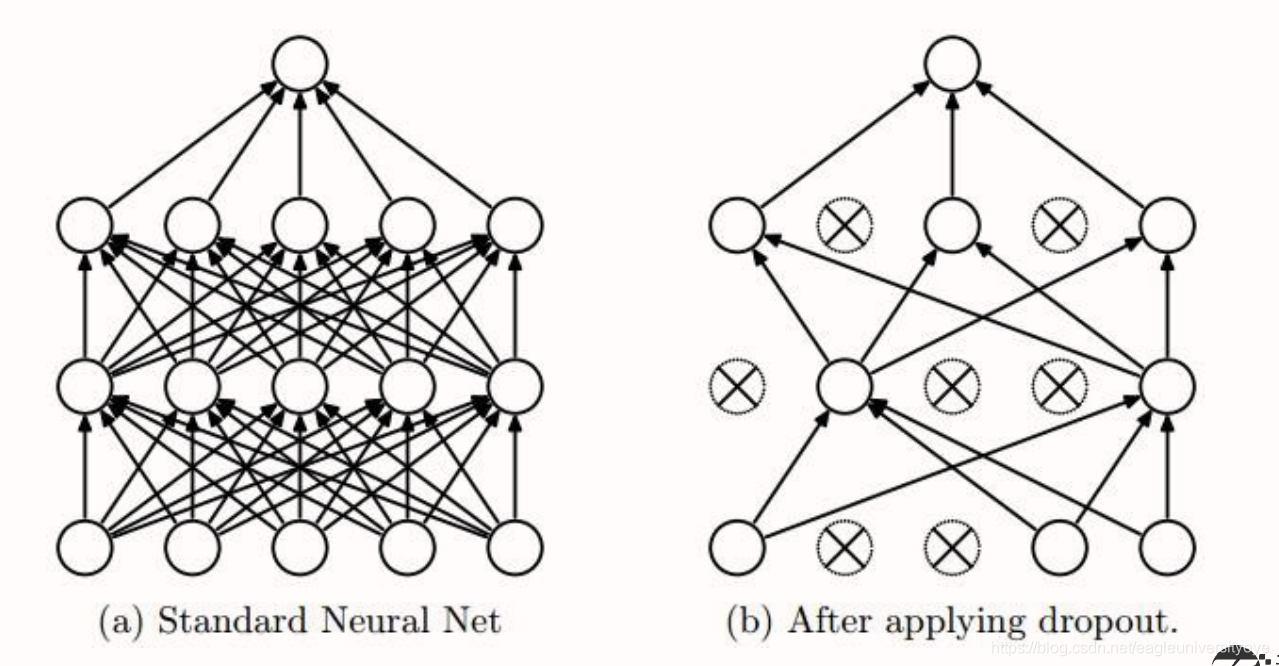
Dropout
Dropout:通过随机删除神经网络中的神经元来解决overfitting问题,在每次迭代的时候,只使用部分神经元训练模型获取W和b的值。对于同一组训练数据,利用不同的神经网络训练之后,求其输出的平均值可以减少过拟合。Dropout就是利用这个原理,每次丢掉一半左右的隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其它的神经元(指层与层之间相连接的神经元),使神经网络更加能学习到与其它神经元之间的更加健壮robust(鲁棒性)的特征。另外Dropout不仅减少过拟合,还能提高准确率。
2.5 Zero Padding
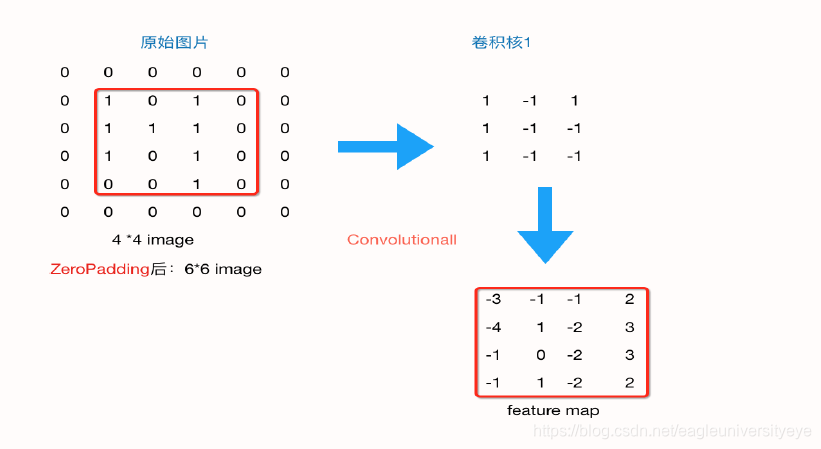
在上述过程中,原始图像由44,通过卷积层变为33,再通过池化层变化22,如果再添加层,那么图片会越变越小,这个时候我们就会引出“Zero Padding”(补零),它可以帮助我们保证每次经过卷积或池化输出后图片的大小不变,如,上述例子我们如果加入Zero Padding,再采用33的卷积核,那么变换后的图片尺寸与原图片尺寸相同。图片做完卷积操作后保持图片大小不变,所以我们一般会选择尺寸为33的卷积核和1的zero padding,或者55的卷积核与2的zero padding,这样通过计算后,可以保留图片的原始尺寸。那么加入zero padding后的feature_map尺寸 =( width + 2 * padding_size - filter_size )/stride + 1
注:这里的width也可换成height,此处是默认正方形的卷积核,weight = height,如果两者不相等,可以分开计算,分别补零。
2.6 全连接层
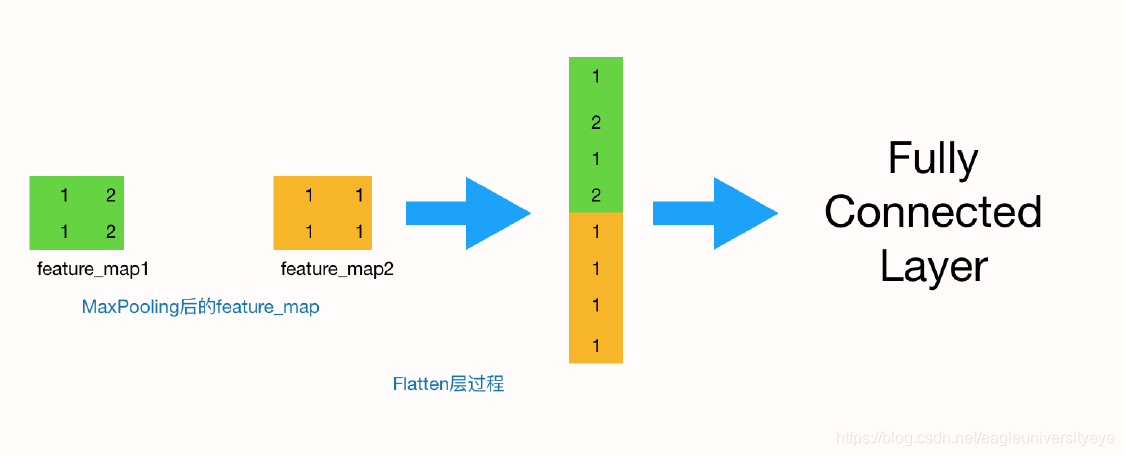
全连接层也叫做Flatten层,到这一层时,其实一个完整的“卷积部分”就算完成了,如果想要叠加层数,一般也是叠加“Conv-MaxPooing",通过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些数据“拍平”,丢到Flatten层,然后把Flatten层的output放到full connected Layer里,采用softmax对其进行分类
