实现黑白图片自动变成彩色图片
如果你有一幅黑白图片,你该如何上色让他变成彩色的呢?通常做法可能是使用PS工具来进行上色。那么,有没有什么办法进行自动上色呢?自动将黑白图片变成彩色图片?答案是有的,使用深度学习中的Pix2Pix网络就可以实现这一功能。
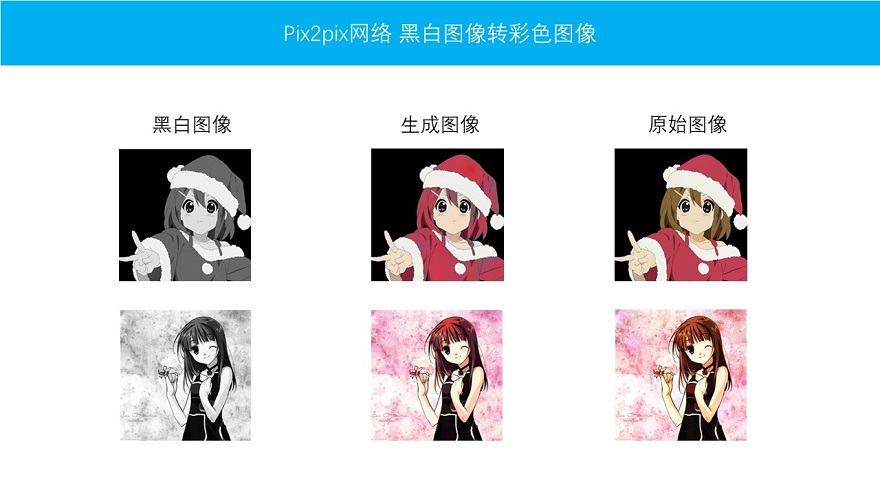
如图所示,我们可以将黑白动漫图片,通过网络学习,自动变成彩色。对这个Pix2Pix网络是如何实现的,想要进一步了解网络和代码的话,可以点击这个
课程链接
下面,对这个网络进行一点简要介绍。
Pix2Pix网络介绍
pix2pix算是cGAN的一种,但是和cGAN又略有不同,而且,在pix2pix这篇论文中,首次提出了PatchGAN的概念,初次接触到的人可能会略有疑惑。这篇文章,我们就一起来探讨一下,pix2pix中的判别器是如何设计的。
cGAN
提到pix2pix就一定要提一下,他的思想源泉,cGAN。最初我们所熟知的GAN的概念,当属造假钞和验假钞的对抗过程(诞生了DCGAN),造假钞造出来的假钞越来越像真钞,验假钞的越来越能够识别假钞。