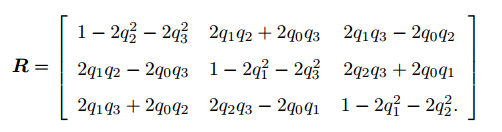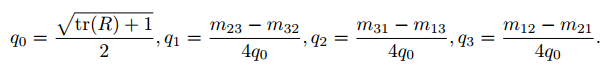Simultaneous Localization and Mapping 同时定位与地图构建
定位:自身状态
单目 Monocular 运动 (Motion) 若相机右移,则图像中物体向左移结构 (Structure)近处的物体移动快,远处的物体移动慢——视差尺度 (Scale) 估计轨迹地图和真实轨迹地图相差一个因子——尺度不确定性 双目 Stereo 基线 (Baseline)两个单目相机间的距离深度 RGB-D
传感器信息读取、视觉里程计、后端优化、回环检测、建图
1. 视觉里程计 Visual Odometry(VO) 前端(Front End)
通过相邻帧间的图像判断相机运动状态并恢复空间结构
存在累计漂移 (accumulating drift)
2. 后端优化 Optimization 后端(Back End)
处理噪声的问题:通过带有噪声的数据估计整个系统的状态和这个状态估计的不确定性有多大,即最大后验概率估计(MAP)。
主要是滤波和非线性优化算法。
SLAM的本质:对运动主体自身和周围环境空间不确定性的估计。
3. 回环检测 Loop Closing
解决了位置估计随时间漂移的问题。实际中机器人回到原点而估计值未回到原点,则把估计位置“拉”到原点消除漂移,即回环检测。在检测到回环后,把A与B是同一点这个信息告诉后端优化,后端据此信息进行轨迹和地图调整,得到全局一致的轨迹和地图。
4. 建图 Mapping
{
x
k
=
f
(
x
k
−
1
,
u
k
,
w
k
)
运
动
方
程
z
k
,
j
=
h
(
y
j
,
x
k
,
v
k
,
j
)
观
测
方
程
\left\{ \begin{aligned} x_k&=f(x_{k-1},u_k,w_k) &运动方程\\ z_{k,j}&=h(y_j,x_k,v_{k,j}) &观测方程 \end{aligned} \right.
{ x k z k , j = f ( x k − 1 , u k , w k ) = h ( y j , x k , v k , j ) 运 动 方 程 观 测 方 程
旋转矩阵
变换矩阵
描述旋转
a
′
=
R
a
+
t
\pmb{a^{'}}=\pmb{Ra}+\pmb{t}
a ′ a ′ a ′ = R a R a R a + t t t
T
=
[
R
t
0
T
1
]
\pmb{T}=\left[\begin{matrix}\pmb{R} &\pmb{t}\\\pmb{0}^T&1\end{matrix} \right]
T T T = [ R R R 0 0 0 T t t t 1 ]
集合
S
O
(
n
)
SO(n)
S O ( n )
S
E
(
n
)
SE(n)
S E ( n )
a
′
a^{'}
a ′
a
a
a R 是行列式为1的正交矩阵,证明
非齐次坐标、齐次坐标:详细说明
描述旋转:用一个旋转轴
n
\pmb{n}
n n n
θ
\theta
θ
1.旋转向量==>旋转矩阵 :罗德里格斯公式 推导
R
=
c
o
s
θ
I
+
(
1
−
c
o
s
θ
)
n
n
T
+
s
i
n
θ
n
\pmb{R}=cos\theta\pmb{I}+(1-cos\theta)\pmb{n}\pmb{n}^T+sin\theta\pmb{n}
R R R = c o s θ I I I + ( 1 − c o s θ ) n n n n n n T + s i n θ n n n
2.旋转矩阵==>旋转向量
{
θ
=
a
r
c
o
s
s
(
t
r
(
R
)
−
1
2
)
R
n
=
n
\left\{ \begin{aligned} \theta&=arcoss(\dfrac{tr(\pmb{R})-1}{2}) \\ \pmb{Rn}&=\pmb{n} \end{aligned} \right.
