1.1拦截器原理
Producer拦截器(interceptor)是在Kafka 0.10版本被引入的,主要用于实现clients端的定制化控制逻辑。对于producer而言,interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等。同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)。Intercetpor的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor,其定义的方法包括
1、configure(configs)
获取配置信息和初始化数据时调用。
2、onSend(ProducerRecord)
该方法封装进KafkaProducer.send方法中,即它运行在用户主线程中。Producer确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算
3、onAcknowledgement(RecordMetadata, Exception)
该方法会在消息被应答或消息发送失败时调用,并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率
4、close
关闭interceptor,主要用于执行一些资源清理工作,如前所述,interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全。另外倘若指定了多个interceptor,则producer将按照指定顺序调用它们,并仅仅是捕获每个interceptor可能抛出的异常记录到错误日志中而非在向上传递。这在使用过程中要特别留意。
1.2拦截器案例
实现一个简单的双 interceptor 组成的拦截链。第一个 interceptor 会在消息发送前将时间戳信息加到消息 value 的最前部;第二个 interceptor 会在消息发送后更新成功发送消息数或失败发送消息数。
时间拦截器:
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* 在记录前面加上时间戳
*/
public class TimerInterceptor implements ProducerInterceptor {
/**
* 该方法封装进 KafkaProducer.send 方法中,即它运行在用户主线程中。Producer 确保在
* 消息被序列化以及计算分区前调用该方法
* 用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的 topic 和分区,否则会影响目标分区的计算
*
* @param record
* @return
*/
public ProducerRecord onSend(ProducerRecord record) {
// 创建一个新的record,将时间戳写入记录的最前面,一个record就是一个记录
return new ProducerRecord(
record.topic(),
record.partition(),
record.timestamp(),
record.key(),
System.currentTimeMillis() + "--- " + record.value().toString());
}
/**
* 该方法会在消息被应答或消息发送失败时调用,并且通常都是在 producer 回调逻辑触
* 发之前。onAcknowledgement 运行在 producer 的 IO 线程中,因此不要在该方法中放入很重的逻辑,
* 否则会拖慢 producer 的消息发送效率
*
* @param metadata
* @param exception
*/
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
/**
* 关闭 interceptor,主要用于执行一些资源清理工作
*/
public void close() {
}
/**
* 获取配置信息和初始化数据时调用
*
* @param configs
*/
public void configure(Map<String, ?> configs) {
}
}
计数拦截器:
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
/**
* 统计发送消息成功和发送失败消息数,并在 producer 关闭时打印这两个计数器
*/
public class CounterInterceptor implements ProducerInterceptor {
private int successCount = 0;
private int errorCount = 0;
public ProducerRecord onSend(ProducerRecord record) {
return null;
}
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
// 统计失败和成功的次数
if (exception == null) {
successCount++;
} else {
errorCount++;
}
}
/**
* 在关闭的时候保留结果
*/
public void close() {
System.out.println("success sent: " + successCount);
System.out.println("error sent: " + errorCount);
}
public void configure(Map<String, ?> configs) {
}
}
Producer程序:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.ArrayList;
import java.util.Properties;
/**
* 主程序
* 需求:实现一个简单的双 interceptor 组成的拦截链。
* 第一个 interceptor 会在消息发送前将时间戳信息加到消息 value 的最前部;
* 第二个 interceptor 会在消息发送后更新成功发送消息数
*/
public class ProduceInterceptor {
public static void main(String[] args) {
// 1.设置配置信息
Properties props = new Properties();
props.put("bootstrap.servers", "hadoop102:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 2.构建拦截器
ArrayList<String> interceptors = new ArrayList<String>();
interceptors.add("com.myStudy.interceptor.TimerInterceptor");
interceptors.add("com.myStudy.interceptor.CounterInterceptor");
String topic = "first";
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);
