此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
本文章纯野生,无任何借鉴他人文章及抄袭等。坚持原创!!
前言
你好。这里是Python爬虫从入门到放弃系列文章。我是SunriseCai。
使用Python爬虫就是以下三个步骤,一个步骤对应一篇文章。
- 请求网页
- 获取网页响应,解析数据(网页)
- 保存数据 (未完成)
本文章就介绍Python爬虫的第二步:解析网页。
- 主要介绍从HTML文件中提取数据,换句话说就是解析网页。本文章主要介绍以下三种解析网页的方式:
查看一下本文章所介绍的三款网页解析方式的区别。
| 方法 | 描述 |
|---|---|
| BeautifulSoup | 一个可以从HTML或XML文件中提取数据的Python库 |
| XPath | 在XML文档中查找信息的语言 |
| 正则表达式(re) | 一个特殊的字符序列,它能方便的检查一个字符串是否与某种模式匹配。 |
这里主要介绍一下他们的基本使用,其它更为详细的建议点击上方的链接去系统的学习。
安装模块
首先,需要在cmd窗口输入一下命令,安装本文章所使用到的 bs4 和 lxml 模块。
pip install beautifulsoup4
pip install lxml
1) BeautifulSoup
BeautifulSoup是一款功能非常强大的数据处理工具,它有着四大种类,遍历文档书,搜索文档书,CSS选择器等操作,这里只对它的四大种类以及基本使用做一下简单的介绍。
1.1 BeautifulSoup4四大对象种类
BeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
| 种类 | 描述 |
|---|---|
| Tag | 理解为HTML中的各个标签 |
| NavigableString | 获取标签内的文字 |
| BeautifulSoup | 表示文档的全部内容 |
| Comment | 过滤注释后的获取标签内文字 |
1.2 BeautifulSoup 基本使用示例
首先,导入BeautifulSoup模块。

from bs4 import BeautifulSoup
这里上一段操作示例HTML代码:
html_doc = '''
<html>
<body>
<div id='nothing'>
<ul>
<li class="animal">
<a href="www.animal.html" class='one'>小狗</a>
</li>
<li class="fruits">
<a href="www.fruits.html" class='two'>水果</a>
</li>
<li class="vegetable">
<a href="www.vegetable.html class='three'">白菜</a>
</li>
</ul>
</div>
</body>
</html>
'''
创建BeautifulSoup对象:
soup = BeautifulSoup(html_doc,'lxml')
基本使用示例:
soup = BeautifulSoup(open("index.html")) # 创建一个文件句柄的BeautifulSoup对象
soup = BeautifulSoup("<html>data</html>") # 创建一段字符串的BeautifulSoup对象
print(soup.prettify()) # 格式化输出soup对象
print(soup.li) # 获取第一个li标签的内容
print(soup.div) # 获取第一个div标签的内容
print(soup.find('a')) # 获取文档中第一个 <a> 标签
print(soup.find_all('a')) # 获取文档中所有 <a> 标签
print(soup.a.string) # 获取a标签的文字内容
print(soup.get_text()) # 获取文档中所有的文字内容
......
