对于一个消息队列来说,系统由很多机器组成,每个机器角色,ip 地址都不相同,而且这些信息是变动的。这种情况下,如果一个新的生产者或者消费者加入,怎么配置连接信息呢?Nameserver 的存在就是为了解决这些问题,由Nameserver维护这些配置信息、状态信息、其它角色都通过Nameserver协同执行。
Nameserver 的功能
Nameserver是真个消息队列中的状态服务器,集群的各个组件都通过它来了解全局的信息,同时,各个角色的机器都要定期的向Nameserver上报自己的状态信息,超时不上报的话会认为某个机器出现了故障不可用,其它的组件会把这个机器从列表中移除。Nameserver可以部署多个,相互之间独立,其它绝俗同时向Nameserver机器上报自己的状态信息,从而达到热备份的目的。Nameserver本身是无状态的,也就是说Nameserver的broker、topic等状态信息不会持久存储,都是由各个角色的定时上报存储在内存中(Nameserver支持配置参数化的持久化,一般用不到)。
Nameserver在mq中扮演着调度中心的角色,哥哥生产者、消费者上报自己的状态上去,同时从Nameserver获取其它角色的状态信息。Nameserver的功能虽然非常重要但是却被设计的很轻量,代码量少,并且几乎无磁盘存储,所有的功能都是通过内存高效完成,rocketmq基于netty对底层通信做了很好的抽象,使得通信功能逻辑清晰代码简单。具体参考:
集群状态的存储结构
在org.apache.rocketmq.namesrv.routeinfo 的 RouteInfoManager 类中有5个变量,集群的状态就是保存在这5个变量中。
Broker 的功能
扫描二维码关注公众号,回复: 8754721 查看本文章
Brokerde 是rocketmq的核心,大部分“重量级”的工作都是由它完成的。包括接受生产者发过来的消息、处理消费者的消息请求、消息的持久化操作、消息的HA机制以及服务端过滤功能等。
消息存储和发送
分布式队列因为由高可靠的要求,所以数据要通过磁盘进行持久化存储,用磁盘存储消息速度会不会很慢呢?能满足实施性和高吞吐的要求吗?
实际上,磁盘有时候会比你想象的快很多,有时候也会比你想象的慢很多,关键在如何使用,使用得当,磁盘速度可以匹配网络传输的速度。目前的高性能网盘,顺序写速度可以达到600mb/s,超过了一般的网卡速度,这是磁盘比想象快的地方,但是磁盘的随机读写的速度大概只有100kb/s,和顺序读写性能相差600倍!因为由如此大的速度差别,好的消息队列系统和普通的消息队列系统快个数量级。
举个例子,linux操作系统分为“用户态”和“内核态”,文件操作、网络操作需要涉及这种形态的切换,免不了进行数据复制,一台服务器把本机磁盘文件内容发送到客户端,一般分为两个步骤:
- read(file,temp,buf,len)
- write(socket,tmp_buf,len)
tmp_buf 是预先申请的内存,这两个看似简单的饿操作,实际上进行了4次数据复制,分别是:从磁盘复制数据到内核态内存,从内核态内存复制数据到用户态内存(完成了read);然后从用户态内存复制到网络驱动的内核态内存,最后是从网络驱动的内核态内存复制到网卡中进行传输(完成write)

通过使用mmap的方式,可以省去向用户态的内存复制,提高速度,这种机制在Java中是通过MapendByteBuffer实现的,rocketmq充分利用了上述特性,也就是“零拷贝”技术,提高消息的存盘和网络发送的速度。
消息的存储结构
rocketmq的具体的消息存储结构是怎样的呢?如何尽量保证顺序写呢?先来看看整体的架构图:

不论是生产者还是消费者都先向NameServer上报自己的信息,NameServer收到后则会将你注册到注册中心,就好比客户端向服务端发出请求,那么客户端代码里必须指定服务端的IP对吧,而客户端自然而然就能收到客户端的请求,自然也就将你的各种路由信息给注册进去了,至于消息该怎么发送到哪个broker地址,我猜测应该是生产者和消费者通过topic关联,就能寻找到对应的broker的地址了,那么NameServer就会将消息发送到关联的broker上(集群则是其中的一台)。

