【实习周记】ArrayMap源码分析
一.概述
ArrayMap是Android专门针对内存优化而设计的,用于取代Java API中的HashMap数据结构。
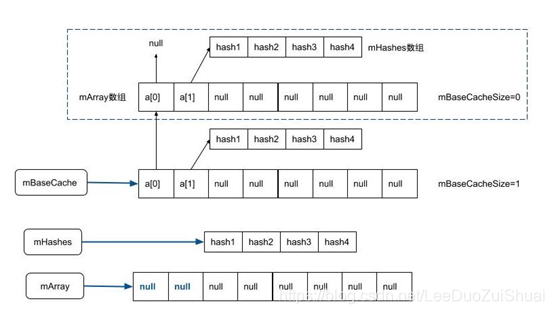
内部通过两个数组实现,存储结构如下
二.主要方法的源码分析
1.重要字段
(1).private static final int BASE_SIZE = 4; // 容量增量的最小值
(2).private static final int CACHE_SIZE = 10; // 缓存数组的上限
(2).static Object[] mBaseCache; //用于缓存大小为4的ArrayMap
(3).static int mBaseCacheSize; // 记录大小为4的ArrayMap的缓存数量
(4).static Object[] mTwiceBaseCache; //用于缓存大小为8的ArrayMap
(5).static int mTwiceBaseCacheSize; // 记录大小为8的ArrayMap的缓存数量
(6).final boolean mIdentityHashCode; //默认false
(7).int[] mHashes; //由key的hashcode所组成的数组
(8).Object[] mArray; //由key-value对所组成的数组,是mHashes大小的2倍
(9).int mSize; //成员变量的个数
2.构造方法
创建ArrayMap对象时可以指定ArrayMap的长度,默认长度为0。
public ArrayMap(int capacity, boolean identityHashCode) {
mIdentityHashCode = identityHashCode;
if (capacity < 0) {
mHashes = EMPTY_IMMUTABLE_INTS;
mArray = EmptyArray.OBJECT;
} else if (capacity == 0) {
mHashes = EmptyArray.INT;
mArray = EmptyArray.OBJECT;
} else {
//分配内存
allocArrays(capacity);
}
mSize = 0;
}
(1).内存分配
private void allocArrays(final int size) {
if (size == (BASE_SIZE*2)) {
//当分配大小为8的对象,先查看缓存池
synchronized (ArrayMap.class) {
// 当缓存池不为空时
if (mTwiceBaseCache != null) {
final Object[] array = mTwiceBaseCache;
//从缓存池中取出mArray
mArray = array;
//将缓存池指向上一条缓存地址
mTwiceBaseCache = (Object[])array[0];
//从缓存中mHashes
mHashes = (int[])array[1];
//清空缓存
array[0] = array[1] = null;
//缓存池大小减1
mTwiceBaseCacheSize--;
return;
}
}
//当分配大小为4的对象,原理同上
} else if (size == BASE_SIZE) {
synchronized (ArrayMap.class) {
if (mBaseCache != null) {
final Object[] array = mBaseCache;
mArray = array;
mBaseCache = (Object[])array[0];
mHashes = (int[])array[1];
array[0] = array[1] = null;
mBaseCacheSize--;
return;
}
}
}
// 分配大小除了4和8之外的情况,则直接创建新的数组
mHashes = new int[size];
mArray = new Object[size<<1];
}
3.put方法
public V put(K key, V value) {
//osize记录当前map大小
final int osize = mSize;
final int hash;
int index;
if (key == null) {
hash = 0;
index = indexOfNull();
} else {
//获取hashCode
hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();
//采用二分查找法,从mHashes数组中查找值等于hash的key
index = indexOf(key, hash);
}
//若index大于零,说明在mHashes中key存在,所以用新的value覆盖旧的value
if (index >= 0) {
//index的2倍+1所对应的元素存在相应value的位置
index = (index<<1) + 1;
final V old = (V)mArray[index];
mArray[index] = value;
return old;
}
//当index<0,说明是新的键值对,对index进行加一取相反数作为新的键值对的位置
index = ~index;
//当mSize大于或等于mHashes数组长度时,需要扩容
if (osize >= mHashes.length) {
final int n = osize >= (BASE_SIZE*2) ? (osize+(osize>>1))
: (osize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
//进行内存分配
allocArrays(n);
//由于ArrayMap并非线程安全的类,不允许并行,如果扩容过程其他线程
//mSize则抛出异常
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
if (mHashes.length > 0) {
//将原来老的数组拷贝到新分配的数组
System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);
System.arraycopy(oarray, 0, mArray, 0, oarray.length);
}
//释放内存
freeArrays(ohashes, oarray, osize);
}
//当需要插入的位置不在数组末尾时,需要将index位置后的数据通过拷贝往后移动一位
if (index < osize) {
System.arraycopy(mHashes, index, mHashes, index + 1, osize - index);
//这里,index+1比index大1,但是<<1操作扩大二倍后,就相差2了
//所以不是从index<<1到(index+2)<<1
System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);
}
if (CONCURRENT_MODIFICATION_EXCEPTIONS) {
if (osize != mSize || index >= mHashes.length) {
throw new ConcurrentModificationException();
}
}
//将hash、key、value添加相应数组的位置,数据个数mSize加1
mHashes[index] = hash;
mArray[index<<1] = key;
mArray[(index<<1)+1] = value;
mSize++;
return null;
}
(1).二分查找
indexOfNull和indexOf方法内部主要通过binarySearch实现,并对返回值进行了一些处理。
static int binarySearch(int[] array, int size, int value) {
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