我们从这个具体故事里面抽象出来,其实就是说,生成器生成的图片够真,就可以骗过判别器。至于这个生成器生成的图片真的是我们想要的?就不一定了。
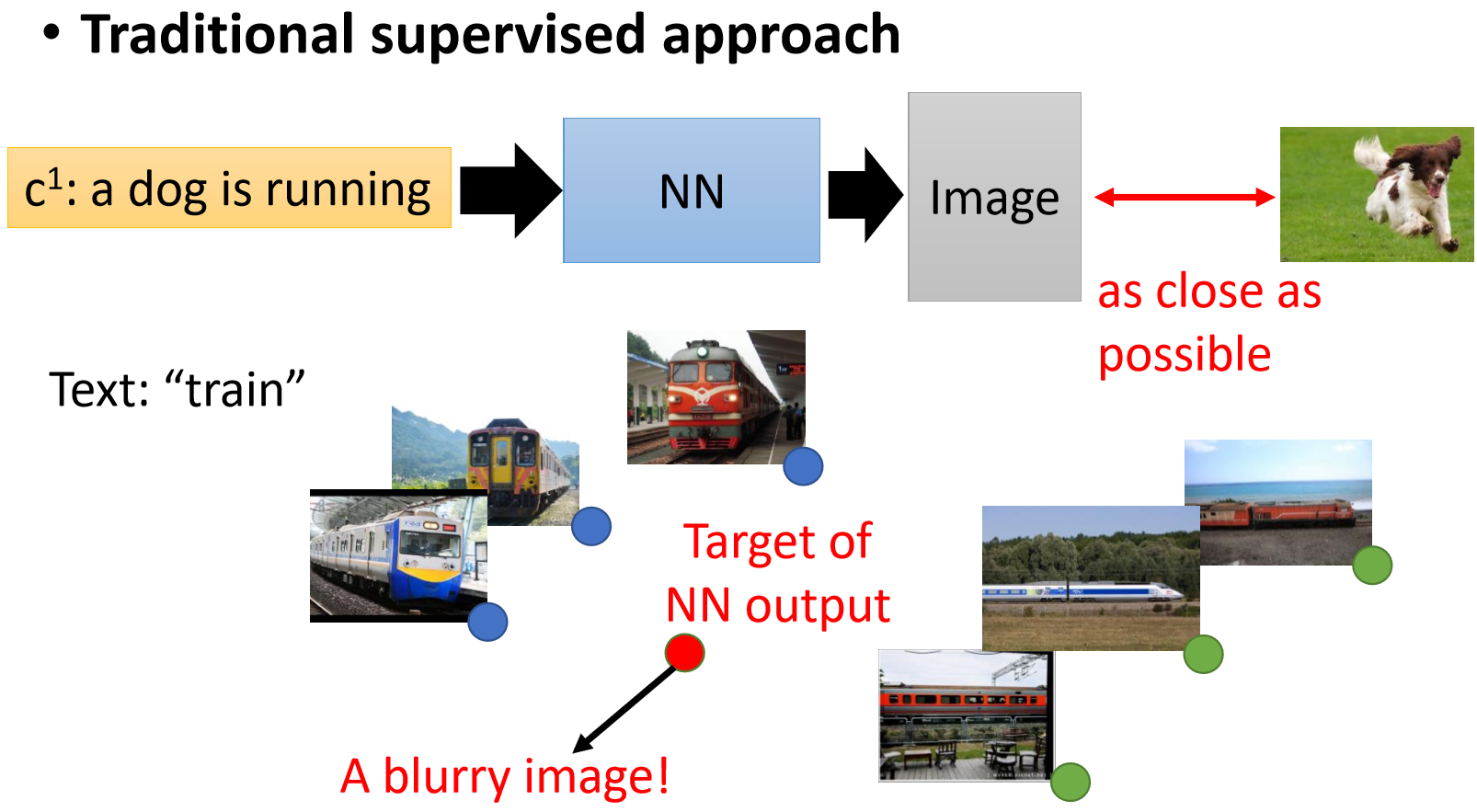
另外还有一个问题,比如上面这幅图。如果我有一堆火车图片。有正面的也有侧面的,我们都知道这是火车。但是生成对抗网络其实并不理解。如果用最基本的GAN(比如DCGAN)来做的话,很有可能最后就会得到一个normal的图片,就是正面和侧面火车平均之后的一个图片。就会导致训练之后的图片结果很模糊。
cGAN就是来解决这个问题的。c表示conditional,是控制。我想让生成器生成小狗的图片,他就不能生成火车的图片。此时我们的D和G不再是单独的一个输入,而是两种输入。
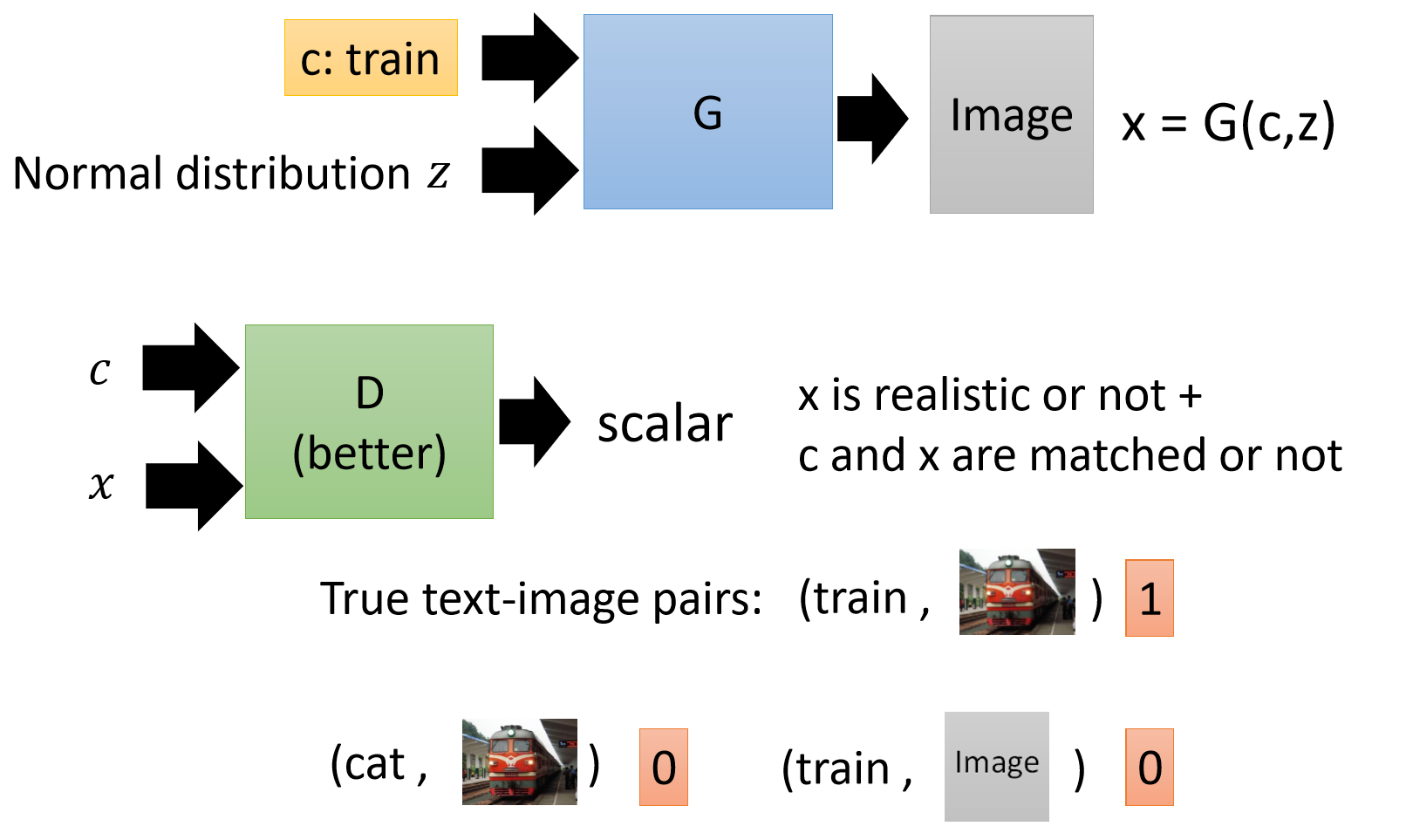