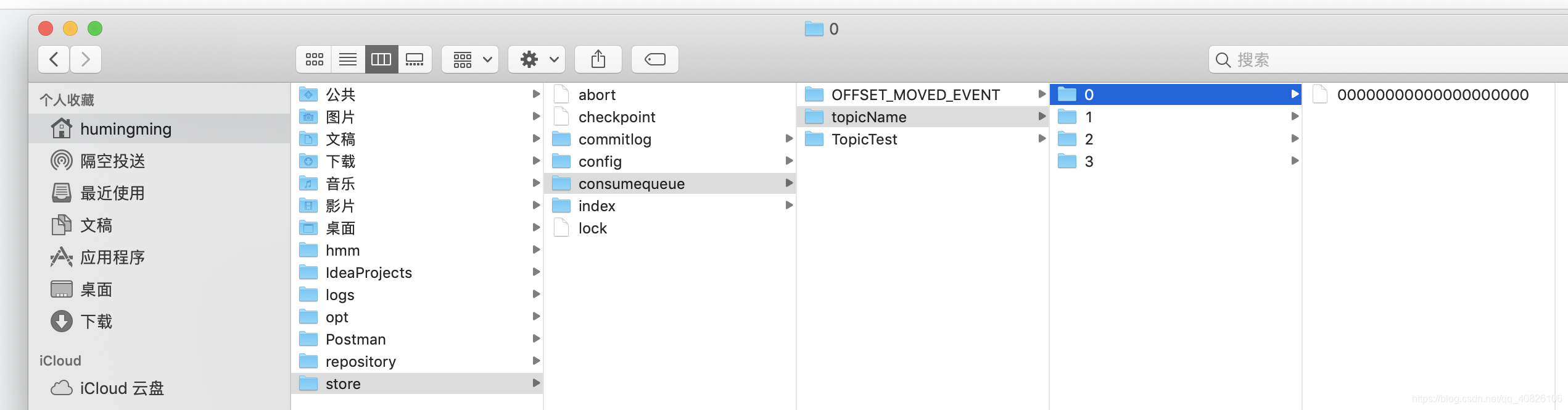
rocketmq 的消息存储是由ConsumeQueue 和 CommitLog 配合完成,消息真正的物理存储文是CommitLog,ConsumeQueue是消息的逻辑队列,类似于数据库的索引文件,存储的是只想物理存储的地址,每个topic的每个消息队列都有一个对应的ConsumeQueue文件, 二者都是二进制文件。文件的地址在${$storeRoot}\consumequeue\${topicName}\${queueId}\${fileName},ConsumeQueue只是存储了消息在commitLog的起始偏移量offset,消息大小size和消息Tag的HashCode值。
CommitLog 以物理文件方式存放,每台Broker上的 CommitLog被本机器所有的索引文件也就是ConsumeQueue共享,文件地址${user.home}\store\${commitlog}\${fileName},在CommitLog中一些消息的长度是不固定的,rocketmq 采取一些机制,尽量向CommitLog中顺序写,但是随机读。ConsumeQueue的内容也会被写到磁盘作为持久存储。存储机制这样设计的好处就是:
- CommitLog顺序写,可以大大提高写入的效率
- 虽然是随机读,但是利用操作系统的pagecache机制,可以批量的从磁盘读取作为cache存到内存中,加速后续的读取速度
- 为了保证完全的顺序写,需要ConsumeQueue这个中间结构,因为ConsumeQueue里只存了偏移量信息,所以尺寸是有限的,在实际情况中,大部分的ConsumeQueue能够被全部读入到内存,所以中间结构的操作速度很快,可以认为是内存读取的速度。此外为了保证CommitLog和ConsumeQueue的一致性,CommitLog里存储了consume queue、message key、tag等所有信息,即使ConsumeQueue丢失也能通过CommitLog完全恢复过来。
关于消息存储看了一篇写的非常好的文章:地址,推荐大家去学习。
高可用机制
RocketMq分布式集群是通过master和slave的配合达到高可用的,首先说明下master和slave的区别:在broker配置文件中,参数brokerId的值为0表明这个是broker的master,大于0则表明是broker的slave,同时broker的参数(brokerRole:slave)也会说明这个是master还是slave。master角色支持读和写,slave的角色仅支持读,也就是生产者只能和master角色的broker连接写入消息;consume可以连接master角色的broker,也可以连接slave角色的broker来读取消息。
在consume的配置文件中,并不需要设置是从 master读还是slave读,当master不可用或者繁忙的时候,消费者会被自动切换到slave读,有了自动切换consumer的机制,当master角色的机器出现故障后,consumer仍然可以从slave读取消息,不影响consumer的程序,这就达到了消费端的高可用。
如何达到消费端的高可用?在创建topic的时候会把多个消息队列的创建放在多个broker组上(相同的broker名称(brokerName相同表明是同一个broker),不同的brokerId的机器组成的一个broker组),这样当一个broker组的master不可用之后,其它组的master仍然可用,生产者仍然可以发送消息,rocketmq目前尚不支持类似于redis的选举,也就是自动把slave转成master,如果机器资源不足,需要把slave转成master,则要手动停止slave角色的broker,更改其配置文件并重启。
同步刷盘和异步刷盘
RocketMQ 的消息是存在磁盘伤的,这样既能保证断电恢复,又可以让消息存储超出内存的限制。RocketMQ为了提高性能会尽可能的保证顺序写。消息在通过生产者发送到RocketMQ的时候,有两种写磁盘的方式。
- 异步刷盘方式:在返回写成功状态时,消息可能只是被写入了内存的pagecache , 写操作返回的快,吞吐量大;当内存的消息积累到一定程度的时候统一触发写磁盘操作,快速写入。
- 同步刷盘方式:写返回成功状态时,消息已经被写入磁盘。具体流程是消息写入内存的pagecache后,立即通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写成功的状态