⎩ ⎨ ⎧ θ R n R n R n = a r c o s s ( 2 t r ( R R R ) − 1 ) = n n n
欧拉角常使用“偏航-俯仰-滚转”(yaw-pitch-roll),等价于 ZYX轴的旋转,注意是先y再p再r。
q
=
q
0
+
q
1
i
+
q
2
j
+
q
3
k
\pmb{q}=q_0+q_1i+q_2j+q_3k
q q q = q 0 + q 1 i + q 2 j + q 3 k
q
=
[
s
,
v
]
\pmb{q}=[s,\pmb{v}]
q q q = [ s , v v v ]
1.旋转向量==>四元数
q
=
[
c
o
s
θ
2
,
n
x
s
i
n
θ
2
,
n
y
s
i
n
θ
2
,
n
z
s
i
n
θ
2
]
T
\pmb{q}=[cos\dfrac{\theta}{2},n_xsin\dfrac{\theta}{2},n_ysin\dfrac{\theta}{2},n_zsin\dfrac{\theta}{2}]^T
q q q = [ c o s 2 θ , n x s i n 2 θ , n y s i n 2 θ , n z s i n 2 θ ] T
{
θ
=
2
a
r
c
o
s
s
q
0
[
n
x
,
n
y
,
n
z
]
T
=
[
n
x
,
n
y
,
n
z
]
T
/
s
i
n
θ
2
\left\{ \begin{aligned} &\theta=2arcossq_0 \\ &[n_x,n_y,n_z]^T =[n_x,n_y,n_z]^T/sin\dfrac{\theta}{2} \end{aligned} \right.
⎩ ⎨ ⎧ θ = 2 a r c o s s q 0 [ n x , n y , n z ] T = [ n x , n y , n z ] T / s i n 2 θ
q
0
=
[
+
‾
1
,
0
,
0
,
0
]
\pmb{q}_0=[ \underline{+}1,0,0,0]
q q q 0 = [ + 1 , 0 , 0 , 0 ]
3.四元数==>旋转矩阵
p
=
[
0
,
x
,
y
,
x
]
\pmb{p}=[0,x,y,x]
p p p = [ 0 , x , y , x ]
q
=
[
c
o
s
θ
2
,
n
s
i
n
θ
2
]
\pmb{q}=[cos\dfrac{\theta}{2},\pmb{n}sin\dfrac{\theta}{2}]
q q q = [ c o s 2 θ , n n n s i n 2 θ ]
p
′
=
q
p
q
−
1
\pmb{p^{'}}=\pmb{q}\pmb{p}\pmb{q}^{-1}
p ′ p ′ p ′ = q q q p p p q q q − 1
p
′
\pmb{p^{'}}
p ′ p ′ p ′ 证明
S
O
(
3
)
SO(3)
S O ( 3 )
群:一种集合加一种运算,满足“封结幺逆”的性质
向量可变为反对称矩阵
a
\pmb{a}
a a a
A
\pmb{A}
A A A
[
0
−
a
3
a
2
a
3
0
−
a
1
−
a
2
a
1
0
]
\left[\begin{matrix} 0 & -a_3 &a_2\\a_3&0&-a_1\\-a_2&a_1&0 \end{matrix} \right]
⎣ ⎡ 0 a 3 − a 2 − a 3 0 a 1 a 2 − a 1 0 ⎦ ⎤
A
\pmb{A}
A A A
v
^v
v
a
\pmb{a}
a a a
推导可得:
R
=
e
x
p
(
ϕ
0
\pmb{R} = exp(\phi_0
R R R = e x p ( ϕ 0
t
)
t)
t )
R
\pmb{R}
R R R
ϕ
0
\phi_0
ϕ 0
ϕ
\phi
ϕ
S
O
(
3
)
SO(3)
S O ( 3 )
s
o
\pmb{\mathfrak{so}}
s o s o s o
李代数
李代数描述了李群的局部性质,由一个集合、一个数域、一个二元运算[,](李括号)组成。记为
g
\pmb{\mathfrak{g}}
g g g
S
O
(
3
)
SO(3)
S O ( 3 )
R
3
\mathbb{R^3}
R 3
ϕ
\phi
ϕ
ϕ
\phi
ϕ
Φ
=
ϕ
\pmb{\Phi} = \phi
Φ Φ Φ = ϕ
=
[
0
−
a
3
a
2
a
3
0
−
a
1
−
a
2
a
1
0
]
=\left[\begin{matrix} 0 & -a_3 &a_2\\a_3&0&-a_1\\-a_2&a_1&0 \end{matrix} \right]
= ⎣ ⎡ 0 a 3 − a 2 − a 3 0 a 1 a 2 − a 1 0 ⎦ ⎤ 在不引起歧义的情况下就说
s
o
\pmb{\mathfrak{so}}
s o s o s o
S
O
(
3
)
SO(3)
S O ( 3 )
李代数 ==>李群 :
e
x
p
(
θ
a
exp(\theta\pmb{a}
e x p ( θ a a a
)
=
c
o
s
θ
I
+
(
1
−
c
o
s
θ
)
a
a
T
+
s
i
n
θ
a
)=cos\theta\pmb{I}+(1-cos\theta)\pmb{a}\pmb{a}^T+sin\theta\pmb{a}
) = c o s θ I I I + ( 1 − c o s θ ) a a a a a a T + s i n θ a a a
ϕ
\phi
ϕ
θ
\theta
θ
a
\pmb{a}
a a a
ϕ
=
θ
a
\phi=\theta\pmb{a}
ϕ = θ a a a
s
o
\pmb{\mathfrak{so}}
s o s o s o
李群 ==>李代数 :见课本或第3讲中又旋转矩阵求旋转向量
旋转角度固定在±
π
\pi
π
BCH公式和近似形式
l
n
(
e
x
p
(
A
)
ln(exp(\pmb{A})
l n ( e x p ( A A A )
e
x
p
(
B
)
exp(\pmb{B})
e x p ( B B B )
)
=
A
+
B
+
1
2
[
A
,
B
]
)=\pmb{A}+\pmb{B}+\dfrac{1}{2} [\pmb{A},\pmb{B}]
) = A A A + B B B + 2 1 [ A A A , B B B ]
l
n
(
e
x
p
(
ϕ
1
ln(exp(\phi_1
l n ( e x p ( ϕ 1
)
e
x
p
(
ϕ
2
)exp(\phi_2
) e x p ( ϕ 2
)
)
V
))^V
) ) V
≈
{
J
l
(
ϕ
2
)
−
1
ϕ
1
+
ϕ
2
当
ϕ
1
为
小
量
J
r
(
ϕ
1
)
−
1
ϕ
2
+
ϕ
1
当
ϕ
2
为
小
量
\approx \left\{\begin{aligned} \pmb{J}_l(\phi_2)^{-1}\phi_1+\phi_2 &&当\phi_1为小量\\\pmb{J}_r(\phi_1)^{-1}\phi_2+\phi_1 &&当\phi_2为小量 \end{aligned}\right.
