软件磁盘列阵
软件磁盘列阵(software RAID)
RAID:Redundant Array of Independent Disks.
冗余磁盘列阵
RAID级别
RAID的级别不代表性能的高低,仅仅是代表不同组成方式的编号.
RAID-0(等量模式,Stripe):能效最佳
至少需要2块硬盘
这种模式的RAID会先将磁盘切分成等量的区块(chunk,一般可设定4k~1M),然后当一个文件要写入RAID时,该文件会先根据chunk
的大小切分成若干份,然后再依序存储到磁盘.由于每个磁盘会交错的存放数据,因此当你的数据要写入RAID时,数据会被等量的放置
在各个磁盘上面.举例来说,如果你100M数据要写入时,每个磁盘存储50M.(如下图)
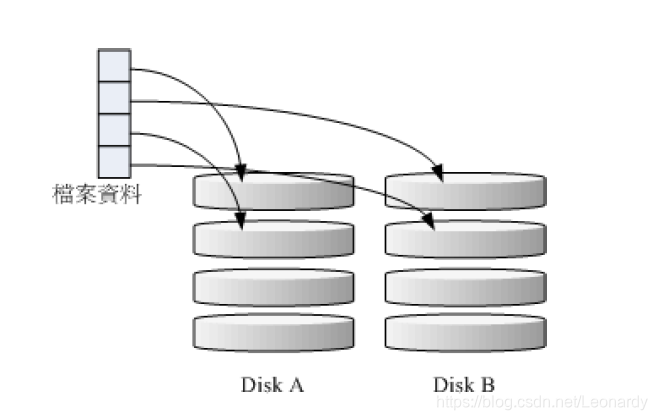
理论上来说,组成RAID-0的磁盘数量越多,能效越好,因为每个磁盘所负责的数据量变小了,此外整体的总容量也变大了.
但是带来的风险也是很大的,由于RAID-0是将文件切分成chunk然后分别存储在不同的磁盘,那么此时,只要有一块硬盘损坏
那么RAID上的所有数据都回丢失,无法读取.
另外,如果用容量不同的2块磁盘来组成RAID-0时,由于数据是等量分布的,所以当容量较小的那一块磁盘写满后,所有数据就会继续写到容量较大的那块硬盘.举例来说,有2块磁盘,分别为200G和500G的容量,那么最初的400G数据会写入到每块硬盘200G,但是后续的内容则只能都写到500G的那块硬盘.
RAID-1(镜像模式:mirror):完全备份
至少需要2块硬盘
这种模式也需要相同的磁盘容量来组成RAID,如果两块磁盘的容量不同,那么RAID的总体容量会以容量较小的那一块磁盘为主.
这种模式的原理是将同样的数据完整的写到2块磁盘中,说直白点就是数据写入时会同时写入另一块磁盘一份一模一样的内容当作备份.
因此,磁盘的整体容量利用率只有50%.
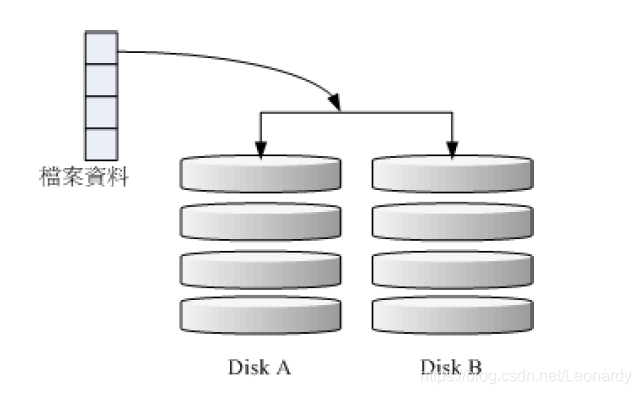
如上图所示,由于数据是被同时写入到两块不同的磁盘,那么写入的时候数据到达I/O总线后会被复制多分到各个磁盘,给人的感觉像是
数据量翻了几倍,因此写入的效率很低.如果使用的是硬件RAID,那么RAID会主动复制一份而不用系统的I/O总线,效率方面还可以.
