5.3.11 什么是 IoC
控制反转(Inverse of Control,IoC)有时也被称为依赖注入,是一种降低对象之间耦合关系的设计思想。一般而言,在分层体系结构中,都是上层调用下层的接口,上层依赖于下层的执行,即调用者依赖于被调用者。而通过 IoC 方式,使得上层不再依赖于下层的接口,完成控制反转,使得由调用者来决定被调用者。IoC 通过注入一个实例化的对象来达到解耦和的目的。使用这种方法后,对象不会被显式地调用,而是根据需求通过 IoC 容器(例如 Spring)来提供。
采用 IoC 机制能够提高系统的可扩展性,如果对象之间通过显式调用进行交互会导致调用者与被调用者存在着非常紧密的联系,其中一方的改动将会导致程序出现很大的改动。
例如,要为一家卖茶的商店提供一套管理系统,在这家商店刚开业时只卖绿茶(GreenTea),随着规模的扩大或者根据具体销售量,未来可能会随时改变茶的类型,例如红茶(BlackTea)等,传统的实现方法会针对茶抽象化一个基类,绿茶类只需要继承自该基类即可,如图 5-12 所示。
采用该实现方法后,在需要使用 GreenTea 时只需要执行以下代码即可:AbstractTea t=new GreenTea(),当然,这种方法是可以满足当前设计要求的。但是该方法的可扩展性不好,存在着不恰当的地方,例如,商家发现绿茶的销售并不好,决定开始销售红茶(Black Tea)时,那么只需要实现一个 BlackTea 类,并且让这个类继承自 AbstractTea 即可。但是,系统中所有用到 AbstractTea t=new GreenTea()的地方都需要被改为 AbstractTea t=new BlackTea(),而这种创建对象实例的方法往往会导致程序的改动量非常大。
通过以上方法,可以把创建对象的过程委托给 TeaFatory 来完成,在需要使用 Tea 对象时只需要调用 Factory 类的 getTea 方法即可,具体创建对象的逻辑在 TeaFactory 中来实现,那么当商家需要把绿茶替换为红茶时,系统中只需要改动 TeaFactory 中创建对象的逻辑即可,采用了工厂模式后,只需要在一个地方做改动就可以满足要求,这样就增强了系统的可扩展性。
虽然说采用工厂设计模式后增强了系统的可扩展性,但是从本质上来讲,工厂模式只不过是把程序中会变动的逻辑移动到工厂类里面了,当系统中的类较多时,在系统扩展时需要经常改动工厂类中的代码。而采用 IoC 设计思想后,程序将会有更好的可扩展性,下面主要介绍 Spring 框架在采用 IoC 后的实现方法,如图 5-14 所示。
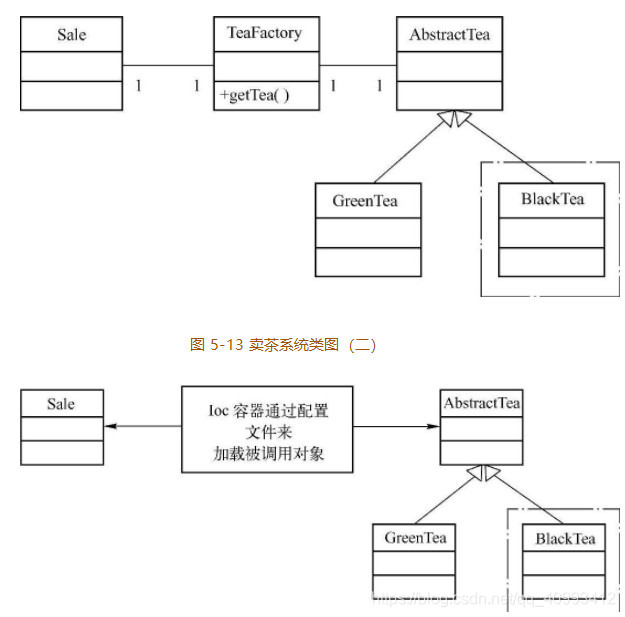
Spring 容器将会根据配置文件来创建调用者对象(Sale),同时把被调用的对象(Abstract-Tea 的子类)的实例化对象通过构造函数或 set()方法的形式注入到调用者对象中。


当 Spring 容器创建 Sale 对象时,根据配置文件 SpringConfig.xml 就会创建一个 BlueTea 的对象,作为 Sale 构造函数的参数。当需要把 BlueTea 改为 BlackTea 时,只需要修改上述配置文件,而不需要修改代码。

具体而言,IoC 主要有以下两个方面的优点:
1)通过 IoC 容器,开发人员不需要关注对象如何被创建的,同时增加新类也非常方便,只需要修改配置文件即可实现对象的「热插拔」。
2)IoC 容器可以通过配置文件来确定需要注入的实例化对象,因此非常便于进行单元测试。
尽管如此,IoC 也有自身的缺点,具体表现为:
1)对象是通过反射机制实例化出来的,因此会对系统的性能有一定的影响。
5.3.12 什么是 AOP