≈ { J J J l ( ϕ 2 ) − 1 ϕ 1 + ϕ 2 J J J r ( ϕ 1 ) − 1 ϕ 2 + ϕ 1 当 ϕ 1 为 小 量 当 ϕ 2 为 小 量
以左乘为例,假定某个旋转
R
\pmb{R}
R R R
ϕ
\phi
ϕ
Δ
R
\Delta\pmb{R}
Δ R R R
Δ
ϕ
\Delta \phi
Δ ϕ
李群:
Δ
R
⋅
R
\Delta\pmb{R} \cdot \pmb{R}
Δ R R R ⋅ R R R
e
x
p
(
Δ
ϕ
exp(\Delta\phi
e x p ( Δ ϕ
)
e
x
p
(
ϕ
)exp(\phi
) e x p ( ϕ
)
=
e
x
p
(
(
ϕ
+
J
l
(
ϕ
)
Δ
ϕ
)
)= exp((\phi+\pmb{J}_l(\phi)\Delta\phi)
) = e x p ( ( ϕ + J J J l ( ϕ ) Δ ϕ )
)
)
)
李代数加法近似于李群上带左右雅可比的乘法
李代数:
e
x
p
(
(
ϕ
+
Δ
ϕ
)
exp((\phi+\Delta\phi)
e x p ( ( ϕ + Δ ϕ )
)
)
)
=
e
x
p
(
(
J
l
Δ
ϕ
)
= exp((\pmb{J}_l\Delta\phi)
= e x p ( ( J J J l Δ ϕ )
)
e
x
p
(
ϕ
) exp(\phi
) e x p ( ϕ
)
)
)
S
O
(
3
)
SO(3)
S O ( 3 )
对空间
p
p
p
R
p
点
,
若
求
点
坐
标
对
旋
转
的
倒
数
,
可
不
严
谨
的
记
为
\pmb{Rp}点,若求点坐标对旋转的倒数,可不严谨的记为
R p Rp R p 点 , 若 求 点 坐 标 对 旋 转 的 倒 数 , 可 不 严 谨 的 记 为
∂
R
p
∂
R
\dfrac{\partial \pmb{Rp}}{\partial \pmb{R}}
∂ R R R ∂ R p Rp R p
S
O
(
3
)
SO(3)
S O ( 3 )
R
\pmb{R}
R R R
ϕ
\phi
ϕ
∂
(
e
x
p
(
ϕ
)
>
p
)
∂
ϕ
\dfrac{\partial (exp(\phi)^{>}\pmb{p} )}{\partial \phi}
∂ ϕ ∂ ( e x p ( ϕ ) > p p p )
求导模型
∂
R
p
∂
ϕ
=
(
−
R
p
)
\dfrac{\partial \pmb{Rp}}{\partial \phi}=(-\pmb{Rp})
∂ ϕ ∂ R p Rp R p = ( − R p Rp R p )
J
l
\pmb{J}_l
J J J l
扰动模型(左乘)
∂
R
p
∂
ψ
=
(
−
R
p
)
\dfrac{\partial \pmb{Rp}}{\partial \psi}=(-\pmb{Rp})
∂ ψ ∂ R p Rp R p = ( − R p Rp R p )
为什么要求导?