'太多太多的示例无法一一例举,用1万字去写它都不够。'
1.3 BeautifulSoup 四大种类示例
以下示例引用自BeautifulSoup官方文档。但是引用的不完全,建议阅读官方文档进行系统的学习。
1.3.1 Tag
Tag:
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>','lxml')
tag = soup.a
type(tag) # <class 'bs4.element.Tag'>
- Tag有很多方法和属性,现在介绍一下tag中最重要的属性:name和attributes
name:
# 通过 .name 来获取tag的名字
print(tag.name) # 'a'
# 改变tag的name
tag.name = "blockquote"
print(tag) # <blockquote href="www.animal.html">小狗</blockquote>
attributes:
# 一个tag可能有很多个属性 .tag <b class="boldest"> 有一个 "class" 的属性,值为 "boldest"
print(tag['class']) # ['one']
# 也可以直接"点"取属性, 比如: .attrs
print(tag.attrs) # {'href': 'www.animal.html', 'class': ['one']}
--------------------------------------------------------------------
# tag的属性可以被添加,删除或修改。tag的属性操作方法与字典一样
tag['class'] = 'verybold'
tag['id'] = 1
print(tag) # <a class="verybold" href="www.animal.html" id="1">小狗</a>
del tag['class'] # 删除'class'
del tag['id'] # 删除'id'
print(tag) # <a href="www.animal.html">小狗</a>
print(tag['class']) # KeyError: 'class'
print(tag.get('class')) # None
1.3.2 NavigableString
- 上面的操作是获取标签的所有内容,现在用**NavigableString **来获取标签里边包含的文字。
# 用.string 即可获取标签内部的文字
soup = BeautifulSoup(html_doc,'lxml')
print(soup.a.string) # 小狗
print(type(soup.a.string)) # <class 'bs4.element.NavigableString'>
1.3.3 BeautifulSoup
- BeautifulSoup 对象表示的是一个文档的全部内容,大部分时候,可以把它当作 Tag 对象。
soup = BeautifulSoup(html_doc,'lxml')
print(soup.name) # [document]
1.3.4 Comment
- Comment 对象是一个特殊类型的 NavigableString 对象,它输出的内容是过滤掉注释符号的
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup,'lxml')
comment = soup.b.string
print(comment) # Hey, buddy. Want to buy a used parser?
print(type(comment)) # <class 'bs4.element.Comment'>
这是你想要的吗?我可以保证不是,但是请别着急,官方文档更好用,点击直达BeautifulSoup官方文档。
2) XPath(XML Path Language)
2.1 XPath 介绍
XPath即为XML路径语言(XML Path Language),是一门在 XML 文档中查找信息的语言。这里对XPath的基本使用做一个介绍,建议移步到XPath教程,系统的学习XPath。
下面是最有用的路径表达式:
| 表达式 | 用法 | 描述 |
|---|---|---|
| nodename | xpath(‘//div’) | 选取此节点的所有子节点。 |
| / | xpath(‘/div’) | 从根节点选取。 |
| // | xpath(‘//div’) | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | xpath(‘./div’) | 选取当前节点。 |
| .. | xpath(‘..’) | 选取当前节点的父节点。 |
| @ | xpath(’/@calss’) | 选取属性。 |
2.2 XPath 基本使用示例
首先是导入模块etree,模块在上面已经安装了,利用XPath进行HTML的解析。
from lxml import etree
etree模块是可以对文本进行补全修正的,用etree.tostring()或者etree.tostringlist(),但是这里的重点不是说它。