不过这里说的是软件RAID,所以写入效率就很低了.
不过反过来,读取的效率却很快,因为同样的数据内容可以从多块磁盘同时提供。RAID-1的最大优点在于数据备份,如果RAID中的其中
一块磁盘损坏,那么可以通过另一块磁盘的数据来进行恢复.
RAID-3:
①把数据分成多个小"块"(按bit存储)存放在N+1个磁盘中。读写性能提升。
②有一块盘专门用来存储校验码,校验盘的性能可能会成为阵列瓶颈。
③至少需要3块磁盘。
④其中一块盘损坏时,可以根据校验盘以及其他的磁盘信息来进行恢复。
同时坏2块或以上磁盘,则无法正常工作。但同时坏2块磁盘的几率较小,所以数据安全性相对较高。
⑤磁盘利用率N-1/N。
RAID-4:
①与RAID3相似,也是将数据分成多个块(按数据块存储),读写性能提升。
②有一块盘校验盘,用来存储其他所有盘的奇偶校验码,校验盘的性能可能会成为阵列瓶颈。
③至少需要3块磁盘。
④其中一块盘损坏时,可以根据校验盘以及其他的磁盘信息来进行恢复。
但是相较RAID3,数据恢复难度比较大。
⑤磁盘利用率(N-1)/N。
RAID-5:能效于数据备份的均衡考虑
至少需要3块硬盘
有点类似RAID-0,不过每个循环的写入过程,都会加入一个同位检查数据(Parity),整个数据会记录其他磁盘的备份数据,如下图.

因此磁盘利用率为(N-1)/N,而当RAID-5中2块磁盘损坏时,数据便无法恢复,因为RIAD-5仅支持1块磁盘损坏.
RAID-6
在RIAD-5的基础上还有一种RAID-6模式,只不过它使用2块磁盘的容量作为Parity,因此,可以允许2块磁盘损坏.
RAID1+0,RAID0+1
至少需要4块硬盘
就像上面所提到的,RAID-0效率很高,但是不安全,而RAID-1比较安全,但是效率却很低,那么有没有一个即安全效率又高的模式呢?
这就是我们所说的RAID1+0和RAID0+1了.
RAID0+1
所谓RAID0+1其实就是先组成RIAD-0,在组曾RAID-1了.具体看下图:
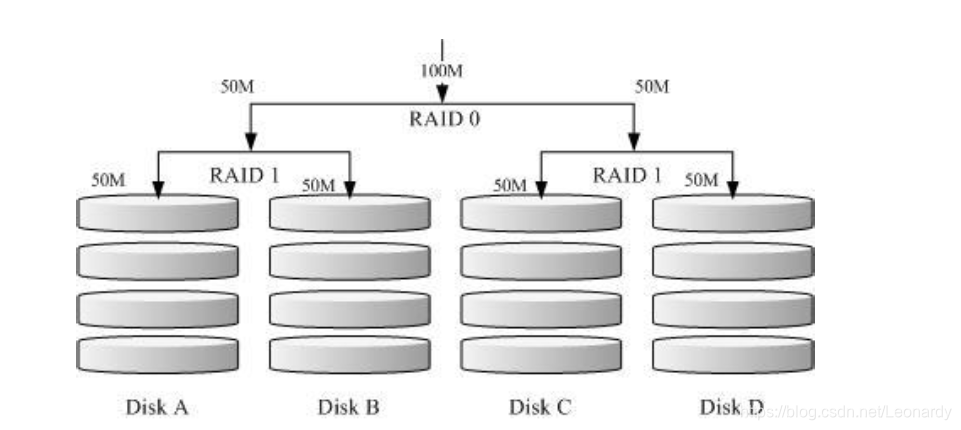
如图所示,DiskA和DiskB组成了RAID-1,同样DiskC于DiskD组成另一组RAID-1.此为先组成了RAID-1,接下来再又这两组RAID-1组成
RAID-0的形式,那么这就是RAID1+0了.
