suggest应用场景
用户的输入行为是不确定的,而我们在写程序的时候总是想让用户按照指定的内容或指定格式的内容进行搜索,这里就要进行人工干预用户输入的搜索条件了;我们在用百度谷歌等搜索引擎的时候经常会看到按键放下的时候直接会提示用户是否想搜索某些相关的内容,恰好lucene在开发的时候想到了这一点,lucene提供的suggest包正是用来解决上述问题的。
suggest包联想词相关介绍
suggest包提供了lucene的自动补全或者拼写检查的支持;
拼写检查相关的类在org.apache.lucene.search.spell包下;
联想相关的在org.apache.lucene.search.suggest包下;
基于联想词分词相关的类在org.apache.lucene.search.suggest.analyzing包下;
拼写检查原理
- Lucene的拼写检查由org.apache.lucene.search.spell.SpellChecker类提供支持;
- SpellChecker设置了默认精度0.5,如果我们需要细粒度的支持可以通过调用setAccuracy(float accuracy)来设定;
- spellChecker会将外部来源的词进行索引;
这些来源包括:
DocumentDictionary查询document中的field对应的值;
FileDictionary基于一个文本文件的Directionary,每行一项,词组之间以"\t" TAB分隔符进行,每项中不能含有两个以上的分隔符;
HighFrequencyDictionary从原有的索引文件中读取某个term的值,并按照出现次数检查;
LuceneDictionary也是从原有索引文件中读取某个term的值,但是不检查出现次数;

PlainTextDictionary从文本中读取内容,按行读取,没有分隔符;
其索引的原理如下:
- 对索引过程加syschronized同步;
- 检查Spellchecker是否已经关闭,如果关闭,抛出异常,提示内容为:Spellchecker has been closed;
- 对外部来源的索引进行遍历,统计被遍历的词的长度,如果长度小于三,忽略该词,反之构建document对象并索引到本地文件,创建索引的时候会对每个单词进行详细拆分(对应addGram方法),其执行过程如下所示
[java] view plain copy
- /**
- * Indexes the data from the given {@link Dictionary}.
- * @param dict Dictionary to index
- * @param config {@link IndexWriterConfig} to use
- * @param fullMerge whether or not the spellcheck index should be fully merged
- * @throws AlreadyClosedException if the Spellchecker is already closed
- * @throws IOException If there is a low-level I/O error.
- */
- public final void indexDictionary(Dictionary dict, IndexWriterConfig config, boolean fullMerge) throws IOException {
- synchronized (modifyCurrentIndexLock) {
- ensureOpen();
- final Directory dir = this.spellIndex;
- final IndexWriter writer = new IndexWriter(dir, config);
- IndexSearcher indexSearcher = obtainSearcher();
- final List<TermsEnum> termsEnums = new ArrayList<>();
- final IndexReader reader = searcher.getIndexReader();
- if (reader.maxDoc() > 0) {
- for (final LeafReaderContext ctx : reader.leaves()) {
- Terms terms = ctx.reader().terms(F_WORD);
- if (terms != null)
- termsEnums.add(terms.iterator(null));
- }
- }
- boolean isEmpty = termsEnums.isEmpty();
- try {
- BytesRefIterator iter = dict.getEntryIterator();
- BytesRef currentTerm;
- terms: while ((currentTerm = iter.next()) != null) {
- String word = currentTerm.utf8ToString();
- int len = word.length();
- if (len < 3) {
- continue; // too short we bail but "too long" is fine...
- }
- if (!isEmpty) {
- for (TermsEnum te : termsEnums) {
- if (te.seekExact(currentTerm)) {
- continue terms;
- }
- }
- }
- // ok index the word
- Document doc = createDocument(word, getMin(len), getMax(len));
- writer.addDocument(doc);
- }
- } finally {
- releaseSearcher(indexSearcher);
- }
- if (fullMerge) {
- writer.forceMerge(1);
- }
- // close writer
- writer.close();
- // TODO: this isn't that great, maybe in the future SpellChecker should take
- // IWC in its ctor / keep its writer open?