下面是用XPath解析网页的相关实例代码:
html_doc = '''
<html>
<body>
<div id='nothing'>
<ul>
<li class="animal">
<a href="www.animal.html" class='one'>小狗</a>
</li>
<li class="fruits">
<a href="www.fruits.html" class='two'>水果</a>
</li>
<li class="vegetable">
<a href="www.vegetable.html class='three'">白菜</a>
</li>
</ul>
</div>
</body>
</html>
'''
# 需要先声明一段HTML文本,构造一个XPath解析对象
parse_html = etree.HTML(html_doc)
2.2.1 获取属性
- 示例:获取<li>标签的class属性
# 获取第一个 <li> 标签的class属性
class_content = parse_html.xpath('//li[1]/a/@href')
print(class_content) # ['www.animal.html']
# 获取全部 <li> 标签的class属性
class_content =parse_html.xpath('//li/a/@href')
print(class_content) # ['www.animal.html', 'www.fruits.html', 'www.vegetable.html']
2.2.2 获取文本
- 示例:获取<a>标签的文本
# 获取第一个 <a> 标签的文本内容
text = parse_html.xpath('//li[1]/a/text()')
print(text) # ['小狗']
# 获取全部 <a> 标签的文本内容
text = parse_html.xpath('//li/a/text()')
print(text) # ['小狗', '水果', '白菜']
2.2.3 获取所有节点
- 示例:获取所有li和a节点
# 获取所有 <li> 节点
node = parse_html.xpath('//li')
print(node) # [<Element li at 0x2af2b3b3a88>, <Element li at 0x2af2b3b3a48>, <Element li at 0x2af2b3b3b48>]
# 获取所有 <a> 节点
node = parse_html.xpath('//a')
print(node) # [<Element a at 0x26978ab5a48>, <Element a at 0x26978ab5a08>, <Element a at 0x26978ab5b08>]
2.2.4 获取子节点
- 示例:获取所有li节点的子节点a的文本内容
child_node = parse_html.xpath('//li/a/text()')
print(child_node) # ['小狗', '水果', '白菜']
2.2.5 获取父节点
- 示例:获取所有a节点的父节点li的class属性
parent_node = parse_html.xpath('//a/../@class')
print(parent_node) # ['animal', 'fruits', 'vegetable']
这是你想要的吗?我猜想不是,但是请别着急,官方文档更好用,点击直达XPath 教程,XPath常用语法。
3) 正则表达式(re)
首先,建议移步官方文档进行系统的学习正则表达式:https://docs.python.org/3/library/re.html
正则实在是太多东西了,这里担心误人子弟,还请各位参考官方文档去进行系统的学习。
3.1 正则的常用函数
- 常用方法
| 方法 | 语法 | 描述 |
|---|---|---|
| re.sub | re.sub(pattern, repl, string, count=0, flags=0) | 用于替换字符串中的匹配项 |
| re.compile | re.compile(pattern, flags=0) | 用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。 |
| re.match | re.match(pattern, string, flags=0) | 从字符起始位置匹配正则表达式,如果不成功则返回None |
| re.search | re.search(pattern, string, flags=0) | 匹配字符串并返回第一个成功的匹配,如果不成功则返回None |
| re.findall | re.findall(pattern, string, flags=0) | 返回正则表达式匹配的所有符合的内容,如果不成功则返回空列表 |
| re.finditer | re.finditer(pattern, string, flags=0) | 和 findall 一样,只不过作为迭代器返回匹配的字符串 |
- 看到方法中有很多常出现的字眼,如pattern,string,flags=0等,下面对它们做一下介绍。
