前言:
最近玩爬虫的时候,遇到一个国外的图片网站,具体哪个就不说了,这个站很有意思,即使拿到了图片的链接,用httpclient下载都不行,不是User-Agent的原因,不知道图片服务器的后端有什么校验,没办法了,只能用Selenium上了,js逆向成本太高了(其实是我不擅长0.0)
这个站用的:

下面进入正题:
既然拿到图片url也不能用httpclient下载了,那我直接下载整个网页怎么样?下载整个网页,图片不就也保存下来了吗?
想到这个办法后我立马动手了起来,保存网页可以鼠标右键另存为,也可以键盘Ctrl+S
当然是键盘Ctrl+S 更简单啦
一、怎么在Selenium里面调用键盘事件Ctrl+S呢?
我试过new 一个Action,调用sendKeys方法,不管用;然后考虑用awt包下的Robot类;
听名字也知道是一个机器人类,里面有很多模拟键盘和鼠标操作的API
二、Ctrl+S之后文件名怎么修改?怎么点击保存?
这就要用到有个AutoIt的工具,这工具可以模拟windows环境下的键鼠操作,但是比Robot类更灵活,Robot类的鼠标移动只能通过像素点来确定移动位置,而AutoIt可以根据预先写好的脚步,自动定位到Windows窗口的按钮、输入框等等
下载地址:https://www.autoitscript.com/site/autoit/downloads/
安装完成之后先打开AutoIt Windows Info

打开之后:

打开一个网页的另存为的窗口,点击拖动Finder Tool

点击右边control面板可以看到,窗口的一些信息,id,class这些等会都要用到;
同理,点击拖动Finder Tool到保存按钮那里,也能看到对应按钮的信息
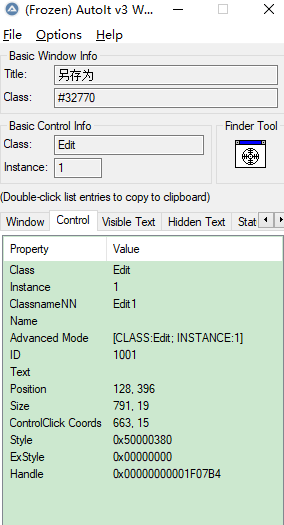
然后打开第二个工具上面截图中的 SciTE Script Editor来编辑脚本:
这个工具很强,有很多用法,想具体学习可以参考:https://www.jb51.net/shouce/autoit/?tdsourcetag=s_pctim_aiomsg
下面是我用的脚本:
;该脚本的语法是: ;分号代表注释
;ControlFocus ( "title", "窗口文本", controlID) 设置输入焦点到指定窗口的某个控件上
;WinWait ( "title题" , "窗口文本" , 超时时间 ) 暂停脚本的执行直至指定窗口存在(出现)为止
;ControlSetText ( "title", "窗口文本", controlID, "新文本" ) 修改指定控件的文本
;Sleep ( 延迟 ) 使脚本暂停指定时间段
;ControlClick ( "title", "窗口文本", 控件ID , 按钮 , 点击次数 ) 向指定控件发送鼠标点击命令
;其中,title即AutoIt Window Info识别出的Title字段,controlID即AutoIt Window Info识别
;出的Class和Instance的拼接,如上图拼接后的结果应为:Button1
ControlFocus("另存为","","")
;暂停脚本的执行直至指定窗口存在(出现)为止
WinWait("[CLASS:#32770]","",10)
;第二步:填充文件名地址,其中$CmdLine[1]代表exe执行时的动态参数,
;例如 Runtime.getRuntime().exec("D:\\saveAs.exe "+文件名),这样就可以动态改变文件名
ControlSetText("另存为","","Edit1",$CmdLine[1])
;延时函数
;Sleep(2000)
;第三步:点击保存按钮,进行下载,title:另存为,"text"写成空,controlId:写成Button2
;Button2是刚刚拖动Finder Tool获取到的“保存”按钮的id,可能每个人不一样
ControlClick("另存为","","Button2")点击保存之后,放到D盘,然后鼠标右键点击compile script完成编译之后,会在D盘生成一个文件名一样的exe可执行文件,等会就要调用这个文件来执行脚本
三、下面就是java代码了
@Autowired
private WebDriverPool webDriverPool;
public void getPic() throws Exception {
// 这里用队列实现的一个WebDriverPool,也可以自己new一个,但是比较耗资源
ChromeDriver chromeDriver = webDriverPool.get();
ChromeDriver openDetailDriver = webDriverPool.get();
for (int i = 1; i < 200; i++) {
// 打开网址主页
chromeDriver.get("https://***.com/page/" + i);
Thread.sleep(1000);
List<WebElement> elements = chromeDriver.findElements(By.xpath("//article[@class='item-list']"));
for (WebElement element : elements) {
WebElement alabel = element.findElement(By.xpath(".//div[@class='post-thumbnail']/a"));
WebElement titleElement = element.findElement(By.xpath(".//h2[@class='post-box-title']/a"));
String pictureDetailPage = alabel.getAttribute("href");
String picTitle = titleElement.getText();
log.info("图片首页地址:{}", pictureDetailPage);
openHomePage(openDetailDriver, false, pictureDetailPage, picTitle);
}
}
webDriverPool.closeAll();
}
/**
* 打开每个图片的主页
*
* @param url 主页地址
* @throws Exception
*/
public void openHomePage(ChromeDriver chromeDriver, boolean recursive, String url, String picTitle) throws Exception {
chromeDriver.get(url);
Thread.sleep(5000);
Robot robot = new Robot();
while (true) {
try {
// 等待页面加载完成
WebDriverWait webDriverWait = new WebDriverWait(chromeDriver, 10);
webDriverWait.until(ExpectedConditions.presenceOfElementLocated(By.id("fukie2")));
log.info("加载完毕");
break;
} catch (Exception e) {
log.info("打开页面失败,刷新");
chromeDriver.navigate().refresh();
Thread.sleep(10000);
}
}
robot.keyPress(KeyEvent.VK_CONTROL);
robot.keyPress(KeyEvent.VK_S);
robot.keyRelease(KeyEvent.VK_S);
robot.keyRelease(KeyEvent.VK_CONTROL);
Thread.sleep(1000);
// 调用autoIt动态修改文件名,避免文件名重复
Runtime.getRuntime().exec("D:\\saveAs.exe " + picTitle + random.nextInt(10000));
Thread.sleep(1000);
Thread.sleep(10000);
if (!recursive) {
List<WebElement> pages = chromeDriver.findElements(By.xpath("//div[@id='fukie2']/div[2]/a"));
for (int i = 1; i <= pages.size(); i++) {
log.info("当前下载第{}页", i + 1);
openHomePage(chromeDriver, true, url + "" + (i + 1), picTitle);
}
log.info("下载完当前页,关闭");
}
}在SpringBoot项目中使用awt包下的类,需要在启动类加一行代码:
System.setProperty("java.awt.headless", "false");
运行代码,你会看到每一页都被下载下来了,下载下来的网页里面包含了html、css、js、jpg,最后只需要过滤提取图片就行了。这样开发效率高,但是也有问题,如果需要多线程同时打开多个chrome下载的话,Robot类的键盘操作是需要聚焦的,也就是说如果采用多线程爬取,就需要在多个chrome中切换窗口才能高性能的下载,如果有高人有更好的解决办法的话,请不吝赐教
以上是全文,如有不正确的地方,欢迎交流
