这是一篇发表于ICCV 2019 的论文,论文地址:https://arxiv.org/abs/1908.03245
代码地址:https://github.com/proteus1991/GridDehazeNet
1. 研究动机与主要贡献
GridDehazeNet包括三个模块:预处理、backbone、后处理。backbone模块实现了一种全新的基于注意力机制的多尺度网络(attention-based multi-scale estimation on a grid network),可以有效的缓解传统多尺度方法中的瓶颈问题。
首先,作者指出当前方法的三个问题:
- 物理模型方面: 数据驱动的dehazing方法需要合成数据用于训练,这些数据通常使用了一些物理模型来合成数据,但是如果模型不匹配的话,方法本身也会出现问题(model-dependent algorithm may suffer inherent performance loss on real-world images due to model mismatch)。
- 合适的预算理算法: 预处理算法的选择通常需要经验,所以,经常会出现选择错误的问题(not best suited to the problem under consideration)。
- 多尺度估计的瓶颈: 图像修复通常需要在失真图像和原图像之间建立一个统计模型,这就需要大量训练数据。多尺度估计(multi-scale estimation)方法解决这个问题主要通过下面方式:使用低维统计模型近似高维统计模型;使用训练数据估计低维统计模型中的参数;估计低维统计模型邻域的参数。因为多尺度估计方法经常分为若干步骤,经常有一定性能瓶颈(performance is limited by a certain bottleneck)。
为了解决上述问题,作者提出了GridDehazeNet,主要有三个贡献:(1)该方法不依赖于大气散射模型;(2)预处理模型是可以训练的,相比于人工选择的方法更具有灵活性;(3)基于注意力机制旧的多尺度网络可以较好的估计模型中的参数,该网络可以高效的交换不同尺度的信息,从而有效缓解多尺度估计的瓶颈问题。
2. 主要步骤
在 attention-based multi-scale estimation 方面,作者指出是受到 “Residual
conv-deconv grid network for semantic segmentation” 这篇论文的启发,同时,作者表示,grid network 比 encoder-decoder 网络优势明显。因为,encoder-decoder 网络容易受bottleneck effect的影响,同时, grid network 使用不同尺度间的密集连接来避免了这一问题。同时,该方法还使用了通道级的注意力机制,使得信息的交换和聚集更加灵活。同时,注意力机制还能够更好的处理预处理模块带来的diversity。