// 3.发送消息
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<String, String>(topic, "messsage" + i);
producer.send(record);
}
// 4. 一定要关闭producer,这样才会调用interceptor的close方法
producer.close();
}
}
1.3了解Kafka Streams
Kafka Streams。Apache Kafka开源项目的一个组成部分。是一个功能强大,易于使用的库。用于在Kafka上构建高可分布式、拓展性,容错的应用程序。它建立在流处理的一系列重要功能基础之上,比如正确区分事件事件和处理时间,处理迟到数据以及高效的应用程序状态管理。
下面的列表强调了Kafka Streams的几个关键功能,使得Kafka Streams成为构建流处理应用程序、持续查询、转换和微服务等场景的新选择。
- 功能强大
高拓展性,弹性,容错
有状态和无状态处理
基于事件时间的Window,Join,Aggergations - 轻量级
无需专门的集群
没有外部以来
一个库,而不是框架 - 完全集成
100%的Kafka 0.10.0版本兼容
易于集成到现有的应用程序
程序部署无需手工处理(这个指的应该是Kafka多分区机制对Kafka Streams多实例的自动匹配) - 实时性
毫秒级延迟
并非微批处理
窗口允许乱序数据
允许迟到数据
近看Kafka Streams
在我们深入Kafka Streams的概念和架构细节以及按部就班认识Kafka Streams之前,我们先来对上面提出的列表做更多的介绍。
- 更简单的流处理:Kafka Streams的设计目标为一个轻量级的库,就像Kafka的Producer和Consumer似得。可以轻松将Kafka Streams整合到自己的应用程序中。对应用程序的额外要求仅仅是打包和部署到应用程序所在集群罢了。
- 除了Apache Kafka之外没有任何其它外部依赖, 并且可以在任何Java应用程序中使用。不需要为流处理需求额外部署一个其它集群。操作和维护团队肯定会很高兴这一点。
- 使用Kafka作为内部消息通讯存储介质,而不是像其它流处理框架似得,重新加入其它外部组件来做消息通讯。Kafka Streams使用Kafka的分区水平拓展来对数据做有序高效的处理。这样同时兼顾了高性能,高扩展性,并使操作简便。这种决策的好处是,你不必了解和调整两个不同的消息传输层(数据在不同伸缩介质中间移动和流处理的独立消息处理层),同样,Kafka的性能和高可靠性方面的改进,都会使得Kafka Streams直接受益。也可以同时借助Kafka社区强大的开发能力。
- 允许和其他资源管理和配置共聚焦集成。因此,Kafka Streams能够更加无缝的集成到现有的开发、打包、部署和业务实践当中去。你可以自由地使用自己喜欢的工具,比如java 应用服务器,Puppet, Ansible,Mesos,Yarn,Docket, 甚至在一台手工运行你自己应用程序进行验证的机器上。
- 支持本地状态容错。这样就可以进行非常高效快速的包含状态的Join和Window 聚合操作。本地状态被保存在Kafka中,在机器故障的时候,其他机器可以自动恢复这些状态继续处理。
- 每次处理一条数据以实现低延时,这对于欺诈监测等场景是至关重要的。这也是Kafka Streams和其他基于微批处理的流处理框架的不同。
此外,Kafka Streams在设计上基于丰富的开发经验,具有很强的实用性。它提供了流处理所有的必要的原语,允许应用程序从Kafka中读取流数据,处理数据并且将结果写回Kafka或者发送到其他外部系统中取。提供了高层次的比如Filter,Map,Join等DSL操作以及低级别API供开发者选择使用。
最后,Kafka Streams为拓展开发者提供帮助,它入门门槛低,开发路径平滑,你可以快速编写和运行一个小规模的应用程序进行验证,因为你完全不需要安装或者了解其他分布式流处理平台。并且只需要将应用程序部署在多个实例上就可以在大批量的生产工作中实现负载均衡。Kafka Streams透明地使用Kafka并行操作模型处理同一应用程序的多个实例来实现负载均衡。
综上所述,Kafka Streams是构建流处理应用中的一个引人注目的选择,请给它一个试用的机会,并运行你的第一个Hello World流处理程序。文档的下一章将带你开始由浅入深编写Kafka Streams应用程序。
1.4 Kafka为什么那么快?
Broker
不同于Redis和MemcacheQ等内存消息队列,Kafka的设计是把所有的Message都要写入速度低容量大的硬盘,以此来换取更强的存储能力。实际上,Kafka使用硬盘并没有带来过多的性能损失,“规规矩矩”的抄了一条“近道”。
首先,说“规规矩矩”是因为Kafka在磁盘上只做Sequence I/O,由于消息系统读写的特殊性,这并不存在什么问题。关于磁盘I/O的性能,引用一组Kafka官方给出的测试数据(Raid-5,7200rpm):
Sequence I/O: 600MB/s
Random I/O: 100KB/s
所以通过只做Sequence I/O的限制,规避了磁盘访问速度低下对性能可能造成的影响。
接下来我们再聊一聊Kafka是如何“抄近道的”。
首先,Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。
当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。同时如果有其他进程申请内存,回收PageCache的代价又很小,所以现代的OS都支持PageCache。
使用PageCache功能同时可以避免在JVM内部缓存数据,JVM为我们提供了强大的GC能力,同时也引入了一些问题不适用与Kafka的设计。
如果在Heap内管理缓存,JVM的GC线程会频繁扫描Heap空间,带来不必要的开销。如果Heap过大,执行一次Full GC对系统的可用性来说将是极大的挑战。
所有在在JVM内的对象都不免带有一个Object Overhead(千万不可小视),内存的有效空间利用率会因此降低。
所有的In-Process Cache在OS中都有一份同样的PageCache。所以通过将缓存只放在PageCache,可以至少让可用缓存空间翻倍。
如果Kafka重启,所有的In-Process Cache都会失效,而OS管理的PageCache依然可以继续使用。
PageCache还只是第一步,Kafka为了进一步的优化性能还采用了Sendfile技术。在解释Sendfile之前,首先介绍一下传统的网络I/O操作流程,大体上分为以下4步。
OS 从硬盘把数据读到内核区的PageCache。
用户进程把数据从内核区Copy到用户区。
然后用户进程再把数据写入到Socket,数据流入内核区的Socket Buffer上。
OS 再把数据从Buffer中Copy到网卡的Buffer上,这样完成一次发送。
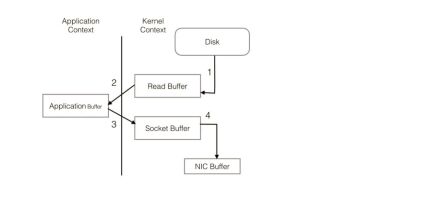
整个过程共经历两次Context Switch,四次System Call。同一份数据在内核Buffer与用户Buffer之间重复拷贝,效率低下。其中2、3两步没有必要,完全可以直接在内核区完成数据拷贝。这也正是Sendfile所解决的问题,经过Sendfile优化后,整个I/O过程就变成了下面这个样子。

