在WALT里面,一个task的util大小,涉及到下面几个参数:
- WALT窗口大小
- cpu当前频率和cpu最高频率
- task在一个窗口实际运行时间
- task demand获取机制(比如最近窗口的数值,前五个窗口的最大数值等等)
在系统开机阶段已知的条件或者常量数值,举例如下:
- 小core的max_cap数值为488,A55,即cpu_scale数值。小core最高频率为1820MHZ
- 大core的max_cap数值为1024,A75,即cpu_scale数值,大core最高频率为2028MHZ
- WALT窗口大小数值为16ms
根据WALT算法,一个task的实际运行时间结果当前频率和当前cpu的最高的capacity scale之后时间作为WALT窗口真实运行时间。计算方式如下:
/*
* Translate absolute delta time accounted on a CPU
* to a scale where 1024 is the capacity of the most
* capable CPU running at FMAX
*/
static u64 scale_exec_time(u64 delta, struct rq *rq)
{
unsigned long capcurr = capacity_curr_of(cpu_of(rq));
return (delta * capcurr) >> SCHED_CAPACITY_SHIFT;
}
/*
* Returns the current capacity of cpu after applying both
* cpu and freq scaling.
*/
unsigned long capacity_curr_of(int cpu)
{
unsigned long max_cap = cpu_rq(cpu)->cpu_capacity_orig;
unsigned long scale_freq = arch_scale_freq_capacity(NULL, cpu);
return cap_scale(max_cap, scale_freq);
}
#define cap_scale(v, s) ((v)*(s) >> SCHED_CAPACITY_SHIFT)
经过上面公式整理最后的计算等式如下,delta是task在当前频率上面运行的时间
scale_time = delta *capcurr/1024
= delta * (max_cap * curr_freq *1024/cpuinfo.max_freq)/1024/1024
= delta *max_cap*curr_freq / (cpuinfo.max *1024) = demand
上面scale_time就是在当前WALT窗口scale出来的真实运行时间,即task p的demand数值,作为task util的依据。task util计算方式如下:
static inline unsigned long task_util(struct task_struct *p)
{
#ifdef CONFIG_SCHED_WALT
if (likely(!walt_disabled && sysctl_sched_use_walt_task_util))
return (p->ravg.demand /
(walt_ravg_window >> SCHED_CAPACITY_SHIFT));
#endif
return READ_ONCE(p->se.avg.util_avg);
}
可以知道task util数值如下:
task_util = demand *1024 / walt_ravg_window
= delta *max_cap *curr_freq / (cpuinfo.max_freq * 16)
16即为walt_ravg_window一个窗口的数值为16ms。本来这个数值应该为16000000,为了简化,delta数值都除以过了1000000。
计算公式如下

所以little core task计算公式如下:

big core task计算公式如下:

从上面公式很容易得出下面的结论:
如果task在两个不同的频率点(f1,f2,f1<f2)运行相同的时间,那么在更高频率点上面运行scale出来的demand数值会变大,从而导致最终的util变大。数值关系为u2 = (f2/f1)util,即是f2/f1的倍数关系。这样也好理解,一个task在小频率点需要运行这么长时间T1,那么在高频率点上面运行时间T2应该更短,T2 = (f1/f2)T1这么长的时间。
根据公式可以得到如下表格数据:

可以看到在最低频率614MHZ情况下,task在小core上面运行16ms的util数值仅仅为164.63297。如果当前频率为768MHZ,则运行16ms之后,util为205.92527=(768/614)*164.63297。与情况一致。
上面得出来的task的util数值。那么cpu的util怎么计算的?其实也是根据cpu rq上面task的情况来得到的,如果只有一个task在运行,那么cpu的util就是此task的util,否则就需要分情况分析。
我们首先需要了解下WALT是怎么计算cpu的util的。根据窗口策略来获取的:
最近窗口。
- 6个窗口的最大数值。
- 6个窗口的平均值
- 6个窗口的平均值与最近窗口数值,取最大数值。
注明:这6个窗口也包含了当前task正在运行的窗口
具体可以看到如下,使用WALT下cpu util怎么计算的:
static inline unsigned long cpu_util(int cpu)
{
struct cfs_rq *cfs_rq;
unsigned int util;
#ifdef CONFIG_SCHED_WALT
if (likely(!walt_disabled && sysctl_sched_use_walt_cpu_util)) {
u64 walt_cpu_util = cpu_rq(cpu)->cumulative_runnable_avg;
walt_cpu_util <<= SCHED_CAPACITY_SHIFT;
do_div(walt_cpu_util, walt_ravg_window);
return min_t(unsigned long, walt_cpu_util,
┊ capacity_orig_of(cpu));
}
#endif
cfs_rq = &cpu_rq(cpu)->cfs;
util = READ_ONCE(cfs_rq->avg.util_avg);
if (sched_feat(UTIL_EST))
util = max(util, READ_ONCE(cfs_rq->avg.util_est.enqueued));
return min_t(unsigned long, util, capacity_orig_of(cpu));
}
static inline unsigned long cpu_util_freq(int cpu)
{
#ifdef CONFIG_SCHED_WALT
u64 walt_cpu_util;
if (unlikely(walt_disabled || !sysctl_sched_use_walt_cpu_util)) {
return min(cpu_util(cpu) + cpu_util_rt(cpu),
capacity_orig_of(cpu));
}
walt_cpu_util = cpu_rq(cpu)->prev_runnable_sum;
walt_cpu_util <<= SCHED_CAPACITY_SHIFT;
do_div(walt_cpu_util, walt_ravg_window);
return min_t(unsigned long, walt_cpu_util, capacity_orig_of(cpu));
#else
return min(cpu_util(cpu) + cpu_util_rt(cpu), capacity_orig_of(cpu));
#endif
}
可以看到,cpu_util_freq和cpu_util两个
- cpu_util_freq使用了之前窗口的数值,使用在schedutil governor里面计算cpu util使用的
- cpu_util使用了当前窗口内所有runnable task的demand之和作为此时的util数值,使用在load balance处。

task为p.
WS:当前窗口启动时间
ms:task标记运行时间
wc:当前需要重新计算task demand的系统当前时间
上面WS1是当前窗口的启动时间,WS2是下一个窗口的启动时间,WS2-WS1=16ms
ms1是task第一次运行时候的时间,一般为fork时间或者wakeup时间
wc时间一般是此时需要统计task demand的时刻。时机在每次fork,wakeup,tick期间。对于task运行长时间,一般都是在每次tick作为update task和cpu util的时机。对上面的图形解释如下:
- ms1 task被wakeup,有一个初始数值demand,获取得到task的初始util,如果符合频率变化需求则会主动去触发频率变化
- wc1是此task运行一个tick之后,需要更新此task的最新的util,即会更加上面的公式,scale本次运行一个tick时间的真实时间并累加到task的demand sum变量中,即p->ravg.sum +=scale_time;
- wc2与2类似,继续累加p->ravg.sum
- wc3与2也类似,不同之处在与,scale的时间为WS2-ms2,累加到p->ravg.sum
- 在wc3处update history value。这时候会将此时p->ravg.sum放置在最近的窗口里面占据一个窗口。
- 从wc4开始与上面类似,如此的循环往复,直到此task的运行完毕或者util增大到系统cpu能够容纳的capacity的上限为止。
OK,上面理解了运行时间如果scale为计算util的真实时间。看到cpu util有两种计算方式
- cpu_util,使用的cumulative_runnable_avg,这就是本次窗口的数值,也就是所有在此窗口内处于runnable状态 此rq task的demand的累加和。
- cpu_util_freq,使用的prev_runnable_sum,是上一个窗口的累加。这里面其实存在一个问题的,如果prev_runnable_sum比较小,但是task一直在当前窗口运行,会导致prev_runnable_sum会延迟一个窗口更新,也就会延迟cpu频率的升高。所以如果一个task持续运行,占满多个窗口。这个问题复原如下:

存在三种可能性,task跨窗口,到底选择cumulative_runnable_avg还是prev_runnable_sum作为频率调节的依据,没有谁好谁不好,但是prev_runnable_sum有一个明显的优势就是,如果一个task在一个窗口内完整运行过了,那么prev_runnable_sum数值就很大了。所以必须有一个两全其美的方案,否则会影响性能。
上面已经知道cpu util怎么来了。下面看看,schedutil如何根据cpu util来降低或者升高频率。
static unsigned int get_next_freq(struct sugov_policy *sg_policy,
┊ unsigned long util, unsigned long max)
{
struct cpufreq_policy *policy = sg_policy->policy;
unsigned int freq = arch_scale_freq_invariant() ?
policy->cpuinfo.max_freq : policy->cur;
int freq_margin = sg_policy->tunables->freq_margin;
if (freq_margin > -100 && freq_margin < 100)
freq_margin = ((int)freq * freq_margin) / 100;
else
freq_margin = freq >> 2;
freq = div64_u64((u64)((int)freq + freq_margin) * (u64)util, max);
if (freq == sg_policy->cached_raw_freq && sg_policy->next_freq != UINT_MAX)
return sg_policy->next_freq;
sg_policy->cached_raw_freq = freq;
return cpufreq_driver_resolve_freq(policy, freq);
上面的代码是经过修改过的,原始代码如下:
static unsigned int get_next_freq(struct sugov_policy *sg_policy,
unsigned long util, unsigned long max)
{
struct cpufreq_policy *policy = sg_policy->policy;
unsigned int freq = arch_scale_freq_invariant() ?
policy->cpuinfo.max_freq : policy->cur;
freq = (freq + (freq >> 2)) * util / max;
if (freq == sg_policy->cached_raw_freq && sg_policy->next_freq != UINT_MAX)
return sg_policy->next_freq;
sg_policy->cached_raw_freq = freq;
return cpufreq_driver_resolve_freq(policy, freq);
}
差异就是原始版本,每次的频率base都是增加25%,而修改的版本将这个数值作为变动的来调节。
通过上面的计算方式能够得到下面的公式如下:
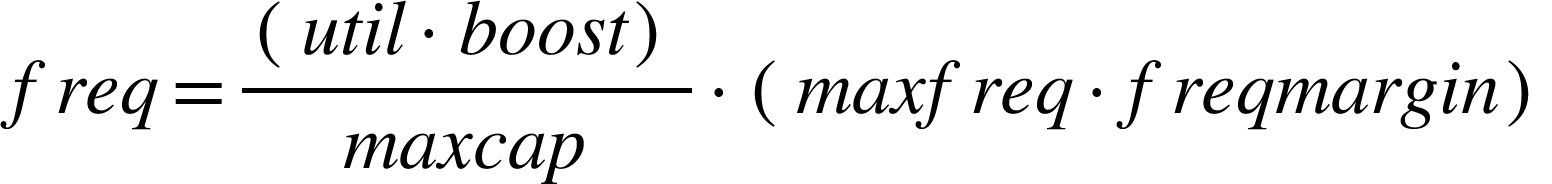
对于little core,频率计算方式:
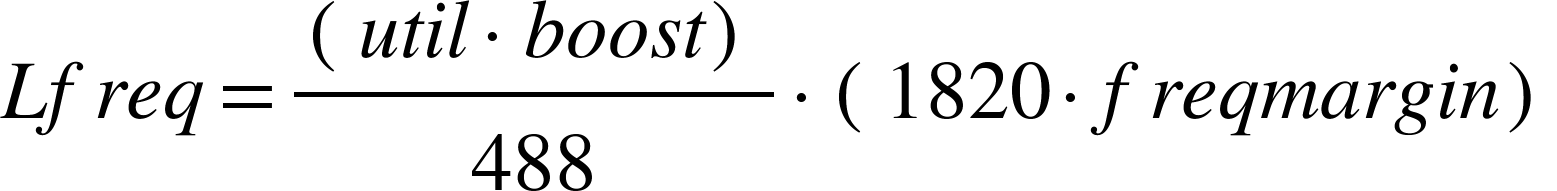
对于little core,频率计算方式:
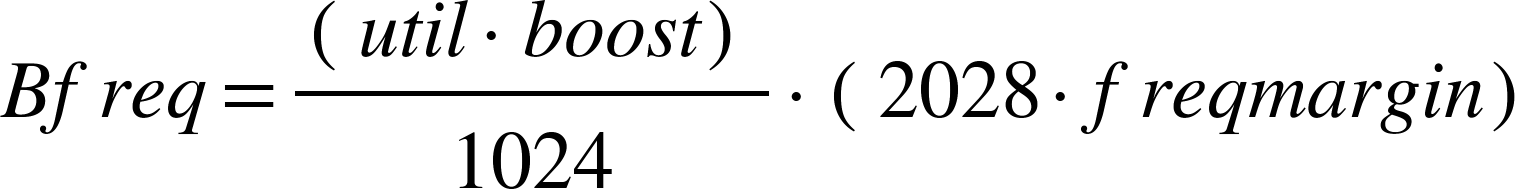
根据公式计算出的数值如下,boost=1,freqmargin=1.

可以看到,对于大小core来说,只有足够大的util才能够升高频率
具体的变化可以参考下面的公式演示图:
https://www.desmos.com/calculator/hgnv25fibc