该方法的总体网络架构如下图所示,具有三层六列的结构,以GridNet网络架构为基础(GridNet原来是用于语义分割的)。每一层有五个 residual dense block 组成,图中每一列可以看做是多尺度操作的桥梁(通过上采样、下采样实现)。
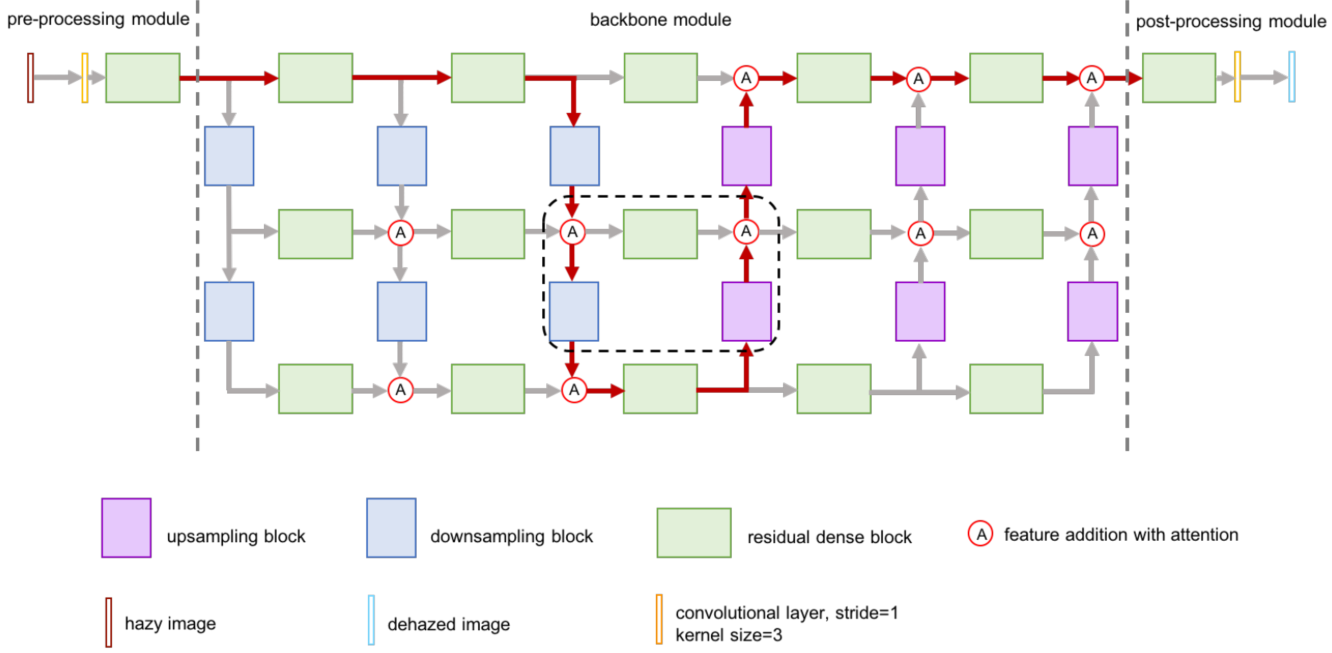
图2展示了 residual dense block 模块的细节。每个模块由5个卷积层组成,前四层用于增加feature map的数量,第五层融合feature map。
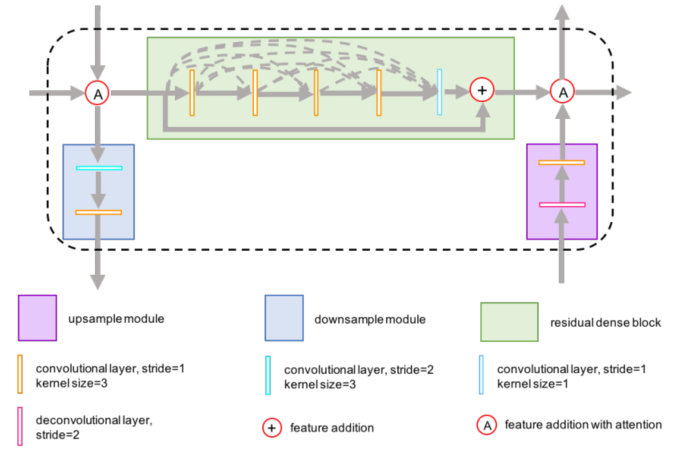
直接由backbone输出的图像,可能存在 artifacts。所以,后面还有一个后处理模块对图像进行处理。需要指出的的,预处理模块和后处理模块是完全反过来的,预处理模块由一个3X3的卷积层和 residual dense block 组成,输出为16个 feature map。后处理模块由一个 residual dense block 和3X3的卷积层组成,输出为 dehazed image.
注意力机制的应用: 作者指出,来自不同尺度的 feature map 可能重要性不一样,因此, 用 \(F^i_r\) 和 \(F^i_c\) 分别表示来自第\(i\)个通道上,第\(r\)行和第\(c\)列的 feature map,用 \(a^i_r\) 和 \(a^i_c\) 分别表示相应的注意力权重,通道级别的融合为:
\[F^i=a^i_rF^i_r+a^i_cF^i_c\]
作者也指出,注意力机制的细节可以参照“Attention is all you need” 这篇文章。注意力机制的引入,使得该方法可以很好的在特征融合时,调节不同尺度信息的权重。实验中,也证明了,即使只引入一小部分attention weights,网络的性能也会有较大改善。
损失函数: 该方法使用了 smooth \(L_1\) loss 和 perceptual loss 。细节可参考论文。最终的损失函数为 \(L = L_S + \lambda L_P\),其中 \(\lambda\)取值为0.04。
3. 实验分析
训练中,该方法使用了 RESIDE数据集,包括 13990 张 hazy image (包含室内和室外场景),是由 1399张 clear image 生成的。在测试中,作者与DCP,DehazeNet, MSCNN, ADO-Net, GFN方法进行了对比,可以看到该方法在 haze removal 和 distortion suppression 方面表现非常好。