| 方法 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 待匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式 |
- 这里的flags代表什么呢?请看下表。
| 方法 | 描述 |
|---|---|
| re.I | 忽略大小写 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
- 正则表达式实例(下图引用自:菜鸟教程)
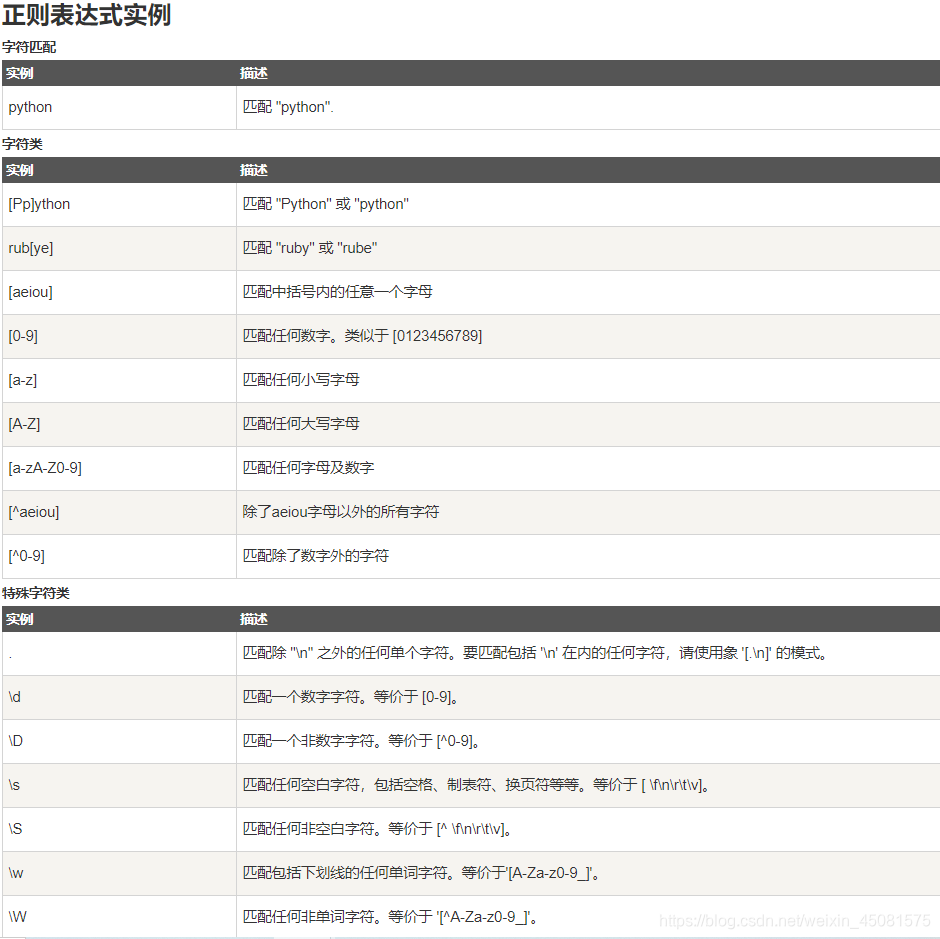
3.2 正则表达式(re)使用示例
首先导入模块。该模块为Python自带,无需另行安装。
import re
下面是用XPath解析网页的相关实例代码:
html_doc = '''
<html>
<body>
<div id='nothing'>
<ul>
<li class="animal">
<a href="www.animal.html" class='one'>小狗</a>
</li>
<li class="fruits">
<a href="www.fruits.html" class='two'>水果</a>
</li>
<li class="vegetable">
<a href="www.vegetable.html" class='three'>白菜</a>
</li>
</ul>
</div>
</body>
</html>
'''
3.2.1 re.sub示例
- 将2020SunriseCai的数字替换成 0
result = re.sub('\d', '0', '2020SunriseCai')
print(result) # 0000SunriseCai
3.2.2 re.compile示例

- 匹配第一个<> 标签的内容
pattren = re.compile('<.*?>')
result = pattren.search(html_doc)
print(result) # <re.Match object; span=(1, 7), match='<html>'>
print(result) # <html>
3.2.3 re.match示例
- 匹配字符串2020SunriseCai。
# 匹配成功
result = re.match("\d+", '2020SunriseCai')
print(result) # <re.Match object; span=(0, 3), match='2020'>
print(result) # 2020
# 匹配不成功 返回None
result = re.match("\s+", '2020SunriseCai')
print(result) # None
3.2.4 re.search示例
- 匹配第一个a标签
result = re.search("(<a .*?</a>)", html_doc, re.M)
print(result.group())
# <a href="www.animal.html" class='one'>小狗</a>
3.2.5 re.findall示例
- 匹配所有a标签,返回列表
result = re.findall("(<a .*</a>)", html_doc, re.M)
print(result)
# ['<a href="www.animal.html" class=\'one\'>小狗</a>',
'<a href="www.fruits.html" class=\'two\'>水果</a>',
'<a href="www.vegetable.html" class=\'three\'>白菜</a>']
3.2.6 re.finditer示例
- 匹配所有a标签,返回迭代器
result = re.finditer("(<a .*</a>)", html_doc, re.M)
for data in result:
print(data.group())
# <a href="www.animal.html" class='one'>小狗</a>
# <a href="www.fruits.html" class='two'>水果</a>
# <a href="www.vegetable.html" class='three'>白菜</a>
这是你想要的吗?我猜想不是,但是请别着急,官方文档更好用,点击直达
正则表达式:https://docs.python.org/3/library/re.html
优秀博文:Python正则表达式详解——re库
不可否认,本篇文章写的很差劲,建议各位点击官方文档的链接过去进行系统的学习。
多个网页解析器总有一款适合你,选择自己喜欢的方式进行系统的学习吧。
最后来总结一下本章的内容:
- 介绍了几个网页解析器的基本使用
- 介绍了BeautifulSoup的基本使用
- 介绍了XPath的基本使用
- 介绍了正则表达式 re的基本使用

- 感谢你的耐心观看,点关注,不迷路。
- 为方便菜鸡互啄,欢迎加入QQ群组织:648696280
下一篇文章,名为 《Python爬虫从入门到放弃 06 | Python爬虫打响第一炮之保存数据》。