来解释一下它的存储流程,当100M的数据要写入时,(先按照chunk切分好后)平均分给两组磁盘每组50M,这样每组磁盘处理的数据量
就变小了,这就是RAID-0的过程,接下来每组的这50M数据又会被完全写入到DiskA,DiskB(另外50M写入到DISKC和DICKD中)这也就是
RAID-1的过程.这种方式数据先经过RAID-0,所以处理速度会随着RAID-0的组成数量而直线加快,而由于每组RAID-1又都是独立的,
所以其中任意一块磁盘损坏时,可由自己组内的另一块来进行恢复,不影响其他组.
Spare Disk:预备磁盘
当RAID中磁盘损坏时,就要将损坏的磁盘拔除,然后换一颗新的磁盘,当上新的磁盘并顺利启动RAID后,RAID就会主动重建
(rebuild)损坏的那块磁盘的数据到新换的磁盘上,这样数据就得到了恢复,这就是RAID的好处.不过这要求我们要插拔磁盘,除非
系统支持热插拔,否则就要关机来操作.
因此为了让系统可以实时的在磁盘损坏时主动重建,我们就需要预备磁盘(Spare Disk)的辅助,其实所谓的Spare Disk,就是
在RAID中多以块或者多块没有被包含在RAID中等级中的磁盘,这些磁盘平时不会被使用,但是一旦有磁盘损坏,Spare Disk就会被主
的拉到RAID中,并将损坏的那块磁盘从RAID中移除,然后立即开始重建.
RAID的优点
1.数据的安全与可靠性:这里只的并不是网络信息安全,而是在当有磁盘发生损坏时,可以自动重建,并恢复数据.
2.读写能效:例如RAID-0,可以加强读写能效.
3.容量:可以让多块磁盘组合起来,因此单一的文件系统可以有更大的容量.
| 项目 | RAID0 | RIAD1 | RAID10 | RAID5 | RAID6 |
|---|---|---|---|---|---|
| 最少磁盘数 | 2 | 2 | 4 | 3 | 4 |
| 最大容错磁盘数 | 无 | n-1 | n/2 | 1 | 2 |
| 数据安全性 | 完全没有 | 最佳 | 最佳 | 好 | 比RAID5好 |
| 理论写入能效 | n | 1 | n/2 | <n-1 | <n-2 |
| 可用容量 | n | 1 | n/2 | n-1 | n-2 |
| 一般用途 | 强调效率 不考虑数据安全 |
资料与备份 | 服务器,云系统常用 | 资料与备份 | 资料与备份 |
software,hardware RAID
所谓的硬件磁盘列阵(hardware RAID)是通过RAID卡来达成数组的目的.RAID卡上面有一块专门的芯片来处理RAID的任务,因此在效率方面会比较好.在很多任务(比如RAID5的Parity检查计算)并不会重复消耗原本系统的I/O总线,理论上效率会更高.此外,现在一般的RAID卡都支持热插拔,所以在数据安全行上面也很有效.不过RAID卡的价格比较高,因此就发展出利用软件RAID来模拟硬件RAID的功能,这就是所谓的software RAID.
由于软件RAID主要是通过软件来模拟RAID,因此会对CPU以及I/O总线的资源有所消耗,不过目前的计算机运算速度越来越快,这些消耗已经不是显得特别吃紧.
以CentOS为例,是以mdadm提供RAID的,它以partition或disk为磁盘单位,也即是说不需要2块以上磁盘,只要有2个以上的分区就可以设计RAID了.
由于RAID是仿真的,所以使用的是系统的设备文件名,如/dev/md0,/dev/md1等.
