Django ORM models操作
Django ORM基本操作
一、数据库的创建及增删改查
1 使用类创建表
- 在models.py中
from django.db import models - 继承models.Model
1 写类,对应表名
from django.db import models
class UserInfo(models.Model): name = models.CharField(max_length=16) age = models.IntegerField()- 设置外键
ut = models.ForeignKey('UserType') - 设置外键可以为空, null=True ut = models.ForeignKey('UserType',null=True)
- 生成的外键在数据库中是ut_id,自动添加了下划线+id
class UserType(models.Model): """ 用户组 """ title = models.CharField(max_length=32) def __str__(self): return "%s-%s" % (self.id, self.title) class UserInfo(models.Model): """ 用户表 """ name = models.CharField(max_length=16) age = models.IntegerField() ut = models.ForeignKey('UserType',null=True) # 设置外键2 注册app
在setting中注册app的名字,下面的都会在数据库中生成表,都有相应的用处
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'app01', ]3 生成表
python3 manage.py makemigratons
python3 manage.py migrate2 修改数据库
如果数据库中有数据,想添加一列的时候,数据库会提示。。。,解决方式:
- null=True 设置默认为空
- default=1 设置默认值为1
from django.db import models
class UserInfo(models.Model): name = models.CharField(max_length=16) age = models.IntegerField() email = models.CharField(null=True) email = models.CharField(default=1)增删改查
# 增加数据
models.UserInfo.objects.create(name='aaa',age='18',ut_id='1') # 注意外键是一行对象,用表中额ut_id # 查询数据 models.UserInfo.objects.all() # 过滤 models.UserInfo.objects.filter(name='xxx') # 更新 models.UserInfo.objects.update(name='ddd')二、连表操作
1 外键连表
连一张表的情况
UserType表:

UserInfo表: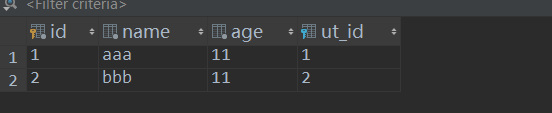
下面是通过UserInfo表中的外键ut,此时的ut就代表UserType这个表的一行对象,直接用item.ut.title就可以进行连表查询。
def test(request): user_list = models.UserInfo.objects.all() for item in user_list: print(item.age,item.name,item.ut_id,item.ut.title) # 通过外键进行连表查看原生SQL语句
使用query进行查看,可以查看models的SQL操作。

user_list = models.UserInfo.objects.all()
print(user_list.query)SELECT "app01_userinfo"."id", "app01_userinfo"."name", "app01_userinfo"."age", "app01_userinfo"."ut_id" FROM "app01_userinfo"连多张表的情况
class UserType(models.Model): """ 用户类型 """ title = models.CharField(max_length=32) fo = models.ForeignKey('Foo')在UserType表中添加外键fo,关联Foo表
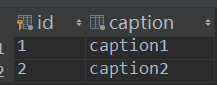
使用item.ut.fo.caption可以通过外键一致点。
def test(request): user_list = models.UserInfo.objects.all() for item in user_list: print(item.age,item.name,item.ut_id,item.ut.fo.caption)2 正向操作
- 一个用户只有一个用户类型
- 正向操作关键,含有FK,直接点的
obj = models.UserInfo.objects.all().first() # 这是获取的第一个对象
print(obj.name,obj.age,obj.ut.title)3 反向操作
- 一个用户类型有多个用户
- 使用的前提是获得是一个对象,然后用这个对象进行小写的表名字_set
- 要关联的表的小写的表明加下划线set
- 如UserType反向去取UserInfo中的内容,userinfo_set.all()
obj = models.UserType.objects.all().first()
print(obj.id,obj.title,obj.userinfo_set.all())结果:通过反向查表获得是另一个表的QuerySet对象
1 技术部 <QuerySet [<UserInfo: UserInfo object>]>下面可以通过UserType反向查询到UserInfo表中的内容,当然还可以用外键进行连表,就没有意义了
obj = models.UserType.objects.all().first()
for item in obj.userinfo_set.all(): print(item.id,item.name,item.age)或者
user_list = models.UserType.objects.all()
for obj in user_list: for obj2 in obj.userinfo_set.all(): # 再进行循环 print(obj2.name,obj2.age)4 values和value_list
values
- values获得是Quseryset对象,内部的数据代表获得的列
- 数据类型是字典类型