面向切面编程(Aspect-Oriented Programming,AOP)是对面向对象开发的一种补充,它允许开发人员在不改变原来模型的基础上动态地修改模型以满足新的需求,例如,开发人员可以在不改变原来业务逻辑模型的基础上可以动态地增加日志、安全或异常处理的功能。
时可以采用 AOP 的方式来实现这个功能。它在不修改原有模块的前提下可以完成相同的功能。
5.3.13 什么是 Spring 框架
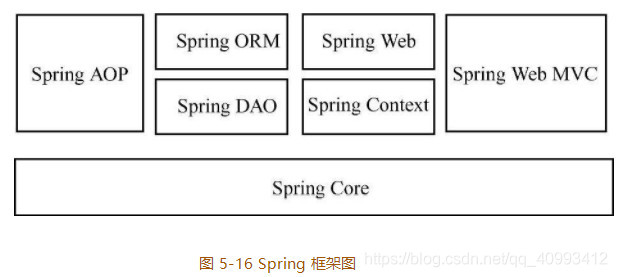
Spring 是一个 J2EE 的框架,这个框架提供了对轻量级 IoC 的良好支持,同时也提供了对 AOP 技术非常好的封装。
在使用 Spring 框架时,开发人员可以使用整个框架,也可以只使用框架内的一部分模块,例如可以只使用 Spring AOP 模块来实现日志管理功能,而不需要使用其他模块。


除此之外,使用 Spring 还有如下好处:
1)在使用 J2EE 开发多层应用程序时,Spring 有效地管理了中间层的代码,由于 Spring 采用了控制反转和面向切面编程的思想,因此这些代码非常容易进行单独测试。
2)使用 Spring 有助于开发人员培养一个良好的编程习惯:面向接口编程而不是面向类编程。面向接口编程使得程序有更好的可扩展性。
3)Spring 对数据的存取提供了一个一致的框架(不论是使用 JDBC 还是 O/R 映射的框架,例如 Hibernate 或 JDO
4)Spring 通过支持不同的事务处理 API(如 JTA、JDBC、Hibernate 等)的方法对事务的管理提供了一致的抽象方法。
5.3.18 如何实现分页机制
在交互式的应用程序中,当数据量很大时,如果一次性把所需数据全部从数据库中查询出来,不仅非常耗费时间,而且还会消耗大量的内存,导致用户操作的延时,严重影响系统的可用性。因此,为了降低系统的响应时间,提高系统的性能,往往会使用分页机制,即不是把用户所需数据一次性全部查找出来,而是把数据分成很多的页,每一页只包含指定的记录数,在查询时根据需求每次只查找一页或多页的数据而不是所有数据。由于采用分页机制使得查询的结果集中数据量减少了,同时也降低了内存的消耗,因此可以显著降低响应时间,有助于提高系统的可用性,增强用户体验。
下面主要介绍两种分页的实现方法。
(1)Hibernate 自带的分页机制
Hibernate 提供了一个支持跨系统的分页机制,该机制保证无论底层是什么样的数据库都能使用统一的接口进行分页操作。其用法如下:首先,通过 Session 对象获取 Query 对象;其次,使用 Query 对象的 setFirstResult()方法来设置要查询的第一行数据;最后,用 setMaxRe-sults()方法来设置要查询结果集的大小。
下列代码的功能就是从第 100 条开始取出 50 条记录:

5.3.19 什么是 SSH
SSH 是 Structs、Spring 和 Hibernate 的首字母组合,它是一种比较流行的用来开发 Web 应用程序的开源框架,用于构建灵活、易于扩展的多层 Web 应用。
使用 SSH 框架开发的系统从职责上可以分为 4 层:表示层、业务逻辑层、数据持久化层和域模块层,如图 5-19 所示。
其中,Struts 实现了 MVC 模式,它对 Model、View 和 Controller 的各个模块都提供了支持。Struts 框架使用 JSP 实现了视图部分,模型部分则通过 Hibernate 框架提供的支持来实现数据的持久化,业务层则使用了 Spring 作为支持来管理对象。
接着,Spring 把抽象出的模型用 Java 类来实现,同时为这些模型编写对应的 DAO 接口,同时给出基于 Hibernate 的 DAO 的实现,即实现 Java 对象与关系数据库之间数据的转换。然后使用 Spring 来完成业务逻辑,来管理 Hibernate 与 Struts 对象。