软件RAID的设定
软件RAID的设定是通过mdadm命令
mdadm --detail /dev/md0
mdadm --create /dev/md[0-9] --auto=yes --level=[015] --chunk=NK\
> --raid-devices=N --spare-devices=N /dev/sdx /dev/hdx...
| 选项 | 意义 |
|---|---|
| –create | 为建立RAID的选项 |
| –auto=yes | 创建设备文件,并分配一个未使用得设备号 |
| –chunk=Nk | 设置chunk得大小,也可以当作是stripe的大小,一般是64k或512k |
| –raid-devices=N | 使用几个磁盘或分区作为RAID |
| –spare-devices=N | 使用几个磁盘作为备用磁盘 |
| –level=[015] | 设定RAID的等级,有很多等级,但是一般常用的为0,1,5. |
| –detail | 显示RAID的详细信息 |
以mdadm设置RAID
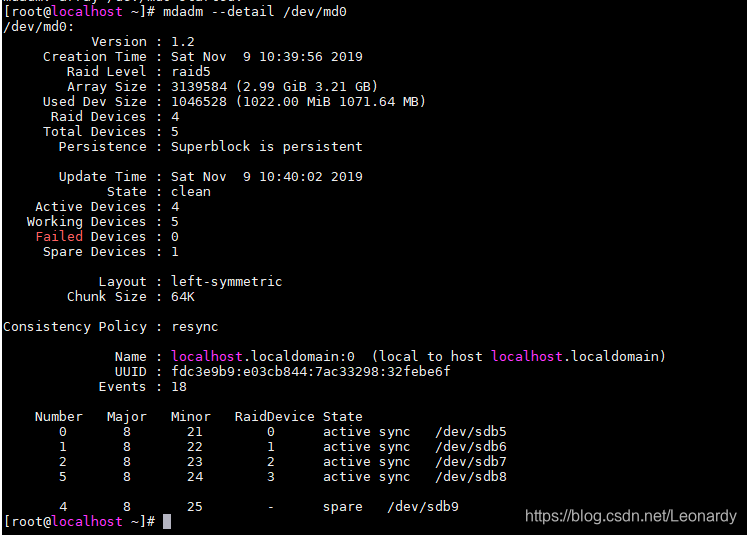
# 创建5个分区,然后利用他们创建一个RAID5,其中4个分区组成RAID5另外一个分组当作spare disk,并分配chunk大小为64KB.
# 这里要注意的是,指定chunk size时,单位要大写,K,M,G.
mdadm --create /dev/md0 --auto=yes --level=5 --chunk=64K --raid-devices=4 --spare-devices=1 /dev/sdb{5,6,7,8,9}

# 查看刚才创建的RAID信息
mdadm --detail /dev/md0
除了使用命令之外,还可以通过/proc/state文件,来查看RAID信息:
cat /proc/mdstate

上面第二行信息比较重要:
首先告诉我们,md0是raid5,并且使用了sdb{8,7,6,5}4个分区,每个分区后面的[]中的数字代表该分许再RAID中的顺序;
sdb9后面的(S)代表spare disk.
接下来告诉我们有3139584个block(每个block的大小为1k),所以总容量为3G,使用RAID5等级,chunk大小为64K,
使用algorithm 2 算法。[n/m]表示需要n个装置,其中有m个装置正在正常运行.后面的[UUUU],U表示正常运行,_则代表不正常.
格式化与挂载RAID
格式化:
下面以xfs文件系统做演示(从CentOS7.X开始,默认文件系统格式为xfs)