result = models.UserInfo.objects.all().values('id','name') # 拿到的是两列数据 for item in result: print(item)结果是字典类型
{'id': 1, 'name': 'aaa'}
{'id': 2, 'name': 'bbb'}用values进行跨表:
- 这种不是在for循环的时候跨表了,是在查询的时候进行的跨表,然后对获取的数据进行的遍历,效率高
- 使用外键+双下划线+字段名
result = models.UserInfo.objects.all().values('id', 'name','ut__title') # 拿到的是两列数据 for item in result: print(item['id'],item['name'],item['ut__title'])value_list
- value_list的数据是元组类型
result = models.UserInfo.objects.all().values_list('id', 'name') for item in result: print(item)结果:
(1, 'aaa')
(2, 'bbb')- 使用values_list进行跨表,也是在查询的时候获取
- 数据是元组,通过双下划线
- 是通过索引进行取值的
result = models.UserInfo.objects.all().values_list('id', 'name','ut__title') # 拿到的是两列数据 for item in result: print(item[0],item[1],item[2])5 values和value_list 反向操作
使用小写的表名+双下划线
v = models.UserGroup.objects.values('id','title','userinfo__age') # userinfo__age v = models.UserGroup.objects.values_list('id','title','userinfo__age') 跨表操作大总结
class UserGroup(models.Model): """ 部门 """ title = models.CharField(max_length=32) class UserInfo(models.Model): """ 员工 """ nid = models.BigAutoField(primary_key=True) user = models.CharField(max_length=32) password = models.CharField(max_length=64) age = models.IntegerField(default=1) ug = models.ForeignKey("UserGroup",null=True) - 跨表 正: 1. q = UserInfo.objects.all().first() q.ug.title 使用外键点 2. models.UserInfo.objects.values('nid','ug_id') models.UserInfo.objects.values('nid','ug_id','ug__title') # 使用外键__+字段 3. models.UserInfo.objects.values_list('nid','ug_id','ug__title') 反: 1. 小写的表名_set obj = UserGroup.objects.all().first() result = obj.userinfo_set.all() [userinfo对象,userinfo对象,] 2. 小写的表名 v = models.UserGroup.objects.values('id','title') v = models.UserGroup.objects.values('id','title','小写的表名称') # userinfo v = models.UserGroup.objects.values('id','title','小写的表名称__age') # userinfo__age v = models.UserGroup.objects.values('id','title','小写的表名称__ug_id') # 关联的是字段外键ug_id 3. 小写的表名 v = models.UserGroup.objects.values_list('id','title') v = models.UserGroup.objects.values_list('id','title','小写的表名称') v = models.UserGroup.objects.values_list('id','title','小写的表名称__age') v = models.UserGroup.objects.values_list('id','title','小写的表名称__ug_id') # 关联的是字段外键ug_id related_name=None, # 反向操作时,使用的字段名,用于代替 【表名_set】 如: obj.表名_set.all() OnetoOne 一对一 操作
假如用户模型中有个 Person 模型,它通过属性 user=models.OneToOneField(User) 与框架的 User 建立起一对一映射。在使用时 user 是一个 User 对象,user.person 可以获得对应的 Person 对象。
进阶操作
排序
- order_by进行排序
- 如有order_by('-id','name') 先排id,id有相同的再拍name
- 加减号是反向排序
user_list = models.UserInfo.objects.all().order_by('-id')
print(user_list) 结果:
<QuerySet [<UserInfo: 2-bbb>, <UserInfo: 1-aaa>]>分组
- 分组用values和annotate
- values是获取一列数据
- annotate是加聚合函数的
- 内部用Count
- c是别名
- 导入from django.db.models.aggregates import Count,Sum,Max,Min
- 设置了自动导入模块 快捷键是alt+M
obj = models.UserInfo.objects.all().values_list('ut__id').annotate(c=Count('id')) print(obj.query)原生的SQL语句:
SELECT "app01_userinfo"."ut_id", COUNT("app01_userinfo"."id") AS "c" FROM "app01_userinfo" GROUP BY "app01_userinfo"."ut_id"分组后筛选
- SQL中是Having
- 这里用filter,而且是在后面
- filter在前面是Where