采用 SSH 框架,不仅能实现视图、控制器与模型的彻底分离,而且还能实现业务逻辑层与数据持久层的分离。无论前端如何变化,模型层只需很少的改动即可满足要求;此外,数据库的变化也不会对前端有所影响,从而大大提高了系统的可复用性、可扩展性与易维护性。而且由于不同层之间的低耦合度,使得团队成员能够并行开发,从而大大节省了时间,提高了应用的开发效率。
由于 SSH 提供了很多有用的框架,因此能显著提高项目的开发效率。其主要优点如下:
1)Struts 实现了 MVC 模式,这种模式的特点是对应用程序进行了很好的分层,使得开发人员只需要把开发重点放在业务逻辑的开发即可。不仅如此,Struts 还提供了许多非常有用的标签库,这些标签能够显著地提高开发人员的开发效率。
2)Spring 可以用来管理对象。使用 Spring 的 IoC 容器,把对象之间的依赖关系交给 Spring,降低组件之间的耦合性,让开发人员更专注于业务逻辑的开发。Spring 采用了 IoC 和 AOP 的思想,使得它具有很好的模块化,程序与可以根据需求使用其中的一个模块。Spring 还提供了一些非常有用的功能,例如事务管理等。
3)Hibernate 作为一个轻量级的持久性框架,实现了高效的对象关系映射,使得开发可以完全采用面向对象的思想,而不需要关心数据库的关系模型。使用 Hibernate 开发的系统有很好的可移植性,可以很容易地实现不同数据库之间的移植,而不需要关心不同数据库 SQL 语句的差异。

5.3.17 Hibernate 有哪些主键生成策略
Hibernate 作为一种优秀的持久层框架,采用 ORM 方式,大大地简化了对数据库的操作。同时,Hibernate 框架提供的主键生成策略,使开发人员可以通过在实体类的映射文件中设定关键字来告诉 Hibernate 要使用的主键生成方式,然后 Hibernate 会根据设定完成数据库的主键控制。Hibernate 中的主键生成策略主要有如下几种:
1)Assigned。使用该方法时,主键不是由 Hibernate 生成的,而是由外部程序负责生成,所以无需 Hibernate 参与,但需要开发人员在调用 save()方法之前来指定,否则调用 save()方法会抛出异常。其缺点是在执行新增操作时需查询数据库判断生成的主键是否已经存在,否则很容易产生主键冲突。
2)Hilo。该方法使用一个高/低位算法(High/Low Algorithm)生成 long、short 或 int 类型的标识符。给定一个表和字段作为高位值的来源(默认的表是 hibernate_unique_key,默认的字段是 next_hi)。它将 id 的产生源分成两部分:DB+ 内存,然后,按照算法结合在一起产生 id 值,从而可以在很少的连接次数内产生多条记录,提高效率。
需要注意的是,该方法需要额外的数据库表保存主键生成历史状态。Hilo 能保证同一个数据库中主键的唯一性,但不能保证多个数据库之间主键的唯一性。
3)Seqhilo。与 Hilo 类似,Seqhilo 是一种通过高/低位算法实现的主键生成机制,只是主键历史状态保存在 Sequence 中,适用于支持 Sequence 的数据库,例如 Oracle。
4)Increment。这种方式采用对主键自增的方式来生成新的主键。实现机制为:在当前应用实例中维持一个变量,以保存当前的最大值,之后每当需要生成主键时,便会将此值加 1 作为主键。该方式要求数据库支持 Sequence。
尽管该方式优点众多,但问题也不少。首先,新增数据前需要先查询一遍,这会影响系统的性能;其次,主键的类型只能是数值的 int 或 long 型;最后,会产生并发问题,即如果当前有多个实例访问同一个数据库,那么由于各个实例各自维护主键状态,不同实例可能生成同样的主键,从而造成主键重复异常。所以,该方法只适合单线程对数据库的访问方式,不适合在多进程并发更新数据库的场合使用。因此,如果同一数据库有多个实例访问,最好不要使用这种方法。需要注意的是,该主键递增的方式是由 Hibernate 来维护的。
