分布式事务的简介
1. 事务简单介绍
事务是指一组通常包含对数据进行读或写操作的动作集合。
事务的目的:1.如果事务失败了,返回事务之前的状态的。
2.事务在并发操作时,进行一个隔离操作,避免事务之间的相互干扰。
通常事务具有以下四个特性:
-
原子性(Atomicity):事务中所有操作是不可再分割的原子单元。事务中所有操作要么都执行成功,要么都执行失败。
-
一致性(Consistency):事务执行后,数据库状态与其他业务规则保持一致。如转账业务,无论事务执行成功与否,参与转账的两个账户余额之和应该保持不变。
-
隔离性(Isolation): 隔离性是指在并发操作中,不同事务之间应该隔离开来,使每个并发中的事务不会互相干扰。
-
持久性(durability):一旦事务提交成功,事务中所有的数据操作都必须被持久化保存到数据库中,即使提交事务后,数据库崩溃,在数据库重启时,也必须能保证通过某种机制恢复数据。
2.事务存在的问题以及隔离设置
事务因为并发产生的问题:
脏读:一个事务读取到了另外一个事务没有提交的数据
事务1:更新一条数据
------------->事务2:读取事务1更新的记录
事务1:调用commit进行提交
***此时事务2读取到的数据是保存在数据库内存中的数据,称为脏读。
***读到的数据为脏数据
详细解释:
脏读就是指:当一个事务正在访问数据,并且对数据进行了修改,
而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,
然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个
事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
不可重复读:在同一事务中,两次读取同一数据,得到内容不同
事务1:查询一条记录
-------------->事务2:更新事务1查询的记录
-------------->事务2:调用commit进行提交
事务1:再次查询上次的记录
***此时事务1对同一数据查询了两次,可得到的内容不同,称为不可重复读
幻读:同一事务中,用同样的操作读取两次,得到的记录数不相同
事务1:查询表中所有记录
-------------->事务2:插入一条记录
-------------->事务2:调用commit进行提交
事务1:再次查询表中所有记录
***此时事务1两次查询到的记录是不一样的,称为幻读
详细解释:
幻读是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的
数据进行了修改,这种修改涉及到表中的全部数据行。
同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。
那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,
就好象发生了幻觉一样。
| 隔离级别 | 作用 | 性能 |
|---|---|---|
| Serializable(串行化) | 避免脏读、不可重复读和幻读 | 低 |
| Repeatable(可重复读) | 避免脏读、不可重复读 | 中 |
| Read committed(读已提交) | 避免脏读【系统默认隔离级别】 | 较高 |
| Read uncommitted(读未提交) | 无法保证 | 高 |
3.分布式事务简介
我们知道了事务是什么后,于是引出了分布式事务的概念。所谓的分布式事务就是:事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。
简单点理解就是: 一个在不同环境(比如不同的数据库、不同的机器上)下运行的业务,并且这些操作又需要在同一个事务中完成。
加州大学伯克利分校 Eric Brewer教授提出一个分布式系统特性具CAP理论:
在分布式系统中,是不存在同时满足一致性 Consistency、可用性 Availability和分区容错性 Partition Tolerance三者的。在绝大多数的场景,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证最终一致性即可。
-
Consistency(一致性)
强一致性就是在客户端任何时候看到各节点的数据都是一致的(All nodes see the same data at the same time)。 -
Availability(可用性)
高可用性就是在任何时候都可以读写(Reads and writes always succeed)。 -
Partition tolerance(分区容错性)
分区容错性是在网络故障、某些节点不能通信的时候系统仍能继续工作(The system continue to operate despite arbitrary message loss or failure of part of the the system)。以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
CAP理论告诉我们一致性、可用性和分区容错性是不能同时满足的。那么问题来了,我们要如何进行三选二?
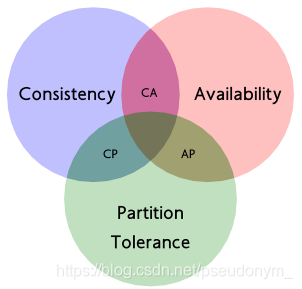
组合选择如下:
| 组合 | 评价 |
|---|---|
| CA | 放弃分区容错性,加强一致性和可用性,其实就是传统的单机数据库的选择 |
| AP | 放弃一致性(这里指强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多NoSQL系统就是如此 |
| CP | 放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用 |
4.BASE理论
Base理论简介:BASE是Basically Available(基本可用)、Soft state(柔软状态)和Eventually consistent(最终一致性)三个短语的简写,BASE是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于CAP定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
- 基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性——但请注意,这绝不等价于系统不可用,以下两个就是“基本可用”的典型例子。
<1>响应时间上的损失:正常情况下,一个在线搜索引擎需要0.5秒内返回给用户相应的查询结果,但由于出现异常(比如系统部分机房发生断电或断网故障),查询结果的响应时间增加到了1~2秒。
<2>功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
- 柔软状态
柔软状态也被称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据听不的过程存在延时。
- 最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
最终一致性分为以下5种:
| 种类 | 说明 |
|---|---|
| 因果一致性(Causal consistency) | 如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。于此同时,和节点 A 无因果关系的节点 C 的数据访问则没有这样的限制。 |
| 读己之所写(Read your writes) | 节点 A 更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。 |
| 会话一致性(Session consistency) | 会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。 |
| 单调读一致性(Monotonic read consistency) | 单调读一致性是指如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。 |
| 单调写一致性(Monotonic write consistency) | 一个系统要能够保证来自同一个节点的写操作被顺序的执行。 |
在实际的实践中,这 5 种系统往往会结合使用,以构建一个具有最终一致性的分布式系统。实际上,不只是分布式系统使用最终一致性,关系型数据库在某个功能上,也是使用最终一致性的,比如备份,数据库的复制过程是需要时间的,这个复制过程中,业务读取到的值就是旧的。当然,最终还是达成了数据一致性。这也算是一个最终一致性的经典案例。
总结:BASE理论面向的是大型高可用可扩展的分布式系统,和我们传统的ACID型事务是背道而驰的。传统ACID事务要求的是强一致性,而分布式系统则是通过牺牲强一致性来换取可用型,允许数据在某较短的时间内不一致,当然分布式系统也是要保证数据的最终一致性。