T
\pmb{T }
T T T
p
\pmb{p}
p p p
z
\pmb{z}
z z z
w
\pmb{w}
w w w
e
\pmb{e}
e e e
z
=
T
p
+
w
\pmb{z}=\pmb{T }\pmb{p}+\pmb{w}
z z z = T T T p p p + w w w
e
=
z
−
T
p
\pmb{e}=\pmb{z}-\pmb{T }\pmb{p}
e e e = z z z − T T T p p p
T
\pmb{T}
T T T
m
i
n
T
J
(
T
)
=
∑
i
=
1
N
∣
∣
z
i
−
T
p
i
∣
∣
2
\underset {T}{min} J(\pmb{T})=\displaystyle\sum_{i=1}^N||\pmb{z}_i-\pmb{T }\pmb{p}_i||^2
T min J ( T T T ) = i = 1 ∑ N ∣ ∣ z z z i − T T T p p p i ∣ ∣ 2
现实世界空间点
P
P
P
[
X
,
Y
,
Z
]
T
[X,Y,Z]^T
[ X , Y , Z ] T
P
′
P'
P ′
[
X
′
,
Y
′
,
Z
′
]
T
[X',Y',Z']^T
[ X ′ , Y ′ , Z ′ ] T
(
Z
′
(Z'
( Z ′
f
)
f)
f )
P
′
P'
P ′
[
u
,
v
]
T
[u,v]^T
[ u , v ] T
将倒像对称为正像,研究正像模型
Z
f
=
X
X
′
=
Y
Y
′
\dfrac{Z}{f} = \dfrac{X}{X'} = \dfrac{Y}{Y'}
f Z = X ′ X = Y ′ Y
X
′
=
f
X
Z
X' = f\dfrac{X}{Z}
X ′ = f Z X
Y
′
=
f
Y
Z
Y' = f\dfrac{Y}{Z}
Y ′ = f Z Y
像素坐标系与成像平面之间,相差了一个缩放和一个原点的平移。
u
u
u
α
α
α
v
v
v
β
β
β
[
c
x
,
c
y
]
T
[c_x,c_y]^T
[ c x , c y ] T
[
u
,
v
]
T
[u,v]^T
[ u , v ] T
{
u
=
α
X
′
+
c
x
v
=
β
Y
′
+
c
y
.
\left\{\begin{aligned} u = α X' +c_x\\ v = β Y' +c_y \end{aligned}\right..
{ u = α X ′ + c x v = β Y ′ + c y .
α
f
\pmb{αf}
α f α f α f
f
x
\pmb{f_x}
f x f x f x
β
f
\pmb{βf}
β f β f β f
f
y
\pmb{f_y}
f y f y f y
{
u
=
f
x
X
Z
+
c
x
v
=
f
y
Y
Z
+
c
y
.
\left\{\begin{aligned} u = f_x\dfrac{X}{Z} +c_x\\ v = f_y\dfrac{Y}{Z} +c_y \end{aligned}\right..
⎩ ⎪ ⎪ ⎨ ⎪ ⎪ ⎧ u = f x Z X + c x v = f y Z Y + c y .
Z
(
u
v
1
)
=
(
f
x
0
c
x
0
f
y
c
y
0
0
1
)
(
X
Y
Z
)
=
K
P
Z\left(\begin{matrix}u\\v\\1\end{matrix}\right) = \left(\begin{matrix}f_x & 0 & c_x\\ 0 &f_y& c_y\\0 &0&1\end{matrix}\right)\left(\begin{matrix}X\\Y\\Z\end{matrix}\right) = \pmb{KP}
Z ⎝ ⎛ u v 1 ⎠ ⎞ = ⎝ ⎛ f x 0 0 0 f y 0 c x c y 1 ⎠ ⎞ ⎝ ⎛ X Y Z ⎠ ⎞ = K P K P K P
中间矩阵为相机的内参矩阵 K ,
f
f
f
α
,
β
α,β
α , β
f
x
,
f
y
,
c
x
,
c
y
f_x,f_y,c_x,c_y
f x , f y , c x , c y
上面中的
P
\pmb{P}
P P P
P
w
\pmb{P_w}
P w P w P w
(
R
,
t
)
(\pmb{R,t})
( R , t R , t R , t )
Z
P
u
v
=
Z
[
u
v
1
]
=
K
(
R
P
w
+
t
)
=
K
T
P
w
Z\pmb{P_{uv}} = Z\left[\begin{matrix}u\\v\\1\end{matrix}\right] = \pmb{K(RP_w+t)} = \pmb{KTP_w}
Z P u v P u v P u v = Z ⎣ ⎡ u v 1 ⎦ ⎤ = K ( R P w + t ) K ( R P w + t ) K ( R P w + t ) = K T P w K T P w K T P w
相机的位姿
(
R
,
t
)
(\pmb{R,t})
( R , t R , t R , t ) 外参数 ,在机器人或自动驾驶车辆中,外参有时也解释成相机坐标系到机器人本体坐标系之间的变换,描述“相机安装在什么地方”
注意后一个式子隐含了一次齐次坐标到非齐次坐标的转换在
T
\pmb{T}
T T T
P
\pmb{P}
P P P
K
\pmb{K}
K K K
投影过程还可以从另一个角度来看。我们可以把一个世界坐标点先转换到相机坐标系,再除掉它最后一维的数值(即该点距离相机成像平面的深度),这相当于把最后一维进行归一化处理,得到点 P 在相机归一化平面上的投影:
(
R
P
w
+
t
)
=
[
X
,