5)Identity。这种方式采用数据库提供的自增方式来生成新的主键,例如 DB2、SQL Server、MySQL 中的主键生成机制。该方式的特点是不需要 Hibernate 与开发人员的干涉,使用起来非常方便,但会给程序在不同数据库的移植带来严重不便。
6)Sequence。这种方式采用数据库提供的 Sequence(序列)机制生成主键。这就要求数据库必须提供 Sequence 机制,例如 Oracle 就提供 Sequence 机制。其主要缺点是当程序在不同数据库之间移植时,特别是从支持序列的数据库移植到不支持序列的数据库时,使用该方式会非常麻烦。
7)Native。在该方式中,由 Hibernate 根据底层数据库自行选取 Identity、Hilo、Sequence 中的一种作为主键生成方式,例如,对于 Oracle 采用 Sequence 方式,对于 MySQL 和 SQL Server 采用 Identity 方式。该方式的一个主要优点就是灵活性更强,便于程序的移植。
8)UUID。uuid.hex 由 Hibernate 基于 128 位唯一值产生算法生成 16 进制数值(编码后以长度 32 位的字符串表示)作为主键。这种方式能够保证在不同的环境下主键的一致性。
uuid.string 与 uuid.hex 类似,只是生成的主键未进行编码(长度 16 位)。在某些数据库(例如 PostgreSQL)中可能出现问题。
该方式能够保证数据库中的主键唯一性,但是在生成的主键占用比较多的存储空间。
9)Foreign GUID。这种方式用于在一对一的关系中采用一种特殊的算法来生成主键,从而保证了主键的唯一性。
5.3.16 Hibernate 中 session 的 update()和 saveOrUpdate()、load()和 get()有什么区别
Hibernate 的对象有 3 种状态,分别为:瞬时态(Transient)、持久态(Persistent)和脱管态(Detached)。处于持久态的对象也被称为 PO(Persistence Object),瞬时对象和脱管对象也被称为 VO(Value Object)。
saveOrUpdate()方法同时包含了 save()和 update()方法的功能。Hibernate 会根据对象的状态来确定是调用 save()方法还是调用 update()方法:若对象是持久化对象,则不进行任何操作,直接返回;若传入的对象与 session 中的另一个对象有相同的标识符,则抛出一个异常;若对象的标识符属性(用来唯一确定一个对象)在数据库中不存在或者是一个临时值,则调用 save()方法把它保存到数据库中,否则,调用 update()方法更新对象的值到数据库中。鉴于此,在使用时,若能确定对象的状态,则最好不要调用 saveOrUpdate()方法,这样有助于提高效率,例如,如果能够确定这个对象所对应的值在数据库中肯定不存在,那么就可以直接调用 save()方法。
get()方法与 load()方法都是用来通过从数据库中加载所需的数据来创建一个持久化的对象,它们主要有以下几个不同点:
1)如果数据库中不存在该对象,load()方法会抛出一个 ObjectNotFoundException 异常,而 get()方法则会返回 null。
2)get()方法首先查询 Session 内部缓存,若不存在,则接着查询二级缓存,最后查询数据库;而 load()方法在创建时会首先查询 Session 内部缓存,如果不存在,就创建代理对象,实际使用数据时才查询二级缓存和数据库,因此 load()方法支持延迟加载(对象中的属性在使用时才会加载,而不是在创建对象时就加载所有属性)。
