版本
spark 2.1.0
前言
利用spark-submit提交作业的时候,根据各种天花乱坠的教程我们会指定一大堆参数,借以提升并发和执行性能,比如
–executor-cores 4
–num-executors 4
–executor-memory 8g
–conf spark.default.parallelism=50
–conf spark.sql.shuffle.partitions=20
结果发现一顿操作下来
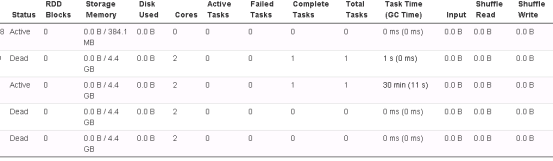
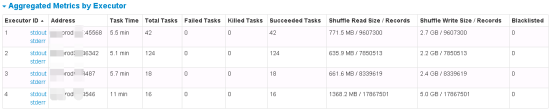
executor就用起来了一个,写入task也就只有一个
解析
其实由spark执行原理我们知道

- 一个executor可以执行多个task
- 多个executor执行批量task则形成了并发任务集群
然而现在的情况是总共就两个task,而其中最耗时的map以及写入全部集中于一个task中,这样executor-cores,num-executors完全就没用嘛!
这个时候就应该从代码层面进行处理。
首先代码使用的是sparksql,读取数据并校验写入hbase,操作为map。
再来看spark.default.parallelism,spark.sql.shuffle.partition这两个参数干嘛用的?官网文档如下
| 参数 | 默认值 | 用途 |
|---|---|---|
| spark.default.parallelism | For distributed shuffle operations like reduceByKeyand join, the largest number of partitions in a parent RDD. For operations like parallelizewith no parent RDDs, it depends on the cluster manager:Local mode: number of cores on the local machine Mesos fine grained mode: 8Others: total number of cores on all executor nodes or 2, whichever is larger | Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user. |
| spark.sql.shuffle.partitions | 200 | Configures the number of partitions to use when shuffling data for joins or aggregations. |
由表格以及描述我们可以直到,一个是用于rdd处理的,而sparksql dataframe使用的spark.sql.shuffle.partitions也仅针对于join和aggregations,那这样确实不起作用,这个时候需要在代码里手动指定repartition。
优化
在spark2.1.0里,repartition有三个方法,分别是
def repartition(numPartitions: Int): Dataset[T] = withTypedPlan {
Repartition(numPartitions, shuffle = true, logicalPlan)
}
def repartition(numPartitions: Int, partitionExprs: Column*): Dataset[T] = withTypedPlan {
RepartitionByExpression(partitionExprs.map(_.expr), logicalPlan, Some(numPartitions))
}
def repartition(partitionExprs: Column*): Dataset[T] = withTypedPlan {
RepartitionByExpression(partitionExprs.map(_.expr), logicalPlan, numPartitions = None)
}
可以看到该方法可以接收int直接指定分区数,也可以通过字段动态/固定分区。我们先用def repartition(numPartitions: Int)这个方法试一下效果,既然服务器运算节点是4个,num-executors也设定为4,这个时候并发的任务数也设定为4的倍数,读取的dataframe先设置12,写入hbase时也设置为4。
var repItems = items.repartition(12);
itemsOut.repartition(4).saveAsNewAPIHadoopDataset(itemJob.getConfiguration)


很好,可以很直观的看到数据已经划分为多个任务,也开始并发执行了。
但是,固定写死分区数并不是很优雅,这个时候有两个办法
1、我们可以通过环境变量或是脚本参数动态指定拉取分区数;
2、通过repartition(partitionExprs: Column*)方法,根据字段动态分配。
接下来采用动态分区试一下,我使用时间字段effectiveTime来根据月份进行划分,同时还需要自己编写udf进行规则处理
val timeRepartition = (effectiveTime:Date) => {
var timeflag = "";
if(effectiveTime==null){
timeflag = "2020-01"
}else{
timeflag= effectiveTime.getYear+""+"-"+effectiveTime.getMonth+"";
}
timeflag
}
val timeRep = udf(timeRepartition)
var repItems = items.repartition(timeRep(items("effective_time")));
执行结果如下,可以看出划分出了默认的200个task,且实际上不是task越多越好,对比一下可以发现,划分合理速度更快
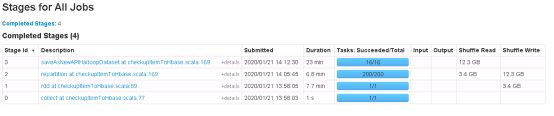
12/4划分与200/16划分对比
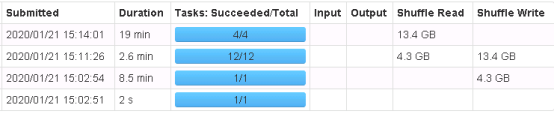
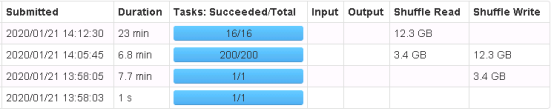
此外数据库effectiveTime的月份统计实际不到120条,且存在严重的数据倾斜
时间数据倾斜。针对数据倾斜问题,下一章根据repartion源码解析继续深入。
动态划分结果数据倾斜比较严重