Y
,
Z
]
T
⏟
相机坐标
→
[
X
Z
,
Y
Z
,
1
]
T
⏟
归一化坐标
(\pmb{RP_w+t}) =\underbrace{[X,Y,Z]^T}_{\text{相机坐标}} \rightarrow\underbrace{[\dfrac{X}{Z},\dfrac{Y}{Z},1]^T}_{\text{归一化坐标}}
( R P w + t R P w + t R P w + t ) = 相机坐标
[ X , Y , Z ] T → 归一化坐标
[ Z X , Z Y , 1 ] T
归一化坐标 可看成相机前方z = 1 处的平面上的一个点,这个 z = 1 平面也称为归一化平面 。归一化坐标再左乘内参就得到了像素坐标,所以我们可以把像素坐标
[
u
,
v
]
T
[u,v]^T
[ u , v ] T
径向畸变:由透镜形状引起的畸变,主要分为桶形畸变和枕形畸变两类
切向畸变:在相机的组装过程中由于不能使透镜和成像面严格平行
将三维空间点投影到归一化图像平面。设它的归一化坐标 为
[
x
,
y
]
T
[x,y]^T
[ x , y ] T
对归一化平面上的点计算径向畸变和切向畸变。
{
x
d
i
s
t
o
r
t
e
d
=
x
(
1
+
k
1
r
2
+
k
2
r
4
+
k
3
r
6
)
+
2
p
1
x
y
+
p
2
(
r
2
+
2
x
2
)
y
d
i
s
t
o
r
t
e
d
=
y
(
1
+
k
1
r
2
+
k
2
r
4
+
k
3
r
6
)
+
p
1
(
r
2
+
2
y
2
)
+
2
p
2
x
y
\left\{\begin{aligned} x_{distorted} = x(1+k_1r^2+k_2r^4+k_3r^6)+2p_1xy+p_2(r^2+2x^2)\\ y_{distorted} = y(1+k_1r^2+k_2r^4+k_3r^6)+p_1(r^2+2y^2)+2p_2xy \end{aligned}\right.
{ x d i s t o r t e d = x ( 1 + k 1 r 2 + k 2 r 4 + k 3 r 6 ) + 2 p 1 x y + p 2 ( r 2 + 2 x 2 ) y d i s t o r t e d = y ( 1 + k 1 r 2 + k 2 r 4 + k 3 r 6 ) + p 1 ( r 2 + 2 y 2 ) + 2 p 2 x y
将畸变后的点通过内参数矩阵 投影到像素平面 ,得到该点在图像上的正确位置。
{
u
=
f
x
x
d
i
s
t
o
r
t
e
d
+
c
x
v
=
f
y
y
d
i
s
t
o
r
t
e
d
+
c
y
\left\{\begin{aligned} u = f_xx_{distorted}+c_x\\ v = f_yy_{distorted} +c_y \end{aligned}\right.
{ u = f x x d i s t o r t e d + c x v = f y y d i s t o r t e d + c y
小结:
首先,世界坐标系下有一个固定的点
P
\pmb{P}
P P P 世界坐标 为
P
w
\pmb{P_w}
P w P w P w
由于相机在运动,它的运动由
R
,
t
\pmb{R,t}
R , t R , t R , t
T
∈
S
E
(
3
)
\pmb{T}\in SE(3)
T T T ∈ S E ( 3 )
P
P
P 相机坐标 为
P
c
~
=
R
P
w
+
t
\tilde{\pmb{P_c}} = \pmb{RP_w+t}
P c P c P c ~ = R P w + t R P w + t R P w + t
这时的
P
c
~
\tilde{\pmb{P_c}}
P c P c P c ~
X
,
Y
,
Z
X,Y,Z
X , Y , Z
Z
=
1
Z = 1
Z = 1
P
P
P 归一化坐标 :
P
c
=
[
X
/
Z
,
Y
/
Z
,
1
]
T
\pmb{P_c} = [X/Z,Y/Z,1]^T
P c P c P c = [ X / Z , Y / Z , 1 ] T
有畸变时,根据畸变参数计算
P
c
\pmb{P_c}
P c P c P c
最后,
P
P
P 像素坐标 :
P
u
v
=
K
P
c
\pmb{P_{uv}} = \pmb{KP_c}
P u v P u v P u v = K P c K P c K P c
基线 baseline :都位于 x 轴上的两个相机的光圈中心间的距离 b
视差 disparity :左右图的横坐标之差 d
z
=
f
b
d
z = \dfrac{fb}{d}
z = d f b
d
=
u
L
−
u
R
d = u_L-u_R
d = u L − u R
通过红外结构光( Structured Light)来测量像素距离的。例子有 Kinect 1 代、 Project Tango1代、Intel RealSense 等。
通过飞行时间法( Time-of-flight,ToF)原理测量像素距离的。例子有Kinect 2 代和一些现有的ToF传感器等。
待补充。。。
讨论如何在有噪声的数据中进行准确的状态估计
{
x
k
=
f
(
x
k
−
1
,
u
k
)
+
w
k
运动方程
z
k
,
j
=
h
(
y
j
,
x
k
)
+
v
k
,
j
观测方程
\left\{ \begin{aligned} x_k&=f(x_{k-1},u_k)+w_k &\text{运动方程}\\ z_{k,j}&=h(y_j,x_k)+v_{k,j} &\text{观测方程} \end{aligned} \right.
