以下链接是个人关于detectron2(目标检测框架),所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
detectron2(目标检测框架)无死角玩转-00:目录
前言
通过前面的博客,我们知道怎么去训练coco数据,但是我们的目的,肯定是去训练自己的数据,在这之前,需要为大家讲解一些相关的配置config信息,相信大家把网络跑起来的时候,也就是执行如下指令:
python tools/train_net.py \
--num-gpus 2 \
--config-file configs/COCO-Detection/retinanet_R_50_FPN_3x.yaml SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025
前面,我提醒大家注意,类似SOLVER.IMS_PER_BATCH,SOLVER.BASE_LR这样的配置,需要写在指令的最后面,那么这些到底是什么,我们应该如何去配置,在训练的时候,我相信大家都能看到如下打印:
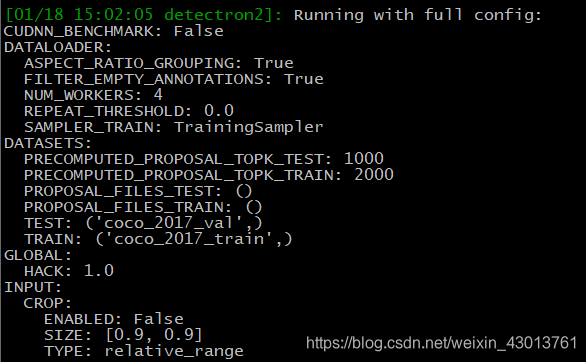
那么这些到底是怎么呢?下面,就是本人注释的结果!
配置注释
CUDNN_BENCHMARK: False #设置为True,其为自动找到效率最高的配置
DATALOADER: #dataloader的配置(数据迭代器)
ASPECT_RATIO_GROUPING: True # ?
FILTER_EMPTY_ANNOTATIONS: True # 是否过滤掉注释为空的数据
NUM_WORKERS: 4 # 加载数据的线程数目
REPEAT_THRESHOLD: 0.0 # 重新开始迭代是,从0加载数据
SAMPLER_TRAIN: TrainingSampler # 迭代训练样本
DATASETS: #数据集相关的配置
# 迭代数据时,提前准备1000/2000样本,为加快数据加载速度
PRECOMPUTED_PROPOSAL_TOPK_TEST: 1000
PRECOMPUTED_PROPOSAL_TOPK_TRAIN: 2000
# 数据集的文件名
PROPOSAL_FILES_TEST: ()
PROPOSAL_FILES_TRAIN: ()
# 获取数据时,其默认数据集名称
TEST: ('coco_2017_val',)
TRAIN: ('coco_2017_train',)
# ?
GLOBAL:
HACK: 1.0
INPUT: # 输入的相关的配置
CROP: # 图片剪切功能
ENABLED: False # 是否开启图片剪切
SIZE: [0.9, 0.9] # 剪切图像的大小比例
TYPE: relative_range # 剪切的方式
FORMAT: BGR # 图片的个饿死
MASK_FORMAT: polygon #mask掩码的格式,如果图片大小不足,会补黑色像素
MAX_SIZE_TEST: 1333 #测试图片的最大尺寸
MAX_SIZE_TRAIN: 1333 #训练图片的最大尺寸
MIN_SIZE_TEST: 800 # 测试图片最小尺寸
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800) # 训练图片的最小尺寸
MIN_SIZE_TRAIN_SAMPLING: choice #训练样本的抽样方式
MODEL:
ANCHOR_GENERATOR: # anchor生成的相关配置
ANGLES: [[-90, 0, 90]] # anchor的角度
ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # 长宽的比例
NAME: DefaultAnchorGenerator # anchor生成器的名字
OFFSET: 0.0 # 偏移量
SIZES: [[32], [64], [128], [256], [512]] # 大小,生成anchor每个尺寸的大小
BACKBONE: # 主干网络配置
FREEZE_AT: 2 #冻结?
NAME: build_resnet_fpn_backbone #主干网络的名字
DEVICE: cuda # 使用GPU
FPN: # FPN的相关配置
FUSE_TYPE: sum # 融合的类似
IN_FEATURES: ['res2', 'res3', 'res4', 'res5'] # 指定处为输入特征
NORM: # ?
