目录
详情
没懂
名称:Lawin Transformer: Improving Semantic Segmentation Transformer with Multi-Scale Representations via Large Window Attention
单位:北京邮电大学
论文
代码
摘要
多尺度表示对于语义分割至关重要。目前见证了利用多尺度上下文信息的语义分割卷积神经网络 (CNN) 的蓬勃发展。由于视觉Transformer (ViT) 在图像分类方面的强大功能,最近提出了一些语义分割 ViT,其中大多数取得了令人印象深刻的结果,但以计算经济为代价。
-
通过窗口注意力机制将多尺度表示引入语义分割 ViT,并进一步提高了性能和效率。
为此,引入了大窗口注意力,它允许局部窗口以很少的计算开销查询更大区域的上下文窗口。 -
通过调节上下文区域与查询区域的比例,使大窗口注意力能够在多个尺度上捕获上下文信息。
-
此外,采用空间金字塔池化框架与大窗口注意力协作,提出了一种名为大窗口注意力空间金字塔池化(LawinASPP)的新型解码器,用于语义分割 ViT。
ViT Lawin Transformer
- 编码器:高效分层视觉Transformer (HVT)
- 解码器: LawinASPP 组成。
1. Introduction
之前的技术
CNN
主要工作:利用多尺度表征
方法:将过滤器或池化操作(如atrous convolution和自适应池化应用于空间金字塔池化(SPP)模块。
vit
缺点:很高的计算成本,尤其是在输入图像较大的情况下
解决:
该方法纯粹基于层次视觉转换器(HVT)
Swin Transformer是最具代表性的hvt之一,使用了一个沉重的解码器来分类像素。

SegFormer改进了编码器和解码器的设计,产生了非常高效的语义分割ViT。
缺点:仅仅依靠增加编码器的模型容量来逐步提高性能,这可能会降低效率上限。
目前的主要问题:缺乏多尺度的上下文信息,从而影响了其性能和效率。
提出方法:一种新的窗口注意机制——大窗口注意。
现在的方法
大窗口注意
在大窗口关注中,如图1所示,统一分割的patch查询的是覆盖更大区域的context patch,而局部窗口关注中的patch只查询自身。另一方面,考虑到随着语境patch的扩大,注意力在计算上会变得不可接受,
设计了一个简单但有效的策略来缓解大语境的困境。
具体来说,
1.首先将大context patch池到对应查询patch的空间维度上,以保持原始的计算复杂度。
2.然后我们在大窗口关注下启用多头机制,并在池化上下文时严格设置多头数等于下采样比R的平方,主要是为了恢复被丢弃的查询与上下文之间的依赖关系。
3.最后,受MLP- mixer[37]中标记混合MLP的启发,在头部的R的平方子空间上分别应用R平方位置混合操作,增强了多头注意的空间表征能力。
因此,我们提出的大窗口注意中的 patch可以捕获任何尺度的上下文信息,只产生由位置混合操作引起的少量计算开销。再加上不同比率R的大窗口注意力,SPP模块演化为大窗口注意力空间金字塔池化(LawinASPP),可以使用像ASPP (Atrous空间金字塔池)[9]和PPM(金字塔池模块)[50]来利用多尺度表示进行语义分割。
2. Related Work
vit的探索
ViT是用于图像分类的第一个端到端视觉转换器,它将输入图像投影到一个标记序列中,并将其附加到一个类标记上。
PVT和Swin Transformer的效率引发了人们对**分层视觉变压器(HVT)**的兴趣。
1.SETR将ViT作为编码器部署,并对输出 patch embedding 进行上采样,以对像素进行分类。
‘
2.Unified perceptual parsing for scene understanding
Swin Transformer通过连接一个UperNet将自己扩展到一个语义分段ViT。
3.Segmenter依赖于ViT/DeiT作为骨干,并提出一个掩码变压器解码器。
4.Segformer显示了一个简单,有效,但强大的编码器和解码器的语义分割设计。
5.MaskFormer将语义分割重新定义为一个掩码分类问题,与Swin-UperNet相比,具有更少的FLOPs和参数。
在本文中,通过在HVT中引入多尺度表示,向更高效的语义分割ViT设计迈出了新的一步。
MLP-Mixer
MLP-Mixer[37]是一种比ViT简单得多的新型神经网络。MLP-Mixer与ViT类似,
首先采用线性投影的方式获得类似ViT的令牌序列。
MLP- mixer完全基于多层感知器(MLP),因为它用 token-mixing MLP取代了transformer layer的自我注意。Token-Mixing MLP沿着通道维度工作,Token-Mixing MLP(位置)来学习空间表示。在我们提出的大窗口注意中,将Token-Mixing MLP应用于池化的上下文补丁,我们称之为位置混合,以提高多头注意的空间表示。
3. Method
在这一部分中
首先简要介绍了多头注意和 token-mixing MLP
然后详细阐述了大窗口关注点,并描述了LawinASPP的体系结构
最后,给出了Lawin变压器的总体结构。