{ x k z k , j = f ( x k − 1 , u k ) + w k = h ( y j , x k ) + v k , j 运动方程 观测方程
x
k
x_k
x k
y
j
y_j
y j
z
k
,
j
z_{k,j}
z k , j
w
k
w_k
w k
v
k
,
j
v_{k,j}
v k , j
u
k
u_k
u k
位姿
路标
像素位置
高斯噪声
输入,在视觉中暂且不谈
w
k
w_k
w k
N
(
0
,
R
k
)
N(0,R_k)
N ( 0 , R k )
v
k
v_k
v k
N
(
0
,
Q
k
,
j
)
N(0,Q_{k,j})
N ( 0 , Q k , j )
R
k
,
Q
k
,
j
R_k,Q_{k,j}
R k , Q k , j
我们希望通过带噪声的数据
z
z
z
u
u
u
x
x
x
y
y
y
增量法(滤波器):数据是随时间逐渐到来的,持有一个当前时刻的估计状态,用新的数据来更新它。仅关心当前时刻的状态估计
x
k
x_k
x k
3.对机器人状态的估计就是已知输入数据
u
u
u
z
z
z
x
,
y
x,y
x , y
P
(
x
,
y
∣
z
,
u
)
P(x,y|z,u)
P ( x , y ∣ z , u )
(
x
,
y
)
M
A
P
∗
=
a
r
g
m
a
x
P
(
x
,
y
∣
z
,
u
)
(x,y)_{MAP}^* = arg max P(x,y|z,u)
( x , y ) M A P ∗ = a r g m a x P ( x , y ∣ z , u )
P
(
x
,
y
∣
z
,
u
)
⏟
后验
=
P
(
z
,
u
∣
x
,
y
)
P
(
x
,
y
)
P
(
z
,
u
)
∝
P
(
z
,
u
∣
x
,
y
)
⏟
似然
P
(
x
,
y
)
⏟
先验
\underbrace{P(x,y|z,u)}_{\text{后验}} = \dfrac{P(z,u|x,y)P(x,y)}{P(z,u)} \propto \underbrace{P(z,u|x,y)}_{\text{似然}}\underbrace{P(x,y)}_{\text{先验}}
后验
P ( x , y ∣ z , u ) = P ( z , u ) P ( z , u ∣ x , y ) P ( x , y ) ∝ 似然
P ( z , u ∣ x , y ) 先验
P ( x , y )
所以求
(
x
,
y
)
M
A
P
∗
=
a
r
g
m
a
x
P
(
x
,
y
∣
z
,
u
)
(x,y)_{MAP}^* = arg max P(x,y|z,u)
( x , y ) M A P ∗ = a r g m a x P ( x , y ∣ z , u )
(
x
,
y
)
M
L
E
∗
=
a
r
g
m
a
x
P
(
z
,
u
∣
x
,
y
)
(x,y)_{MLE}^* = arg max P(z,u|x,y)
( x , y ) M L E ∗ = a r g m a x P ( z , u ∣ x , y )
直观讲,似然 是指“在现在的位姿下,可能产生怎样的观测数据 ”。由于我们知道观测数据,所以最大似然估计 可以理解成:“在什么样的状态下,最可能产生现在观测到的数据 ”。
对于某一次观测
z
k
,
j
=
h
(
y
j
,
x
k
)
+
v
k
,
j
z_{k,j}=h(y_j,x_k)+v_{k,j}
z k , j = h ( y j , x k ) + v k , j
观测数据的条件概率
P
(
z
j
,
k
∣
x
k
,
y
j
)
=
N
(
h
(
y
j
,
x
k
)
,
Q
k
,
j
)
P(z_{j,k}|x_k,y_j)=N(h(y_j,x_k),Q_{k,j})
P ( z j , k ∣ x k , y j ) = N ( h ( y j , x k ) , Q k , j )
这是一个高斯分布,可用最小化负对数求该分布的最大似然
(
x
k
,
y
j
)
∗
=
a
r
g
m
a
x
N
(
h
(
y
j
,
x
k
)
,
Q
k
,
j
)
(x_k,y_j)^* = arg max N(h(y_j,x_k),Q_{k,j})
( x k , y j ) ∗ = a r g m a x N ( h ( y j , x k ) , Q k , j )