OUT_CHANNELS: 256 # FPN的输出通道数
KEYPOINT_ON: False # 是否开启关键点
LOAD_PROPOSALS: False # ?
MASK_ON: True # ?
META_ARCHITECTURE: GeneralizedRCNN # 微元素的架构,可以是retina等等
PANOPTIC_FPN: # 全景分割的相关配置
COMBINE: #相关绑定
ENABLED: True # 是否启动
INSTANCES_CONFIDENCE_THRESH: 0.5 # 设置置信度的阈值
OVERLAP_THRESH: 0.5 # 重叠部分的
STUFF_AREA_LIMIT: 4096 #?
INSTANCE_LOSS_WEIGHT: 1.0 # 实例的权重比例
PIXEL_MEAN: [103.53, 116.28, 123.675] # ?
PIXEL_STD: [1.0, 1.0, 1.0] #?
PROPOSAL_GENERATOR: #?
MIN_SIZE: 0 #?
NAME: RPN #?
RESNETS: #重新配置
DEFORM_MODULATED: False #
DEFORM_NUM_GROUPS: 1
DEFORM_ON_PER_STAGE: [False, False, False, False]
DEPTH: 50 # resnet循环次数
NORM: FrozenBN # 冻结BN
NUM_GROUPS: 1 #输出特征的层数
OUT_FEATURES: ['res2', 'res3', 'res4', 'res5']
RES2_OUT_CHANNELS: 256 # 对应层输出的通道数
RES5_DILATION: 1 # ?
STEM_OUT_CHANNELS: 64
STRIDE_IN_1X1: True # ?
WIDTH_PER_GROUP: 64 # 可分离卷积的分组数目
RETINANET: # retinanet相关配置
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0) # ?
FOCAL_LOSS_ALPHA: 0.25 # FOCAL_LOSS相关参数
FOCAL_LOSS_GAMMA: 2.0 # FOCAL_LOSS相关参数
IN_FEATURES: ['p3', 'p4', 'p5', 'p6', 'p7'] # ?
IOU_LABELS: [0, -1, 1] # 输出标签
IOU_THRESHOLDS: [0.4, 0.5] # IOU的阈值
NMS_THRESH_TEST: 0.5 # NMS的阈值
NUM_CLASSES: 80 # 训练数据的总类别数目
NUM_CONVS: 4 # 卷积层数目
PRIOR_PROB: 0.01 #?
SCORE_THRESH_TEST: 0.05 # 测试数据的置信度阈值
SMOOTH_L1_LOSS_BETA: 0.1 # L1loss平滑参数
TOPK_CANDIDATES_TEST: 1000 # 提前拿取的测试数据
ROI_BOX_CASCADE_HEAD: #
BBOX_REG_WEIGHTS: ((10.0, 10.0, 5.0, 5.0), (20.0, 20.0, 10.0, 10.0), (30.0, 30.0, 15.0, 15.0))
IOUS: (0.5, 0.6, 0.7)
ROI_BOX_HEAD:
BBOX_REG_WEIGHTS: (10.0, 10.0, 5.0, 5.0)
CLS_AGNOSTIC_BBOX_REG: False
CONV_DIM: 256
FC_DIM: 1024
NAME: FastRCNNConvFCHead
NORM:
NUM_CONV: 0
NUM_FC: 2
POOLER_RESOLUTION: 7
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
SMOOTH_L1_BETA: 0.0
ROI_HEADS:
BATCH_SIZE_PER_IMAGE: 512
IN_FEATURES: ['p2', 'p3', 'p4', 'p5']
IOU_LABELS: [0, 1]
IOU_THRESHOLDS: [0.5]
NAME: StandardROIHeads
NMS_THRESH_TEST: 0.5
NUM_CLASSES: 80
POSITIVE_FRACTION: 0.25
PROPOSAL_APPEND_GT: True
SCORE_THRESH_TEST: 0.05
ROI_KEYPOINT_HEAD:
CONV_DIMS: (512, 512, 512, 512, 512, 512, 512, 512)
LOSS_WEIGHT: 1.0
MIN_KEYPOINTS_PER_IMAGE: 1
NAME: KRCNNConvDeconvUpsampleHead
NORMALIZE_LOSS_BY_VISIBLE_KEYPOINTS: True
NUM_KEYPOINTS: 17
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
ROI_MASK_HEAD:
CLS_AGNOSTIC_MASK: False
CONV_DIM: 256
NAME: MaskRCNNConvUpsampleHead
NORM:
NUM_CONV: 4
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 0
POOLER_TYPE: ROIAlignV2
RPN:
BATCH_SIZE_PER_IMAGE: 256
BBOX_REG_WEIGHTS: (1.0, 1.0, 1.0, 1.0)
BOUNDARY_THRESH: -1
HEAD_NAME: StandardRPNHead
IN_FEATURES: ['p2', 'p3', 'p4', 'p5', 'p6']
IOU_LABELS: [0, -1, 1]
IOU_THRESHOLDS: [0.3, 0.7]
LOSS_WEIGHT: 1.0
NMS_THRESH: 0.7
POSITIVE_FRACTION: 0.5
POST_NMS_TOPK_TEST: 1000
POST_NMS_TOPK_TRAIN: 1000
PRE_NMS_TOPK_TEST: 1000
PRE_NMS_TOPK_TRAIN: 2000
SMOOTH_L1_BETA: 0.0
SEM_SEG_HEAD:
COMMON_STRIDE: 4
CONVS_DIM: 128
IGNORE_VALUE: 255
IN_FEATURES: ['p2', 'p3', 'p4', 'p5']
LOSS_WEIGHT: 1.0
NAME: SemSegFPNHead
NORM: GN
NUM_CLASSES: 54 #类别的数目
WEIGHTS: detectron2://ImageNetPretrained/MSRA/R-50.pkl # 加载的权重
OUTPUT_DIR: ./output
SEED: -1
SOLVER: #解决方案
BASE_LR: 0.0025 # 初始学习率
BIAS_LR_FACTOR: 1.0 #?
CHECKPOINT_PERIOD: 5000 # 没 5000个epoch进行一次测试
GAMMA: 0.1
IMS_PER_BATCH: 2 # 每个GPU的batch_siez大小
LR_SCHEDULER_NAME: WarmupMultiStepLR # 学习率衰减方式
MAX_ITER: 90000 # 到达该迭代次数则停止
MOMENTUM: 0.9 # 优化器动能
STEPS: (60000, 80000) # 到达指定迭代步数,则学习率衰减
WARMUP_FACTOR: 0.001
WARMUP_ITERS: 1000
WARMUP_METHOD: linear
WEIGHT_DECAY: 0.0001 # 权重衰减
WEIGHT_DECAY_BIAS: 0.0001 # 权重衰减系数
WEIGHT_DECAY_NORM: 0.0
TEST: # 测试相关配置
AUG: # AUG相关配置
ENABLED: False
FLIP: True # 水平翻转
MAX_SIZE: 4000 # 图片的最大尺寸
MIN_SIZES: (400, 500, 600, 700, 800, 900, 1000, 1100, 1200) # 图片的最小尺寸
DETECTIONS_PER_IMAGE: 100 # 每张图片检测到的最大目标数目
EVAL_PERIOD: 0 # 迭代多少次后进行训练
EXPECTED_RESULTS: [] # 期待的结果
KEYPOINT_OKS_SIGMAS: [] #?
PRECISE_BN: # 测试精确度,BN的配置
ENABLED: False # 时候启动BN
NUM_ITER: 200 # 迭代数目
VERSION: 2
VIS_PERIOD: 0
上面的配置注释,由于现在本人不是很熟悉fast-rcnn,所以不知道ROI的相关配置,就没有注释了,有知道的朋友写文档给我,然后我更新上去,一定会带上小哥的名字。
其实,在训练的时候,我们大多数的参数保持默认即可,只需要修改部分参数,具体怎么设置,请看下篇博客,下篇博客,我会带大家去训练自己的数据。
