一、 阅读理解型问答
1、 概念
机器阅读理解与问答主要涉及到深度学习、自然语言处理和信息检索。机器阅读理解具有很高的研究价值和多样的落地场景。它能够让计算机帮助人类在大量文本中快速找到准确答案,从而减轻人们对信息的获取的成本。
具体来讲,机器阅读理解和问答任务(QA)指的是给定一个问题和一个或多个文本,训练的QA系统可以依据文本找出问题答案。一般情况下,有以下三种问题:Simple (factoid) questions,即简单的问题,可以用简单的事实回答,答案通常只是一个name entity;Complex (narrative) questions,即稍微复杂的叙述问题,答案略长;Complex (opinion) questions,即复杂的问题,通常是关于观点/意见。对于第一类问题,标准答案一般与文本中的答案完全匹配。阅读理解型问答主要解决第一种类型的问题。
2、 目的
机器阅读理解(Machine Reading Comprehension)是文本问答的一个子类,旨在令机器阅读并理解一段自然语言组成的文本,并回答相关问题。机器阅读理解是指让机器像人类一样阅读文本,提炼文本信息并回答相关问题。通过这种任务形式,我们可以对机器的自然语言理解水平进行评估,因此该任务具有重要的研究价值。
3、 主流方法
早期的阅读理解研究受限于数据集规模以及自然语言处理技术的发展,进展较为缓慢。直到2015年,谷歌发布首个大规模完形填空类阅读理解数据集CNN/Daily Mail[1] ,引发了基于神经网络的阅读理解研究热潮。2016年,SQuAD 数据集[2]被斯坦福大学发布,并迅速成为了抽取式阅读理解的基准测试集。
随后至今,机器阅读理解领域发展迅速,各类任务如开放域式、多选式、聊天式和多跳式等不断涌现。下面主要介绍调研过的三种方法:
3.1 序列标注方法
(1)算法描述
百度团队利用自己的数据集webQA在2016年提出了该算法[3] ,算法的主要创新点是将QA问答转化成序列标注问题,并提出了一个端到端的模型。
算法模型主要分为三层:Question LSTM、Evidence LSTMs、CRF层。Question LSTM层的主要工作是通过一个LSTM层和一个attention层将句子表示成rq;Evidence LSTMs层是模型的创新之处,该层会对于待匹配句子中的每个单词,会生成一个二维one-hot向量,第一位表示表示单词是否出现在Question中,出现则为1,否则为0,第二位表示这个单词是否出现在另外一个Evidence的Answer中,出现则为1,否则为0。将rq和这个二位向量相结合进行变换之后作为多层LSTM的输入;CRF层将多层LSTM的输出作为CRF的输入,用序列标注的方法预测答案。
(2)算法参考结果:
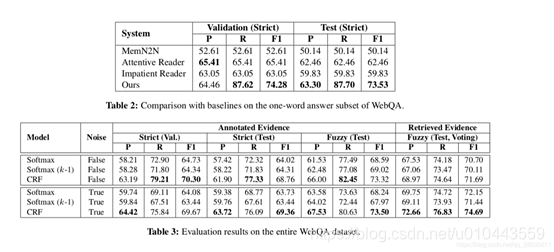
3.2 基于膨胀卷积的方法
(1)算法描述
本算法模型是广州火焰信息科技有限公司在SOGOU举办的“事实类问答任务”比赛时提出的算法,算法简称DGCNN模型。该算法是一个基于CNN和简单的Attention模型的算法。DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。模型框架如下图所示:

模型的创新点主要包括三点:1)用CNN模型替代LSTM模型,提升了模型的效率;2)提取了等丰富的8个共现特征,提供更多的特征数据;3)去掉CRF层,改为0|1标注,以此来标识答案的开始位置和终止位置,这可以看成一个“半指针-半标注”的结构。
(2)算法参考结果