总体架构
1.图像被送入编码器部分,这是一个MiT
2.然后,最后三个阶段的特征被聚合并输入到解码器部分,这是一个LawinASPP
3.最后,利用编码器的第一级特征对得到的特征进行低级信息的增强。MLP表示多层感知器。CAT“表示连接特性。”Lawin "表示大窗口关注。"R”表示context patch的大小与query patch的大小之比。
3.1. Background
Token-mixing MLP
Token-mixing MLP是MLP- mixer的核心,它通过允许空间位置相互通信来聚合空间信息。
假设输入的2D feature map x2d∈RC ×H ×W,则token-mix MLP的操作可表示为:

其中W1∈RHW ×Dmlp和W2∈RDmlp×HW都是学习的线性变换,σ是提供非线性的激活函数。
3.2. Large Window Attention
通过对头部子空间进行一定的正则化,多头注意可以学习所需的多样化表征[12,16,18]。考虑到下采样后空间信息变得抽象,我们希望增强多头注意的空间表征能力。

图2 一个大窗口关注。其中红色patch Q为 query patch ,紫色patch C为context patch。上下文被重新塑造并输入到token-mixing MLPs. 中。输出上下文CP被命名为位置混合上下文。彩色观看效果最佳。
在MLP- mixer中,token-mixing MLP是对channel-mixing MLP的补充,用于收集空间知识,我们定义了一组头部特定位置混合MLP = {MLP1, MLP2,…, MLPh}。如图2所示,池中context patch的每个head都被推入其对应的token(position)混合MLP中,同一个head中的空间位置以相同的行为相互通信。我们将得到的context称为位置混合context patch,并表示为C的P,其计算公式为:

其中ˆCh表示ˆC的第h个头,MLPh∈RP 2 ×P 2是第h个变换,加强了第h个头的空间表示,其中其中n为平均池化操作。有了位置混合上下文CP,我们可以将式(3)和式(4)重新表示为:

3.3. LawinASPP
为了捕获多尺度表示,我们采用空间金字塔池化(SPP)架构与大窗口关注协作,得到了新的SPP模块LawinASPP。
LawinASPP由5个并行分支组成,其中包括一个快捷连接,3个大型窗口注意(R =(2, 4, 8))和一个图像池分支。
如图3所示,**大窗口注意分支为局部窗口提供了三个接受域层次结构。**参照之前关于窗口注意机制[30]的文献,我们将本地窗口的patch大小设为8,因此提供的接收域为(16,32,64)。

图像池化分支使用全局池化层获取全局上下文信息,并将其推入线性变换,然后进行双线性上采样操作,以匹配特征维数。
当输出所有上下文信息时,短路径复制输入特性并粘贴它。所有产生的特征首先被连接起来,并学习线性变换执行降维生成最终的segmentation map。
3.4. Lawin Transformer
在研究了先进的hvt后,选择MiT和Swin-Transformer作为Lawin Transformer的编码器。
MiT是专为作为编码器的SegFormer[43],这是一个简单,有效,但强大的语义分割ViT。
Swin-Transformer[30]是一款非常成功的基于本地窗口关注的HVT。
在应用LawinASPP之前,
将输出stride =(8,16,32)的多级特征连接起来,将它们的大小调整为输出stride = 8的特征的大小,并使用一个线性层对拼接进行转换。将输出stride = 8的变换后的特征输入到lawwinaspp中,得到具有多尺度上下文信息的特征。
在最先进的语义分割ViT中,用于最终预测分割对数的特征总是来自于编码器的4级特征。
因此,我们使用输出stride = 4的第一级特征来补偿低级信息。
将LawinASPP的输出上采样到输入图像的四分之一大小,然后用线性层与第一层特征融合。
最后,在低级增强特征上预测分割日志。更多的细节如图3所示
4. Expriments
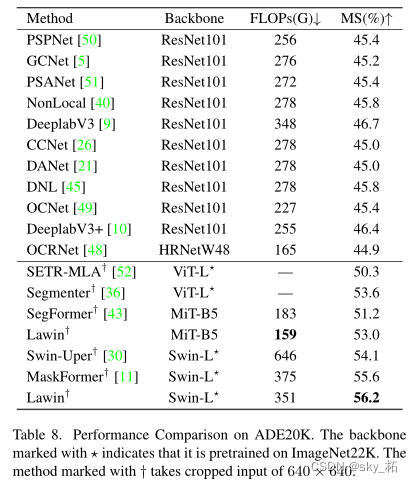
5. Conclusion
高效的语义分割变压器称为Lawin变压器。
Lawin Transformer的解码器部分能够在多尺度上捕获丰富的上下文信息,这是建立在我们提出的大窗口注意力的基础上的。与现有的高效语义分割Transformer相比,Lawin Transformer可以以更少的计算开销获得更高的性能。最后,我们对cityscape、ADE20K和COCO-Stuff数据集进行了实验,在这些基准上产生了最先进的结果。我们希望Lawin Transformer在未来能够激发语义分割ViT的创造性。