obj = models.UserInfo.objects.all().values_list('ut__id').annotate(c=Count('id')).filter(c__gt=1) print(obj.query)SQL:
SELECT "app01_userinfo"."ut_id", COUNT("app01_userinfo"."id") AS "c" FROM "app01_userinfo" GROUP BY "app01_userinfo"."ut_id" HAVING COUNT("app01_userinfo"."id") > 1filter放在前面的时候
obj = models.UserInfo.objects.filter(id__gt=2).values_list('ut__id').annotate(c=Count('id')).filter(c__gt=1) print(obj.query)sql
SELECT "app01_userinfo"."ut_id", COUNT("app01_userinfo"."id") AS "c" FROM "app01_userinfo" WHERE "app01_userinfo"."id" > 2 GROUP BY "app01_userinfo"."ut_id" HAVING COUNT("app01_userinfo"."id") > 1过滤
- __gt大于
- __lt小于
- in是范围,后面是列表
- range就是between and
- __startswith 以xxxx开头
- __conains 包含xxxx
- exclude(id=1) 处id=1的之外
models.UserInfo.objects.filter(id__gt=1)
models.UserInfo.objects.filter(id__lt=1) models.UserInfo.objects.filter(id__lte=1) models.UserInfo.objects.filter(id__gte=1) models.UserInfo.objects.filter(id__in=[1,2,3]) models.UserInfo.objects.filter(id__range=[1,2]) models.UserInfo.objects.filter(name__startswith='xxxx') models.UserInfo.objects.filter(name__contains='xxxx') models.UserInfo.objects.exclude(id=1)高级操作
F
- F是在原来的基础上进行的操作,下面是对所有用户的age+1
- 在sql中是 age = age + 1
from django.db.models.expressions import F
models.UserInfo.objects.all().update(age=F('age')+1)Q
Q的应用1
- 在这里Q的作用是filter中的条件
- 解决了或的问题
obj = models.UserInfo.objects.filter(Q(id=1)) obj = models.UserInfo.objects.filter(Q(id=1)|Q(id=2)) obj = models.UserInfo.objects.filter(Q(id=1)&Q(id=2))Q的应用2
- 应用于AutoCMDB中的资产管理的组合搜索
- 多个条件可以写成字典类型,然后filter(**字典) 进行接收
q1 = Q() # 建立一个Q对象
q1.connector = 'OR' # q1内部是OR的关系 q1.children.append(('id', 1)) q1.children.append(('id', 10)) q1.children.append(('id', 9)) q2 = Q() q2.connector = 'OR' q2.children.append(('c1', 1)) q2.children.append(('c1', 10)) q2.children.append(('c1', 9)) q3 = Q() q3.connector = 'AND' q3.children.append(('id', 1)) q3.children.append(('id', 2)) q1.add(q3,'OR') # 在q1中添加新的关系q3 con = Q() # 这是总的Q con.add(q1, 'AND') con.add(q2, 'AND') """ (id=1 or id = 10 or id=9 or (id=1 and id=2)) and (c1=1 or c1=10 or c1=9) """实际应用中的代码
- 对于同一种类别,q内部的都是or的关系
condition_dict = {
'k1':[1,2,3,4], 'k2':[1,], } con = Q() # 总的条件 for k,v in condition_dict.items(): q = Q() q.connector = 'OR' # q内部的都是or的关系 for i in v: q.children.append(('id', i)) con.add(q,'AND') # 总的条件用and models.UserInfo.objects.filter(con)extra
extra内部的有:
- select select_params
- where params
- tables
- order_by
models.UserInfo.objects.extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)extra是针对复杂的SQL语句
select select_params
v = models.UserInfo.objects.all().extra(select={
'n': "select count(1) from app01_userinfo WHERE id>%s" }, select_params=[1,] # 有多个% 内部就有多个参数 ) print(v) for item in v: print(item.id,item.name,item.n)# 这里使用nwhere params
models.UserInfo.objects.extra(
where=["id=1","name='aaa'"] ) models.UserInfo.objects.extra( where=["id=1 or id=%s ","name=%s"], params=[1,"aaa"] )tables
models.UserInfo.objects.extra(
tables=['app01_usertype'],
)