# -f: force 如果该RAID已经指定文件系统格式,也会强制重新格式化
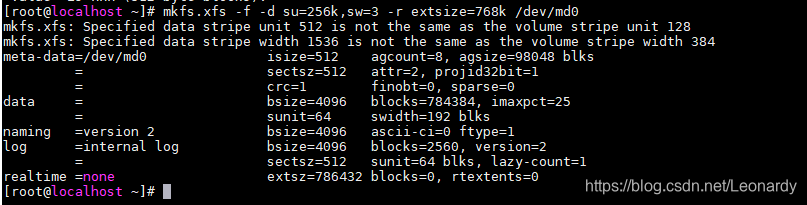
# -d:data section options,可以接一些其他的参数这里用到了下面su和sw,多个参数用【,】分割。
# su:strip unit size,条带单元的大小,必须为文件系统block size的倍数.
# sw: strip width,条带宽度,即有几个strip unit
mkfs.xfs -f -d su=256K,sw=3 -r extsize=768k /dev/md0
挂载:
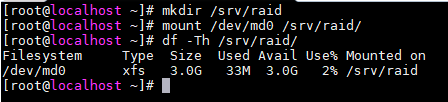
# 将md0挂载到/srv/raid目录上
mkdir /srv/raid
mount /dev/md0 /srv/raid
df -Th /srv/raid
模拟RAID的错误救援模式
# 基本操作语法
mdadm --manage /dev/md[0-9] [--add 设备] [--remove 设备] [--fail 设备]
| 选项 | 意义 |
|---|---|
| –add | 将设备添加到RAID中 |
| –remove | 将设备从RAID中移除 |
| –fail | 将设备设置成出错状态 |
首先我们服制一些内容到/srv/raid目录.

下面,我们假设/dev/sdb8这个分区除了错误,实际模拟方式如下:
# 让/dev/sdb8变成错误状态
mdadm --manage /dev/md0 --fail /dev/sdb8
注:要在上面命令完全结束之前,迅速的输入下面的命令,来查看RAID信息,否则只能查看到最后替换完成的结果了.
mdadm --detail /dev/md0
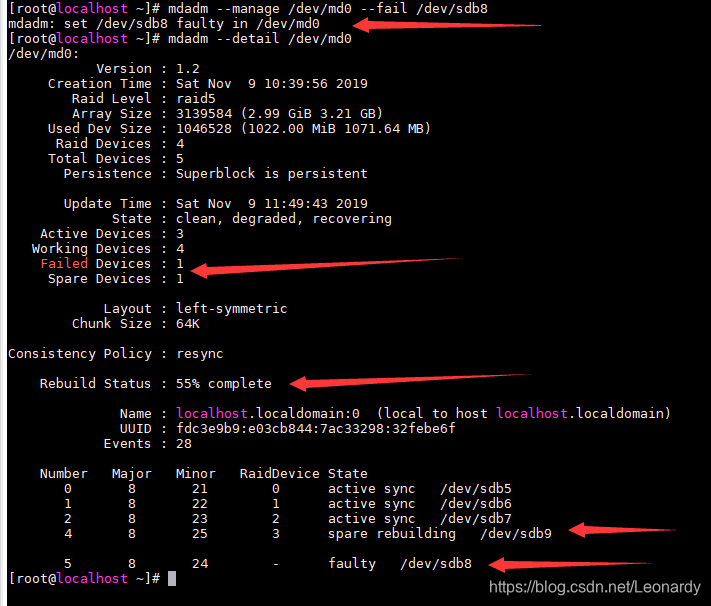
看上面的信息,发现有一个设备出错,1个备用设备,正在Rebuild中,目前Rebuild完成了55%,下面具体显示的是出错分区的信息和正在rebuilding的分区信息,待rebuilding结束后,就会是下面的状态了:

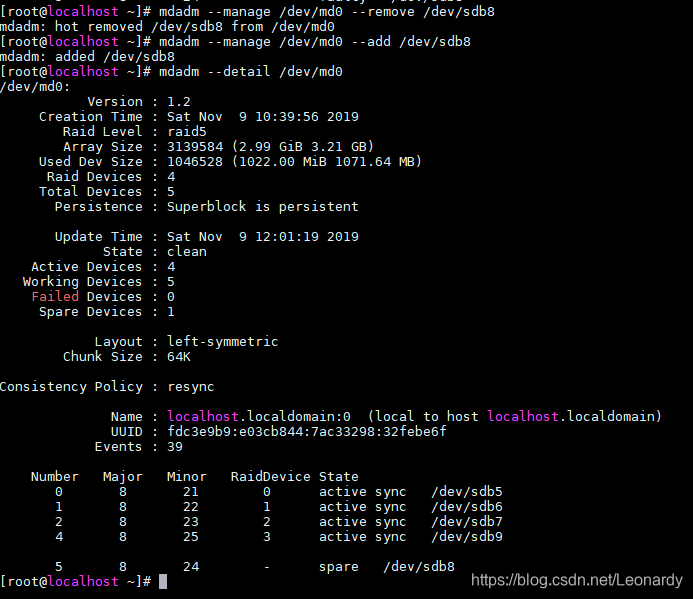
看,已经没有spare disk了,因为它已经代替了上面出错的那块分区.