同步刷盘还是异常刷盘是通过配置文件的flushDiskType 参数设置的,这个参数被设置为SYNC_FLUSH ASYNC_FLUSH的一个。
同步复制和异步复制
如果一个broker组有master和slave,消息需要从master复制到slave上,有同步复制和异步复制两种方式。同步复制是等master和slave均写成功后才反馈给客户端成功状态;异步复制方式是要master写成功即可反馈给客户端写成功状态。
这两种复制方式各有优劣,在异步复制的方式下,系统拥有较低的延迟和较高的吞吐量,但是如果master出现了故障,有数据因为没写入slave,有可能会丢失;在同步复制的情况下,然后master 出现故障,slave上有全部的备份数据,容易恢复,但是同步复制数据会增大数据的写入延迟,降低系统的吞吐量。
同步复制和异步复制是通过broker配置文件里的brokerRole 参数进行设置的,这个参数可以被设置为ASYNC_MASTER、SYNC_MASTER、SLAVE(备份机)三种的一个。实际应用中要结合业务场景,合理的设置刷盘方式和复制方式,尤其是刷盘方式SYNC_FLUSH方式,由于频繁的触发磁盘写操作,会明显降低性能主从之间配置成SYNC_MASTER的复制方式可以保证消息不丢失,即使一台机器故障数据仍然可以被消费。

消息发送的结果
- SEND_OK:消息发送成功
-
FLUSH_DISK_TIMEOUT: 如果Broker设置MessageStoreConfig的FlushDiskType = SYNC_FLUSH(默认为ASYNC_FLUSH),并且Broker没有在MessageStoreConfig的syncFlushTimeout(默认为5秒)内完成刷新磁盘,则会获得此状态。这里指的是同步刷盘会出现这个情况(异步刷盘写入内存就返回成功)消息虽然已经进入到master的broker服务器,但是若服务器宕机消息会丢失。
-
FLUSH_SLAVE_TIMEOUT:如果Broker的角色是SYNC_MASTER(默认为ASYNC_MASTER),并且从属Broker未在MessageStoreConfig的syncFlushTimeout(默认为5秒)内完成与主服务器的同步(同步复制),则会获得此状态。这里指的是同步复制会出现上述情况,若此时主服务器宕机消息也会丢失。
-
如果Broker的角色是SYNC_MASTER 同步复制(默认为ASYNC_MASTER),但没有配置slave Broker或者slave broker 不可用,您将获得此状态,若此是服务器宕机,消息会丢失。(主备切换失效)
此时,一般生产上的处理是只要消息发送没出现异常,这几种状态一般是不做处理,因为消息已经发送成功了,至于有没有被同步到slave或者持久化到磁盘,我们都不用太关心,如果你要对消息状态做处理,比如消息发送只要不等于OK则你认为消息发送失败,则你会再一次发送同样的消息,但实际则条消息是存在的,如果你重复发送,你消费端做好幂等就行。