# """select * from app01_userinfo,app01_usertype"""总结:
# a. 映射
# select
# select_params=None # select 此处 from 表 # b. 条件 # where=None # params=None, # select * from 表 where 此处 # c. 表 # tables # select * from 表,此处 # c. 排序 # order_by=None # select * from 表 order by 此处models.UserInfo.objects.extra(
select={'newid':'select count(1) from app01_usertype where id>%s'}, select_params=[1,], where = ['age>%s'], params=[18,], order_by=['-age'], tables=['app01_usertype'] )最终的SQL:
select
app01_userinfo.id,
(select count(1) from app01_usertype where id>1) as newid from app01_userinfo,app01_usertype where app01_userinfo.age > 18 order by app01_userinfo.age desc原生SQL
Django内部提供了写原生SQL的方法
- 在setting中配置
- connection.cursor()默认是default数据库
- cursor = connections['db2'].cursor() 可以定义自己的数据库
from django.db import connection, connections
cursor = connection.cursor() #默认 connection=default数据库 cursor = connections['db2'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1])# 写原生SQL row = cursor.fetchone() row = cursor.fetchall() 其他
时间相关,时间格式化
def dates(self, field_name, kind, order='ASC'): # 根据时间进行某一部分进行去重查找并截取指定内容 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) # order只能是:"ASC" "DESC" # 并获取转换后的时间 - year : 年-01-01 # 截取到年,后面默认是01-01 - month: 年-月-01 # 截取到月,后面默认是01 - day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') # ctime是时间列 day,代表截取到day DESC对截取后的时间进行排序 def datetimes(self, field_name, kind, order='ASC', tzinfo=None): # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 # kind只能是 "year", "month", "day", "hour", "minute", "second" # order只能是:"ASC" "DESC" # tzinfo时区对象 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC) models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """ pip3 install pytz import pytz pytz.all_timezones pytz.timezone(‘Asia/Shanghai’) """- 更新数据后,create有返回值,是添加的数据的id
- 使用**字典进行接收
obj = models.UserType.objects.create(title='xxx')
obj = models.UserType.objects.create(**{'title': 'xxx'}) print(obj.id) # 返回值v = models.UserInfo.objects.all().first() # 推荐使用first
models.UserInfo.objects.get(id=1) # get没有获取到会报错- 批量操作
- odels.Userinfo(name='r11'), # 注意这是对象 没有用objects
bulk_create(self, objs, batch_size=None):
# 批量插入 # batch_size表示一次插入的个数 objs = [ models.Userinfo(name='r11'), # 注意这是对象 没有用objects models.Userinfo(name='r22') ] models.Userinfo.objects.bulk_create(objs, 10) # 一次性提交的数据10个,100条数据会没10条提交def get_or_create(self, defaults=None, **kwargs): # 如果存在,则获取,否则,创建 # defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs): # 如果存在,则更新,否则,创建 # defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1})性能相关
下面的这种情况每次for循环都会到数据库查询,性能低。使用values,values_list是一次查询,但是查询的不是对象,是字典列表类型
user_list = models.UserInfo.objects.all()
for item in user_list: print(item.age,item.name,item.ut.title)select_related 查询主动做连表
- 使用select_related('ut') 里面是外键,可以加多个
- 在查询的时候进行连表
user_list = models.UserInfo.objects.all().select_related('ut')
for item in user_list: print(item.age,item.name,item.ut.title)prefetch_related 不做连表 做多次查询
- 实际上连表对性能有影响,连表是约束和节省内存
-
这里做了两次查询,先查UserInfo,之后查UserType,这种查询非常快
user_list = models.UserInfo.objects.all().prefetch_related('ut') for item in user_list: print(item.age,item.name,item.ut.title)