接下来我们将发生错误的拿个分区从RAID中移除,并要再加入一块spare disk,否则再出错岂不是大事不妙.
mdadm --manage /dev/md0 --remove /dev/sdb8
由于我们只是模拟的出错状态,其实/dev/sdb8这个分区并没有发生错误,所以我们再将它添加会RAID.
mdadm --manage /dev/md0 --add /dev/sdb8
开机自动启动RAID并自动挂载
新的发行版,大多数会自动搜寻/dev/md[0-9]然后在开机的时候自动设定.但是还是建议大家修改一下配置文件.
software RAID的配置文件再/etc/mdadm.conf,这里配置很简单,只要知道/dev/md0的UUID就能轻松配置.
# 查询/dev/md0的UUID
mdadm --detail /dev/md0 | grep -i uuid

接下来配置/etc/mdadm.conf文件(需要新建)

注:书中讲述的不是特别详细,实际上,/etc/mdadm.conf 是RAID的配置文件,只有配置了此文件才能正常用 mdadm -A 来启动RAID. 而只有先将RAID启动之后才能mount 设备到其他路径.
接下来配置/etc/fstab .

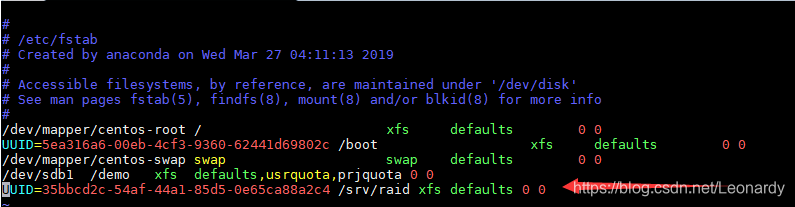
最后就可以使用mount -a 来挂载raid了.

关闭RAID
由于软件RAID会使用系统分区,所以以后如果你不想再使用此RAID了,要先将其卸载,然后再关闭RAID.
# 先卸载 /dev/md0
umount /dev/md0
# 接下来,vim /etc/fstab,将相关的RAID信息删除.
# 再接下来,覆盖掉RAID的metadata以及XFS的superblock,并停掉RAID
dd if=/dev/zero of=/dev/md0 bs=1M count=50
mdadm --stop /dev/md0
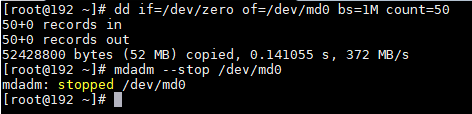
看,这回没有/dev/md0了.

由于之前RAID创建时,相关的数据会被写到磁盘中,所以如果只是移除了配置文件,停止了RAID,但是之前的分区没有被重新划分过,那么当系统重启时,RAID还是会被建立起来,只是名称可能会变成/dev/md127,所以也要把这几个分区的superblock信息覆盖掉.不过注意千万别将目标路径写错....否则....你懂的.
dd if=/dev/zero of=/dev/sdb5 bs=1M count=10
dd if=/dev/zero of=/dev/sdb6 bs=1M count=10
dd if=/dev/zero of=/dev/sdb7 bs=1M count=10
dd if=/dev/zero of=/dev/sdb8 bs=1M count=10
dd if=/dev/zero of=/dev/sdb9 bs=1M count=10
最后将/etc/mdadm.conf 中的设备注册信息也删除.
