在搜索引擎中,我们往往会遇见下面的情景

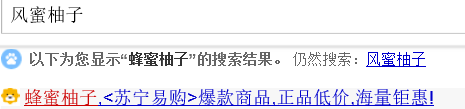
这其实就是拼写检查的应用,lucene的suggest模块就是为此而设的。
首先需要的是一个有效的拼写检查的源词典。
private static String dicpath = "G:\\downloads\\LJParser_release\\dictionary.dic";
//初始化字典目录
//最后一个fullMerge参数表示拼写检查索引是否需要全部合并
// 一句话总结:indexDictionary就是将字典文件里的词进行ngram操作后得到多个词然后分别写入索引。
spellchecker.indexDictionary(new PlainTextDictionary(Paths.get(dicpath)),config,true);
String[] suggests = spellchecker.suggestSimilar(word, numSug); //用来计算最后返回的建议词使用ngram来标识类似的单词,ngram简单的来说就是表示一个单词中一定长度的所有邻接字母组合,比如lucene当ngram=3时,那么字母组合包括:luc|uce|cen|ene所以ngram的选择必定会影响到检查匹配的效率。
那么直接来看一下代码(代码借鉴自益达)
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.spell.PlainTextDictionary;
import org.apache.lucene.search.spell.SpellChecker;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
//Suggest模块下另一个功能:拼写纠错
public class SpellCheckTest {
private static String dicpath = "G:\\downloads\\LJParser_release\\dictionary.dic";
private Document document;
private Directory directory = new RAMDirectory();
private IndexWriter indexWriter;
//拼写检查
private SpellChecker spellchecker;
private IndexSearcher indexSearcher;
private IndexReader indexReader;
//创建测试索引
public void CreateIndex(String content) throws IOException{
IndexWriterConfig config = new IndexWriterConfig(new StandardAnalyzer());
indexWriter = new IndexWriter(directory, config);
document = new Document();
document.add(new TextField("content",content,Store.YES));
try {
indexWriter.addDocument(document);
indexWriter.commit();
indexWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public void search(String word, int numSug) {
directory = new RAMDirectory();
try {
IndexWriterConfig config = new IndexWriterConfig(new StandardAnalyzer());
spellchecker = new SpellChecker(directory);
//初始化字典目录
//最后一个fullMerge参数表示拼写检查索引是否需要全部合并
// 一句话总结:indexDictionary就是将字典文件里的词进行ngram操作后得到多个词然后分别写入索引。
spellchecker.indexDictionary(new PlainTextDictionary(Paths.get(dicpath)),config,true);
//这里的参数numSug表示返回的建议个数
String[] suggests = spellchecker.suggestSimilar(word, numSug); //用来计算最后返回的建议词
//判断两个词的相似度,默认实现是LevensteinDistance,至于LevensteinDistance算法实现自己去看LevensteinDistance源码吧。
if (suggests != null && suggests.length > 0) {
for (String suggest : suggests) {
System.out.println("您是不是想要找:" + suggest);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
SpellCheckTest spellCheckTest = new SpellCheckTest();
spellCheckTest.CreateIndex("《屌丝男士》不是传统意义上的情景喜剧,有固定时长和单一场景," +
"以及简单的生活细节。而是一部具有鲜明网络特点,舞台感十足," +
"整体没有剧情衔接,固定的演员演绎着并不固定角色的笑话集。");
spellCheckTest.CreateIndex("屌丝男士的拍摄构想,首先源于“屌丝文化”在中国的刮起的现象级春风," +
"红透了整片天空,全中国上下可谓无人不屌丝,无人不爱屌丝。");
spellCheckTest.CreateIndex("德国的一部由女演员玛蒂娜-希尔主演的系列短剧,凭借其疯癫荒诞、自high" +
"耍贱、三俗无下限的表演风格,在中国取得了巨大成功,红火程度远远超过了德国。不仅位居国内各" +
"个视频网站的下载榜和点播榜高位,且在微博和媒体间,引发了坊间热议和话题传播。网友们更是" +
"形象地将其翻译为《屌丝女士》,对其无比热衷。于是我们决定着手拍一部属于中国人," +
"带强烈国人屌丝色彩的《屌丝男士》。");
String word = "吊丝男士";
spellCheckTest.search(word, 4);
}
}
一、SpellChecker的构造函数需要传入需要被检查的文档索引;

二、为字典创建索引(当然ngram分词的过程被封装了)
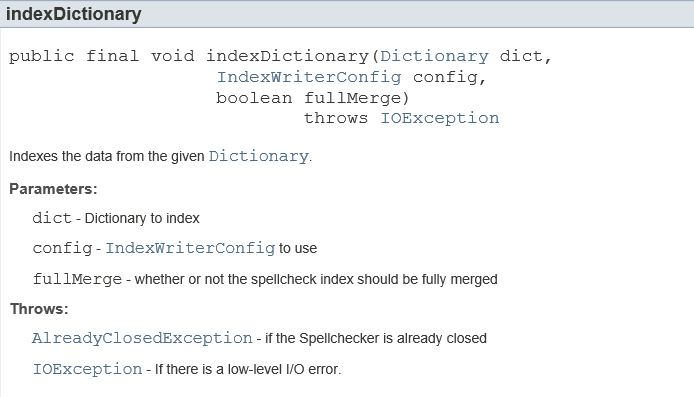
三、计算并返回相似的词:
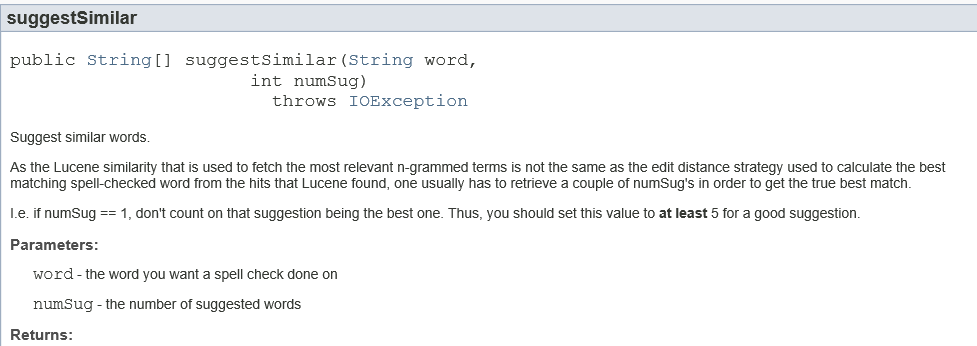
计算两个词相似度的实现采用LevensteinDistance进行字符串相似度计算。LevensteinDistance就是edit distance(编辑距离)。编辑距离,又称Levenshtein距离(也叫做Edit Distance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如将kitten一字转成sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
俄罗斯科学家Vladimir Levenshtein在1965年提出这个概念。
以上就是简单拼写检查的基本过程。
接下来看下选取不同ngram的结果:
这是字典文件:

ngram = 4时(编辑距离看作4)

ngram = 1时(编辑距离看作1)