3)get()方法永远只返回实体类,而 load()方法可以返回实体类的代理类实例。
4)get()方法和 find()方法都是直接从数据库中检索,而 load()方法的执行则比较复杂:首先查找 Session 的 persistent Context 中是否有缓存,若有,则直接返回;若没有,则判断是否是 lazy。如果不是,直接访问数据库检索,查到记录返回,查不到抛出异常;若是 lazy,则需要建立代理对象,对象的 initialized 属性为 false,target 属性为 null。在访问获得的代理对象的属性时检索数据库,若找到记录,则把该记录的对象复制到代理对象的 target 上,并将 initial-ized 置为 true;若找不到,就抛出异常。
5.3.15 什么是 Hibernate 的二级缓存
缓存的目的是为了通过减少应用程序对物理数据源访问的次数来提高程序运行的效率,原理则是把当前或接下来一段时间可能会用到的数据保存到内存中,在使用时直接从内存中读取,而不是从硬盘中去读取,简单来说,缓存就是数据库中数据在内存中的「临时容器」。
在 Hibernate 中,缓存用来把从数据库中查询出来的和使用过的对象保存在内存中,以便在后期需要用到这个对象时可以直接从缓存中来获取这个对象(只有当该对象在缓存中不存在时才会去数据库中查询)。显然,由于避免了因大量发送 SQL 语句到数据库查询导致的性能损耗,缓存机制可以显著提高程序的运行效率。
在 Hibernate 中有一级缓存与二级缓存的概念,一级缓存由 Session 来管理,二级缓存由 SessionFactory 来管理。在使用时,二级缓存是可有可无的,但一级缓存是必不可少的。
一级缓存使用的场合如下:当使用 Session 查询数据时,首先会在该 Session 内部查找该对象是否存在,若存在,则直接返回,否则,就到数据库中去查询,并将查询的结果缓存起来以便后期使用。一级缓存的缺点就是当使用 Session 来表示一次会话时,它的生命周期较短,而且它是线程不安全的,不能被多个线程共享,因此,在实际使用时,对效率的提升不是非常明显。
鉴于以上原因,二级缓存的概念被引入了。二级缓存用来为 Hibernate 配置一种全局的缓存,以便实现多个线程与事务共享。在使用了二级缓存机制后,当查询数据时,会首先在内部缓存中去查找,如果不存在,接着在二级缓存中查找,最后才去数据库中查找。与一级缓存相比,二级缓存是独立于 Hibernate 的软件部件,属于第三方的产品,常见的产品有 EhCache、OSCache 和 JbossCache 等,Hibernate 3 以后默认使用的产品为 EhCache。在使用时,可以根据需求通过配置二级缓存插件来实现二级缓存功能,Hibernate 为了集成这些插件,提供了 org.hibernate.cache.CacheProvider 接口来充当缓存插件与 Hibernate 之间的适配器。当然,二级缓存除了以内存作为存储介质外,还可以选用硬盘等外部存储设备。
合理地使用 Hibernate 的二级缓存机制有助于提高系统的运行效率,但如果使用得不合理,不仅不会提高效率,反而有可能会降低系统的性能。
二级缓存一般适用于以下几种情况:
1)数据量较小。如果数据量太大,缓存太多,会消耗大量内存,造成内存资源短缺,从而降低系统的性能。
2)对数据的修改较少。如果进行大量的修改,就需要频繁地对缓存中数据与数据库中的数据进行同步,而这也会影响系统的性能。
3)不会被大量的应用共享的数据。如果数据被大量线程或事务共享,多线程访问时的同步机制也会影响系统的性能。
4)不是很重要的数据。如果查询的数据非常重要(例如财务数据),对数据的正确性要求非常高,最好不要使用二级缓存。