我们发现,该式等价于最小化噪声项(即误差)的一个二次型。这个二次型称为马哈拉诺比斯距离,又叫马氏距离。它也可以看成是由
Q
k
,
j
−
1
Q_{k,j}^{-1}
Q k , j − 1
Q
k
,
j
−
1
Q_{k,j}^{-1}
Q k , j − 1
(
x
k
,
y
j
)
∗
=
a
r
g
m
i
n
(
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
T
Q
k
,
j
−
1
(
z
k
,
j
−
h
(
x
k
,
y
j
)
)
)
(x_k,y_j)^*=arg min ((z_{k,j}-h(x_k,y_j))^TQ_{k,j}^{-1}(z_{k,j}-h(x_k,y_j)))
( x k , y j ) ∗ = a r g m i n ( ( z k , j − h ( x k , y j ) ) T Q k , j − 1 ( z k , j − h ( x k , y j ) ) )
批量时刻的数据通常假设各个时刻的输入和观测是相互独立的,对联合分布进行因式分解:
P
(
z
,
u
∣
x
,
y
)
=
∏
k
P
(
u
k
∣
x
k
−
1
,
x
k
)
∏
k
,
j
P
(
z
k
,
j
∣
x
k
,
y
j
)
P(z,u|x,y) = \displaystyle{\prod_{k}}P(u_k|x_{k-1},x_k)\prod_{k,j}P(z_{k,j}|x_k,y_j)
P ( z , u ∣ x , y ) = k ∏ P ( u k ∣ x k − 1 , x k ) k , j ∏ P ( z k , j ∣ x k , y j )
e
u
,
k
=
x
k
−
f
(
x
k
−
1
,
u
k
)
e_{u,k}=x_k-f(x_{k-1},u_k)
e u , k = x k − f ( x k − 1 , u k )
e
z
,
j
,
k
=
z
k
,
j
−
h
(
x
k
,
y
j
)
e_{z,j,k}=z_{k,j}-h(x_k,y_j)
e z , j , k = z k , j − h ( x k , y j )
最小化所有时刻估计值与真实读数之间马氏距离,等价于求最大似然估计。负对数允许我们把乘积变成求和:
m
i
n
J
(
x
,
y
)
=
∑
k
e
u
,
k
T
R
k
−
1
e
u
,
k
+
∑
k
∑
j
e
z
,
k
,
j
T
Q
k
,
j
−
1
e
z
,
k
,
j
minJ(x,y) = \sum_k e_{u,k}^TR_k^{-1}e_{u,k}+\sum_k \sum_j e_{z,k,j}^TQ_{k,j}^{-1}e_{z,k,j}
m i n J ( x , y ) = k ∑ e u , k T R k − 1 e u , k + k ∑ j ∑ e z , k , j T Q k , j − 1 e z , k , j
这样就得到了一个最小二乘问题( Least Square Problem)
由于噪声的存在,当我们把估计的轨迹与地图代入 SLAM 的运动、观测方程中时,它们并不会完美地成立。这时怎么办呢?我们对状态的估计值进行微调,使得整体的误差下降一些。当然这个下降也有限度,它一般会到达一个极小值。这就是一个典型非线性优化的过程
考虑一个简单的最小二乘问题:
m
i
n
x
F
(
x
)
=
1
2
∣
∣
f
(
x
)
∣
∣
2
2
\underset{x}{min} F(x) = \frac{1}{2}||f(x)||_2^2
x min F ( x ) = 2 1 ∣ ∣ f ( x ) ∣ ∣ 2 2
1
2
\frac{1}{2}
2 1
下面讨论如何求解这样一个优化问题
如果
f
f
f
对于不方便直接求解的最小二乘问题,我们可以用迭代 的方式,从一个初始值出发,不断地更新当前的优化变量,使目标函数下降。
给定某个初始值
x
0
x_0
x 0
对于第
k
k
k
Δ
x
k
\Delta x_k
Δ x k
∥
f
(
x
k
+
Δ
x
k
)
∥
2
2
∥f (x_k + \Delta x_k)∥_2^2
∥ f ( x k + Δ x k ) ∥ 2 2
若
Δ
x
k
\Delta x_k
Δ x k
否则,令
x
k
+
1
=
x
k
+
∆
x
k
x_{k+1} = x_k + ∆x_k
x k + 1 = x k + ∆ x k
这让求解导函数为零的问题变成了一个不断寻找下降增量
∆
x