算法在SOGOU比赛的榜单上暂居第一位,准确率得分0.7583。
3.3 端到端的阅读理解模型
(1)算法描述
本算法是2018年中国信息学会和中国计算机技术学会联合举办的2018机器阅读理解技术竞赛中冠军队Naturali奇点机智团队提出的算法。Naturali团队在篇章预处理、预训练词向量、其他特征、多个答案、联合训练、最小风险训练等方面做出了对应的设计,并尝试了很多经典的阅读理解模型,包括BiDAF、MatchLSTM、DCA,最终提交的数据是通过集成模型计算出来的,并尝试引入多个答案的信息。另外,基于公司在自然语言处理领域的积累和已有的自主研发自然语言处理NLP工具,根据数据集的特点做了一些改进,得到最终的模型。
竞赛提供了一个基于真实场景的大规模中文阅读理解百度数据集,共包含来自百度搜索的30万个来自真实用户的问题,对中文阅读理解系统提出了很大的挑战。以百度提供五个篇文章作为参考文档。由于文章没有长度限制,我们根据关键词密度,句子位置等信息将超过500词的文章压缩到500词以内。
以下是我们数据预处理的具体方法:
-
如果标题和各段内容中间插入特殊分割符号连接在一起,没有超过预设最大长度,则将得到结果作为预处理的结果;
-
否则,我们计算各段落和问题的BLEU-4分数,以衡量段落和问题的相关性;
-
在分数排名前k的段落中,选择最早出现的段落;
-
选取标题,这个段落以及下一个段落;
-
对于第3到第10个段落,选取每个段落的第一句话;
-
将所有选取的内容以特殊分隔符连接在一起,截取最前面不超过预设最大长度的内容,将得到的结果作为预处理的结果。
模型的整体结构分为四层,其整体框架如下图所示:
模型的第一层为特征表示层(Representation),该层的主要功能是提取给定的一个问题的次序列中特征,将它变成一个特征向量序列;编码层(Ecodeing),改层的主要功能是得到问题和篇章的向量特征表示序列后对其进行编码;匹配层(Mating),该层属于模型的和核心部分,利用注意力机制融合问题和篇章信息。在的单一模型中用到的BIDFA模型,在集成模型可以用Match-LSTM、BiDAF、DCA这三种集成模型不同的匹配层得到的结果进行集成;答案片段抽取(Answer Extraction),该层利用指针网络对答案进行抽取。模型中利用多个参数答案的公式进行计算,即计算多个答案的损失的平均值作为最终结果的损失函数。
(2)算法参考结果
单一模型上的参考结果

集成模型上的参考结果
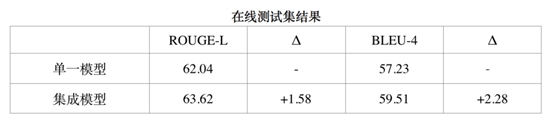
二、阅读理解算法实践
1、目的
阅读理解算法实际的目的是为了巩固前期对算法的学习,尝试将算法进行复现。实践中选择了DGCNN模型进行复现。对模型的准确率和模型的可扩展性进行检验。
2、实践数据
数据选择了webQA数据集,WebQA是百度开放的问答数据集合,数据采用“一个我呢提+多段材料”的格式是希望从多段材料中共同决策问题的精准答案。数据存储形式如下:
问题:社保缴纳多少年可以领养老金
答案:15年
材料1:最好不辞,交够15年到退休就可以领养老金了如果有特殊原因非要辞,可以个人接着交。
材料2:你好!养老保险缴纳满15年,达到退休年龄可以领取养老金。
材料3:在生活中,每个人都会缴纳社保,多少年可以领取退休...社保要交多少年才能领养老金呢,在上文中为大家介绍了一下。
3、实践结果
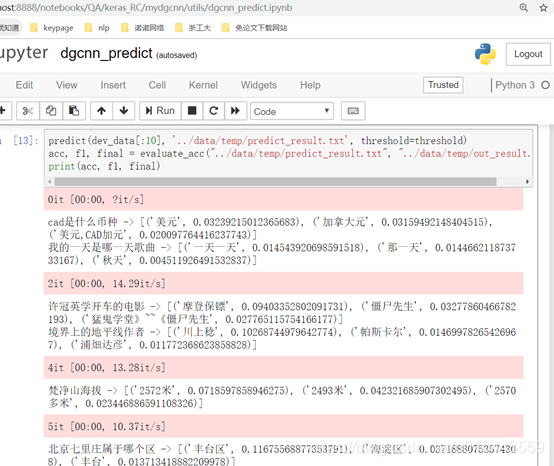
实验过程中将webQA数据以8:2的比例拆分了训练集和测试集,在测试数据上测试结果在0.7左右。
三、阅读理解算法综合分析
1、结合业务场景可以解决的问题