- // also re-open the spell index to see our own changes when the next suggestion
- // is fetched:
- swapSearcher(dir);
- }
- }
对词语进行遍历拆分的方法为addGram,其实现为:
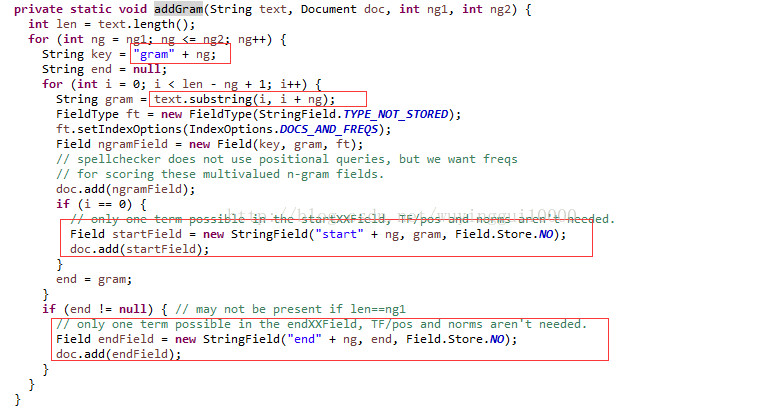
查看代码可知,联想词的索引不仅关注每个词的起始位置,也关注其倒数的位置;
- 联想词查询的时候,先判断grams里边是否包含有待查询的词拆分后的内容,如果有放到结果SuggestWordQueue中,最终结果为遍历SuggestWordQueue得来的String[],其代码实现如下:[java] view plain copy
- public String[] suggestSimilar(String word, int numSug, IndexReader ir,
- String field, SuggestMode suggestMode, float accuracy) throws IOException {
- // obtainSearcher calls ensureOpen
- final IndexSearcher indexSearcher = obtainSearcher();
- try {
- if (ir == null || field == null) {
- suggestMode = SuggestMode.SUGGEST_ALWAYS;
- }
- if (suggestMode == SuggestMode.SUGGEST_ALWAYS) {
- ir = null;
- field = null;
- }
- final int lengthWord = word.length();
- final int freq = (ir != null && field != null) ? ir.docFreq(new Term(field, word)) : 0;
- final int goalFreq = suggestMode==SuggestMode.SUGGEST_MORE_POPULAR ? freq : 0;
- // if the word exists in the real index and we don't care for word frequency, return the word itself
- if (suggestMode==SuggestMode.SUGGEST_WHEN_NOT_IN_INDEX && freq > 0) {
- return new String[] { word };
- }
- BooleanQuery query = new BooleanQuery();
- String[] grams;
- String key;
- for (int ng = getMin(lengthWord); ng <= getMax(lengthWord); ng++) {
- key = "gram" + ng; // form key
- grams = formGrams(word, ng); // form word into ngrams (allow dups too)
- if (grams.length == 0) {
- continue; // hmm
- }
- if (bStart > 0) { // should we boost prefixes?
- add(query, "start" + ng, grams[0], bStart); // matches start of word
- }
- if (bEnd > 0) { // should we boost suffixes
- add(query, "end" + ng, grams[grams.length - 1], bEnd); // matches end of word
- }
- for (int i = 0; i < grams.length; i++) {
- add(query, key, grams[i]);
- }
- }
- int maxHits = 10 * numSug;
- // System.out.println("Q: " + query);
- ScoreDoc[] hits = indexSearcher.search(query, maxHits).scoreDocs;
- // System.out.println("HITS: " + hits.length());
- SuggestWordQueue sugQueue = new SuggestWordQueue(numSug, comparator);
- // go thru more than 'maxr' matches in case the distance filter triggers
- int stop = Math.min(hits.length, maxHits);
- SuggestWord sugWord = new SuggestWord();
- for (int i = 0; i < stop; i++) {
- sugWord.string = indexSearcher.doc(hits[i].doc).get(F_WORD); // get orig word
- // don't suggest a word for itself, that would be silly
- if (sugWord.string.equals(word)) {
- continue;
- }
- // edit distance
- sugWord.score = sd.getDistance(word,sugWord.string);
- if (sugWord.score < accuracy) {
- continue;
- }
- if (ir != null && field != null) { // use the user index
- sugWord.freq = ir.docFreq(new Term(field, sugWord.string)); // freq in the index
- // don't suggest a word that is not present in the field
- if ((suggestMode==SuggestMode.SUGGEST_MORE_POPULAR && goalFreq > sugWord.freq) || sugWord.freq < 1) {
- continue;
- }
- }
- sugQueue.insertWithOverflow(sugWord);
- if (sugQueue.size() == numSug) {
- // if queue full, maintain the minScore score
- accuracy = sugQueue.top().score;
- }
- sugWord = new SuggestWord();
- }
- // convert to array string
- String[] list = new String[sugQueue.size()];
- for (int i = sugQueue.size() - 1; i >= 0; i--) {
- list[i] = sugQueue.pop().string;
- }
- return list;
- } finally {
- releaseSearcher(indexSearcher);
- }
- }
编程实践
以下是我根据FileDirectory相关描述编写的一个测试程序
[java] view plain copy
- package com.lucene.search;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.IOException;
- import java.nio.file.Paths;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.index.IndexWriterConfig;
- import org.apache.lucene.index.IndexWriterConfig.OpenMode;
- import org.apache.lucene.search.spell.SpellChecker;
- import org.apache.lucene.search.suggest.FileDictionary;
- import org.apache.lucene.store.Directory;
- import org.apache.lucene.store.FSDirectory;
- import org.wltea.analyzer.lucene.IKAnalyzer;
- public class SuggestUtil {
- public static void main(String[] args) {
- Directory spellIndexDirectory;
- try {
- spellIndexDirectory = FSDirectory.open(Paths.get("suggest", new String[0]));
- SpellChecker spellchecker = new SpellChecker(spellIndexDirectory );
- Analyzer analyzer = new IKAnalyzer(true);
- IndexWriterConfig config = new IndexWriterConfig(analyzer);
- config.setOpenMode(OpenMode.CREATE_OR_APPEND);
- spellchecker.setAccuracy(0f);
- //HighFrequencyDictionary dire = new HighFrequencyDictionary(reader, field, thresh)
- spellchecker.indexDictionary(new FileDictionary(new FileInputStream(new File("D:\\hadoop\\lucene_suggest\\src\\suggest.txt"))),config,false);
- String[] similars = spellchecker.suggestSimilar("中国", 10);
- for (String similar : similars) {
- System.out.println(similar);
- }
- spellIndexDirectory.close();
- spellchecker.close();
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
其中,我用的suggest.txt内容为:
[plain] view plain copy
- 中国人民 100
- 奔驰3 101
- 奔驰中国 102
- 奔驰S级 103
- 奔驰A级 104
- 奔驰C级 105
测试结果为:
[plain] view plain copy
- 中国人民
- 奔驰中国