final int mid = (lo + hi) >>> 1;
final int midVal = array[mid];
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
return mid;
}
}
return ~lo;
}
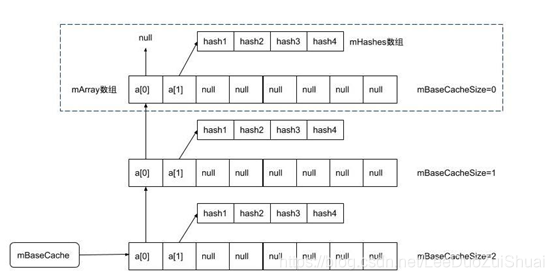
(2).内存释放
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {
//当释放的是大小为8的对象
if (hashes.length == (BASE_SIZE*2)) {
synchronized (ArrayMap.class) {
// 当大小为8的缓存池的数量小于10个,则将其放入缓存池
if (mTwiceBaseCacheSize < CACHE_SIZE) {
//array[0]指向原来的缓存池
array[0] = mTwiceBaseCache;
//array[1]存储hash数组
array[1] = hashes;
//清空其他数据
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
//mTwiceBaseCache指向新加入缓存池的array
mTwiceBaseCache = array;
//缓存池大小加1
mTwiceBaseCacheSize++;
}
}
//当释放的是大小为4的对象,原理同上
} else if (hashes.length == BASE_SIZE) {
synchronized (ArrayMap.class) {
if (mBaseCacheSize < CACHE_SIZE) {
array[0] = mBaseCache;
array[1] = hashes;
for (int i=(size<<1)-1; i>=2; i--) {
array[i] = null;
}
mBaseCache = array;
mBaseCacheSize++;
}
}
}
}
4.get方法
public V get(Object key) {
//根据key找到index,并返回相应值
final int index = indexOfKey(key);
return index >= 0 ? (V)mArray[(index<<1)+1] : null;
}
(1).indexOfKey
public int indexOfKey(Object key) {
return key == null ? indexOfNull()
: indexOf(key, mIdentityHashCode ? System.identityHashCode(key) : key.hashCode());
}
可以看出indexOfKey内部通过调用indexOfNull和indexOf实现,核心也是通过二分查找实现。
5.remove方法
public V remove(Object key) {
final int index = indexOfKey(key);
if (index >= 0) {
return removeAt(index);
}
return null;
}
remove内部调用indexOfKey,把key转换为index,最后委派给removeAt处理。
(1).removeAt
public V removeAt(int index) {
final Object old = mArray[(index << 1) + 1];
final int osize = mSize;
final int nsize;
//当被移除的是ArrayMap的最后一个元素
if (osize <= 1) {
//释放内存
freeArrays(mHashes, mArray, osize);
mHashes = EmptyArray.INT;
mArray = EmptyArray.OBJECT;
nsize = 0;
} else {
nsize = osize – 1;
if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {
final int n = osize > (BASE_SIZE*2) ? (osize + (osize>>1)) : (BASE_SIZE*2);
final int[] ohashes = mHashes;
final Object[] oarray = mArray;
allocArrays(n); //内存收缩
//禁止并发
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
if (index > 0) {
System.arraycopy(ohashes, 0, mHashes, 0, index);
System.arraycopy(oarray, 0, mArray, 0, index << 1);
}
if (index < nsize) {
System.arraycopy(ohashes, index + 1, mHashes, index, nsize - index);
System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,
(nsize - index) << 1);
}
} else {
if (index < nsize) { //当被移除的元素不是数组最末尾的元素时,则需要将后面的数组往前移动
System.arraycopy(mHashes, index + 1, mHashes, index, nsize - index);
System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,
(nsize - index) << 1);
}
//再将最后一个位置设置为null
mArray[nsize << 1] = null;
mArray[(nsize << 1) + 1] = null;
}
}
if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {
throw new ConcurrentModificationException();
}
mSize = nsize; //大小减1
return (V)old;
}
三.总结
1.缓存机制——内存分配(allocArrays)和内存释放(freeArrays)
(1).allocArrays触发时机:
当执行ArrayMap的构造函数的情况
当执行removeAt()在满足容量收紧机制的情况
当执行ensureCapacity()在当前容量小于预期容量的情况下, 先执行allocArrays,再freeArrays
当执行put()在容量满的情况下, 先执行allocArrays, 再执行freeArrays
(2).freeArrays()触发时机:
当执行removeAt()移除最后一个元素的情况
当执行clear()清理的情况
当执行ensureCapacity()在当前容量小于预期容量的情况下, 先执行allocArrays,再freeArrays
当执行put()在容量满的情况下, 先执行allocArrays, 再执行freeArrays
2.扩容机制——容量扩张(put)和容量收缩(removeAt)
(1).容量扩张:put
触发:当mSize大于或等于mHashes数组长度时扩容
当map个数满足条件 osize<4时,则扩容后的大小为4;
当map个数满足条件 4<= osize < 8时,则扩容后的大小为8;
当map个数满足条件 osize>=8时,则扩容后的大小为原来的1.5倍;
可见ArrayMap大小在不断增加的过程,size的取值为4,8,12,18,27,40,60,……
(2).容量收缩:removeAt
触发:当数组内存的大小大于8,且已存储数据的个数mSize小于数组空间大小的1/3时,收缩
当mSize<=8,则设置新大小为8;
当mSize> 8,则设置新大小为mSize的1.5倍。
在数据较大的情况下,当内存使用量不足1/3的情况下,内存数组会收紧50%。