k
∆x_k
∆ x k
∆
x
k
∆x_k
∆ x k
现在考虑第
k
k
k
x
k
x_k
x k
∆
x
k
∆x_k
∆ x k
x
k
x_k
x k
F
(
x
k
+
∆
x
k
)
≈
F
(
x
k
)
+
J
(
x
k
)
T
∆
x
k
+
1
2
∆
x
k
T
H
(
x
k
)
∆
x
k
F(x_k + ∆x_k) ≈ F(x_k) + J (x_k)^T ∆x_k + \frac{1}{2}∆x_k^TH(x_k)∆x_k
F ( x k + ∆ x k ) ≈ F ( x k ) + J ( x k ) T ∆ x k + 2 1 ∆ x k T H ( x k ) ∆ x k
J
(
x
k
)
J(x_k)
J ( x k )
F
(
x
)
F(x)
F ( x )
x
x
x
H
H
H
一阶梯度法
∆
x
∗
=
−
J
(
x
k
)
∆x^∗ = −J(x_k)
∆ x ∗ = − J ( x k ) 最速下降法 。它的直观意义是只要我们沿着反向梯度方向前进,在一阶(线性)的近似下,目标函数必定会下降。
二阶梯度法
∆
x
∗
=
a
r
g
m
m
i
n
(
F
(
x
k
)
+
J
(
x
k
)
T
∆
x
+
1
2
∆
x
k
T
H
∆
x
k
)
∆x^∗ = arg mmin(F(x_k)+J(x_k)^T∆x + \frac{1}{2}∆x_k^TH∆x_k)
∆ x ∗ = a r g m m i n ( F ( x k ) + J ( x k ) T ∆ x + 2 1 ∆ x k T H ∆ x k )
J
+
H
∆
x
=
0
⇒
H
∆
x
=
−
J
J + H∆x = 0 \Rightarrow H∆x = −J
J + H ∆ x = 0 ⇒ H ∆ x = − J 牛顿法 。
最速下降法过于贪心,容易走出锯齿路线,反而增加了迭代次数。
H
H
H
H
H
H
将
f
(
x
)
f(x)
f ( x )
f
(
x
+
∆
x
)
≈
f
(
x
)
+
J
(
x
k
)
T
∆
x
k
f(x + ∆x) ≈ f(x) + J (x_k)^T ∆x_k
f ( x + ∆ x ) ≈ f ( x ) + J ( x k ) T ∆ x k
J
(
x
)
f
(
x
)
+
J
(
x
)
J
T
(
x
)
∆
x
=
0
J(x)f(x)+J(x)J^T(x)∆x = 0
J ( x ) f ( x ) + J ( x ) J T ( x ) ∆ x = 0
J
(
x
)
J
T
(
x
)
⏟
H
(
x
)
∆
x
=
−
J
(
x
)
f
(
x
)
⏟
g
(
x
)
\underbrace{J(x)J^T(x)}_{H(x)} ∆x = \underbrace{-J(x)f(x)}_{g(x)}
H ( x )
J ( x ) J T ( x ) ∆ x = g ( x )
− J ( x ) f ( x )
该方程是关于变量
∆
x
∆x
∆ x
H
H
H
g
g
g
H
∆
x
=
g
H∆x=g
H ∆ x = g
J
J
T
JJ^T
J J T
H
H
H
给定某个初始值
x
0
x_0
x 0
对于第
k
k
k
J
(
x
k
)
J(x_k)
J ( x k )
f
(
x
k
)
f(x_k)
f ( x k )
求解增量方程:
H
∆
x
=
g
H∆x=g
H ∆ x = g
若
Δ
x
k
\Delta x_k
Δ x k
x
k
+
1
=
x
k
+
∆
x
k
x_{k+1} = x_k + ∆x_k
x k + 1 = x k + ∆ x k
在使用高斯牛顿法时,可能出现
J
J
T
JJ^T
J J T
给
∆
x
∆x
∆ x
待补充
在实际中,还存在许多其他的方式来求解增量,例如 Dog-Leg等方法
图优化,是把优化问题表现成图( Graph) 的一种方式。这里的图是图论意义上的图。一个图
图6-2是一个简单的图优化例子。我们用三角形表示相机位姿节点,用圆形表示路标点,它们构成了图优化的顶点;同时,实线表示相机的运动模型,虚线表示观测模型,它们构成了图优化的边。此时,虽然整个问题的数学形式仍是最小二乘那样,但现在我们可以直观地看到问题的结构了。如果希望,也可以做去掉孤立顶点或优先优化边数较多(或按图论的术语,度数较大)的顶点这样的改进。但是最基本的图优化是用图模型来表达一个非线性最小二乘的优化问题。而我们可以利用图模型的某些性质做更好的优化。