Transformer的Encoder部分(不是上图一个一个的标为encoder的模块,而是红框内的整体,上图来自The Illustrated Transformer,Jay Alammar把每个Block称为Encoder不太符合常规叫法)是由若干个相同的Transformer Block堆叠成的。 这个Transformer Block其实才是Transformer最关键的地方,核心配方就在这里。
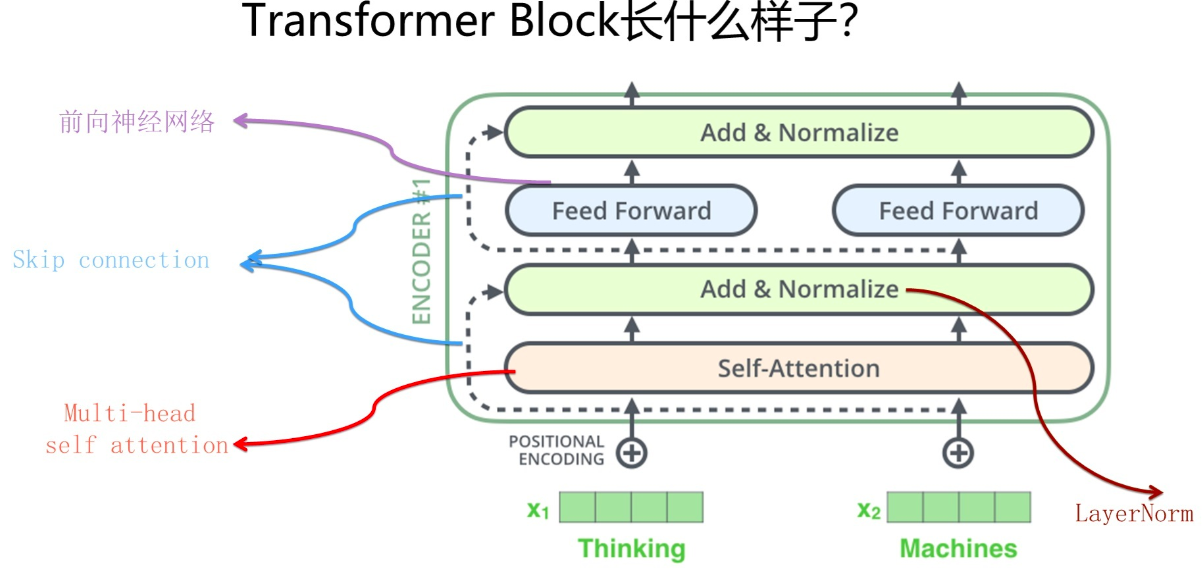
Transformer原始论文一直重点在说Self Attention,但是目前来看,能让Transformer效果好的,不仅仅是Self attention,这个Block里所有元素,包括Multi-head self attention,Skip connection,LayerNorm,FF一起在发挥作用。
参考:
放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较 - 张俊林的文章 - 知乎