三.CNN在文本分类中的应用
CNN在自然语言中的应用,常遵循以下固定流程
输入层
输入层显示有两个channel,即两种模式,分别是static和non-static,即使用的词向量是否随着训练发生变化。non-static就是词向量随着模型训练变化(Fine tune),这样的好处是词向量可以根据数据集做适当调整,当数据集较小时不推荐此操作,否则容易产生过拟合现象。static就是直接使用word2vec训练好的词向量。此外,输入层是将一个句子所有单词(padding)的词向量进行拼接成一个矩阵,每一行代表一个词。每个句子固定20个词,如果不够就需要进行padding操作补零
卷积层
卷积层,每个卷积核的大小为filter_size*embedding_size。filter_size代表卷积核纵向上包含单词个数,即认为相邻几个词之间有词序关系,代码里使用的是[3,4,5]。embedding_size就是词向量的维数。每个卷积核计算完成之后我们就得到了1个列向量,代表着该卷积核从句子中提取出来的特征。有多少和卷积核就能提取出多少种特征,即图中在纵深方向上channel的数量
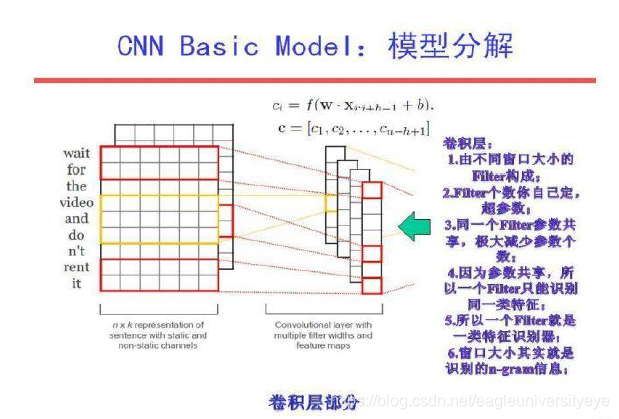
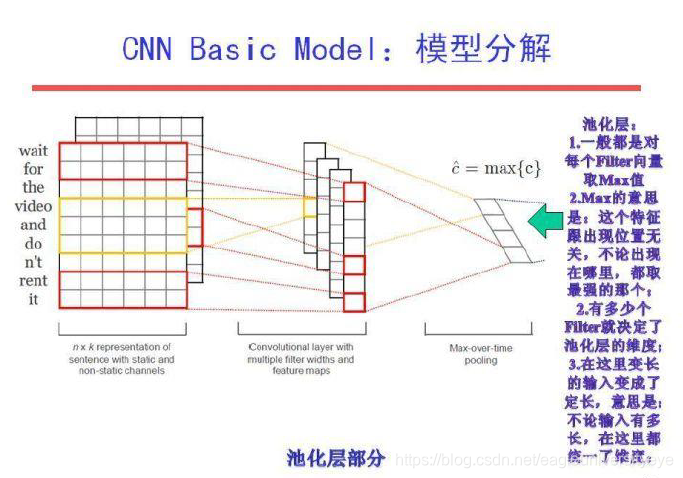
池化层
pooling操作就是将卷积得到的列向量的最大值提取出来。这样pooling操作之后我们会获得一个num_filters维的行向量,即将每个卷积核的最大值连接起来。这样做还有一个好处就是,如果我们之前没有对句子进行padding操作,那么句子的长度是不同的,卷积之后得到的列向量维度也是不同的,可以通过pooling来消除句子之间长度不同的差异
全连接层
为了将pooling层输出的向量转化为我们想要的预测结果,加上一个softmax层即可。如针对电影评价的分类任务,就是将其转化为正面、负面两个结果。文中还提到了过拟合的问题,因为实验中所使用的数据集相对较小,很容易就会发生过拟合现象,在实验过程中也会发现当迭代3000多轮的时候准确率就会接近1。所以这里引如dropout来减少过拟合现象。此外还可以考虑L2正则化等方法实现防止过拟合的功能

