认识Hystrix
Hystrix是Netflix开源的一款容错框架,包含常用的容错方法:线程池隔离、信号量隔离、熔断、降级回退。在高并发访问下,系统所依赖的服务的稳定性对系统的影响非常大,依赖有很多不可控的因素,比如网络连接变慢,资源突然繁忙,暂时不可用,服务脱机等。我们要构建稳定、可靠的分布式系统,就必须要有这样一套容错方法。
本文将逐一分析线程池隔离、信号量隔离、熔断、降级回退这四种技术的原理与实践。
dubbo熔断,Hystrix问的少
无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部 hang (挂起)在这个资源上,造成整个系统不可用。降级在高并发系统中是非常正常的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。
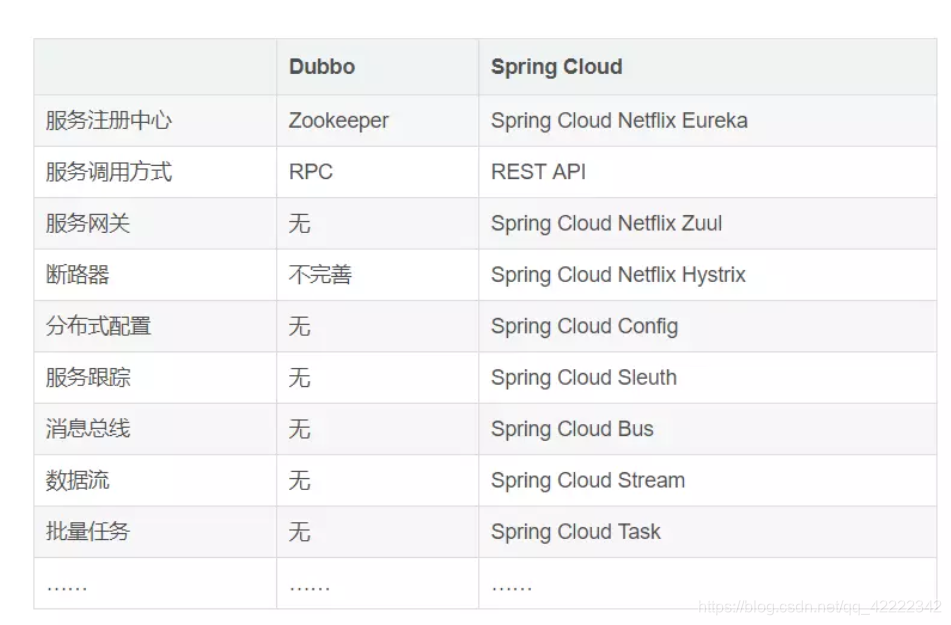 dubbo和spring cloud区别
dubbo和spring cloud区别
服务降级限流熔断
在进入正题之前,有个问题,分布式系统中肯定会遇到服务雪崩效应,这个服务雪崩效应是什么呢?
下面这幅图可以说明这个问题
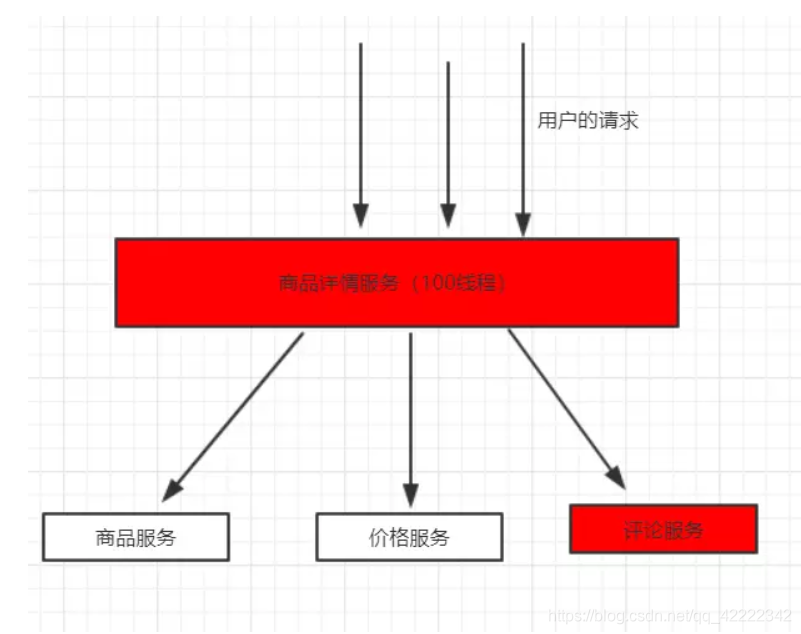 服务雪崩图
服务雪崩图
商品详情展示服务会依赖商品服务, 价格服务,商品评论服务,调用三个依赖服务会共享商品详情服务的线程池,如果其中的商品评论服务不可用(超时,代码异常等等), 就会出现线程池里所有线程都因等待响应而被阻塞, 从而造成服务雪崩。
概况一下就是:因服务提供者的不可用导致服务调用者的不可用,并将不可用逐渐放大的过程,就叫服务雪崩效应,这句话应该很好理解,就不过多的解释了。
到这里就知道了雪崩的原因是服务提供者的不可用导致的,那么什么是导致服务提供者的不可用呢?无非就这么几点:大流量请求(高并发),提供者硬件问题,缓存击穿,程序的bug,超时等等
到这里想想怎么解决?第一个想到的就是,重试,当服务的提供方不可用时,重试无形中增加了提供方的压力,所以重试不可取。
到这里瓶颈了,再想想是不是哪里有问题,服务雪崩的根本原因到底是什么?
应该是:
大量请求线程同步等待造成的资源耗尽
当服务调用者使用同步调用的时候,会产生大量的等待线程占用系统资源,一旦线程资源被耗尽,
服务调用者提供的服务也将处于不可用状态,于是服务雪崩效应产生了!
知道了根本原因,问题来了,怎么解决呢?这里才入正题,是不是引子有些长?
解决方案
1,超时机制
2,服务限流
3,服务熔断
4,服务降级
超时机制
如果我们加入超时机制,例如2s,那么超过2s就会直接返回了,那么这样就在一定程度上可以抑制消费者资源耗尽的问题
服务限流
通过线程池+队列的方式,通过信号量的方式。比如商品评论比较慢,最大能同时处理10个线程,队列待处理5个,那么如果同时20个线程到达的话,其中就有5个线程被限流了,其中10个先被执行,另外5个在队列中
服务熔断
这个熔断可以理解为我们自己家里的电闸。
当依赖的服务有大量超时时,在让新的请求去访问根本没有意义,只会无畏的消耗现有资源,比如我们设置了超时时间为1s,如果短时间内有大量请求在1s内都得不到响应,就意味着这个服务出现了异常,此时就没有必要再让其他的请求去访问这个服务了,这个时候就应该使用熔断器避免资源浪费
服务降级
有服务熔断,必然要有服务降级。
所谓降级,就是当某个服务熔断之后,服务将不再被调用,此时客户端可以自己准备一个本地的fallback(回退)回调,返回一个缺省值。 例如:(备用接口/缓存/mock数据),这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当然这也要看适合的业务场景