基于阅读理解的问答(Machine Reading Comprehension Question Answering,MRCQA)是指给定文档库,通过理解用户的问题,从文档中找到能够回答用户问题的满足需求的细粒度的片段(如段落、句子)的过程。这里进行MRCQA处理的前提是答案在文本中可以明确找到,且最好是一个连续的片段。不同于IRQA,MRCQA检索的是文档中的片段而不是问答对。相较于问答对,文档通常具有篇幅更大、语义更复杂等特点。问答对通常是由人工整理的高频问题,而文档通常为普通的文本文件,其具有更低的获取成本,因此,基于阅读理解的问答系统通常用来解决能从大量无结构化文本中寻找到答案的问题。
针对电子化文本管理的时代,从非结构化的文本中提取出问题的答案不仅能够节省阅读的时间,提升工作的效率,更能够简化人类的工作量。结合公司现有的各种文本可以将阅读理解问答应用在公司制度问答、财税问题问答、现关文档查询等等的各个方面,所以阅读理解型问答是一个非常有价值的研究项目。
2、实现难点
为了将算法落地也为了作为进一步的研究,我尝试了用该算法解决公司政策问题查询的问题,但是效果并不理想。虽然实验结果基本达到了文章给出的参考结果,但是该模型的泛化性并不好,在其他的数据上并不可观。
分析其原因总体有一下几个因素:1)webQA训练数据中的答案依存文本有多个,这样可以进行多次答案预测,最终选择最优的结果。2)依存文本的长度不能过长,过长的话就会导致无法准确定位答案的区间。3)pdf转化成txt文本的过程中存在部分字符出现错误,以及标点符号出现错误的现象。总体来说,将webQA数据训练的模型直接用作公司政策的问答是有问题的;4)阅读理解算法研究本身面临的挑战。
除此之外,国内外的机器阅读理解的研究也面临着许多挑战,如:1)当前方法的模型结构和训练方法中存在着制约性能的问题;2)当前具备顶尖性能的集成模型在实际部署时效率低下;3)传统方法无法有效处理原文中找不到答案的情况;4)当前大部分模型是针对单段落场景设计的,无法有效扩展至开放域问答;5)当前大部分模型无法有效支持离散推理和多答案预测等情况。
3、需要解决的问题
综合以上问题,我思考了可能的解决方案。
(1)针对公司政策相关文本的阅读理解型问大数据的整理是必要的,用于训练自己的问答模型。
(2) 公司政策文件最好找word或txt文件,避免用pdf文件。
(3)针对文件过长的问题需要先用算法确定答案可能存在的文本段落或句子,然后再从段落或句子中提取答案。
(4)多个依存文本对答案进行提炼,这一点在公司政策答案提取上可能不太好实现,因为不常有一个政策在多个文件中重复提及的现象。所以可以考虑在提取的答案基础上再用字符匹配,统计频率等方法提升结果的准确度。
参考文献
[1] Hermann K M, Kocisky T, Grefenstette E, et al. Teaching Machines to Read and Comprehend. NIPS 2015: 1693-1701.
[2] Rajpurkar P, Zhang J, Lopyrev K, et al. SQuAD: 100,000+ Questions for Machine Comprehension of Text. EMNLP 2016: 2383-2392.
[3] Li P, Li W, He Z, et al. Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering[J]. arXiv: Computation and Language, 2016.