在生成器部分,我们不仅输入normal distribution,还输入一个条件c(比如cat或者train)。我们在判别器部分,也输入两个,一个是条件c,另外一个是x(生成的数据或者真实的数据)。这里判别器的目的不仅仅要看生成的x数据是否和真实数据分布接近。还要看和条件c是否一致。对于判别器而言,生成的图片不好,还有生成的图片和c不匹配,都要给它低分。
pix2pix的判别器
在pix2pix中我们的判别器构造和cGAN思想基本一致,但稍有不同。
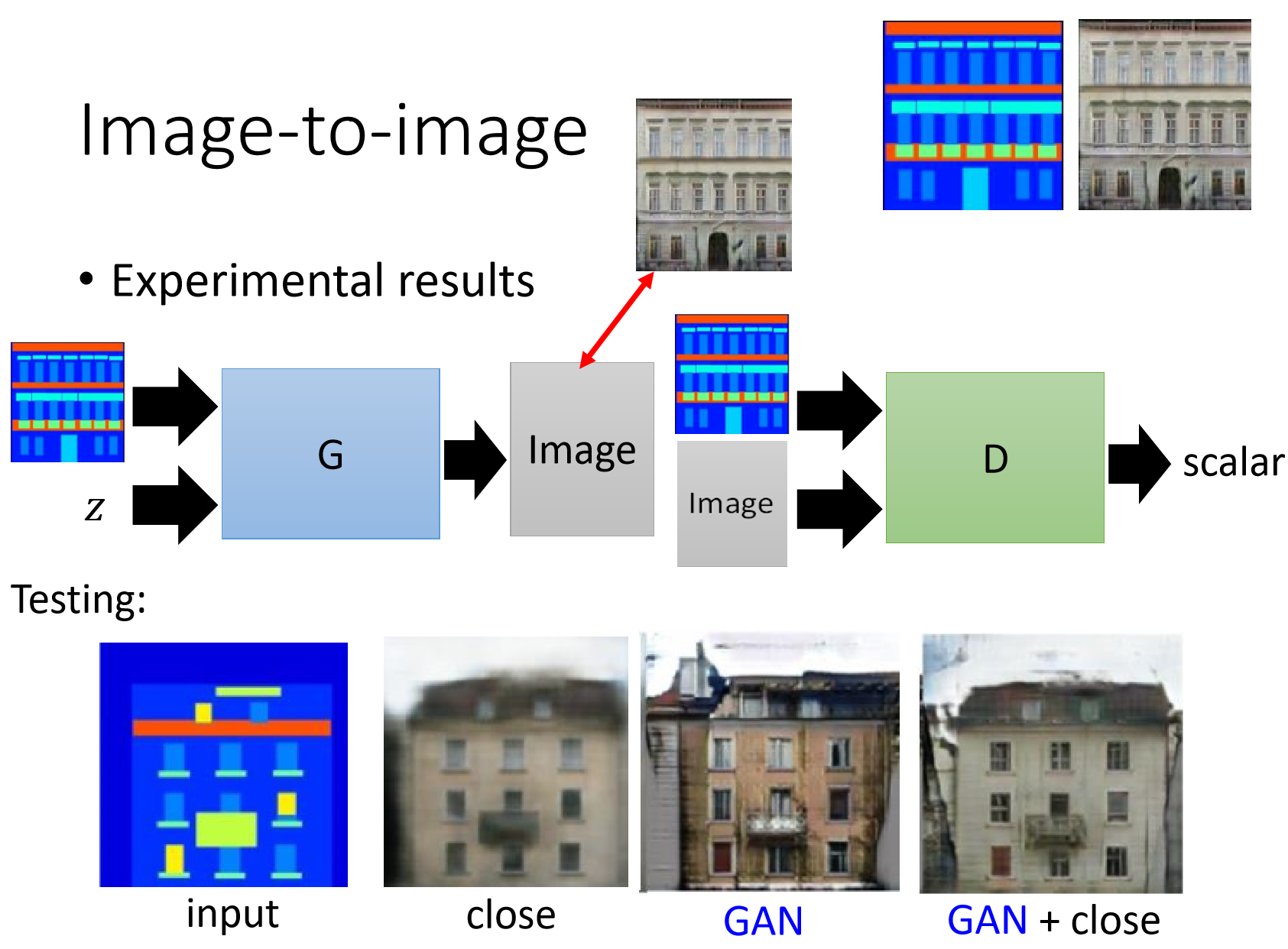
这里,我们的判别器输入两张图像,一张是G的input图像,一张是G的output图像。也就是说,对于判别器而言,不只是输出高质量的图像就可以骗过判别器,必须要两张图像有对应关系才可以。
pix2pix的判别器训练代码
下面,我们从代码详细的看一下,pix2pix是如何对判别器进行计算的。
real_a, real_b = batch[0].to(device), batch[1].to(device)
fake_b = net_g(real_a)
optimizer_d.zero_grad()
# 判别器对虚假数据进行训练
fake_ab = torch.cat((real_a, fake_b), 1)
pred_fake = net_d.forward(fake_ab.detach())
loss_d_fake = criterionGAN(pred_fake, False)
# 判别器对真实数据进行训练
real_ab = torch.cat((real_a, real_b), 1)
pred_real = net_d.forward(real_ab)
loss_d_real = criterionGAN(pred_real, True)
# 判别器损失
loss_d = (loss_d_fake + loss_d_real) * 0.5
loss_d.backward()
optimizer_d.step()
从代码中我们可以看到,对判别器而言,输入数据需要通过cat来连接之后一起输入。real_a和fake_b的结合数据为假。real_a和real_b结合的数据为真。关于代码中为什么D有detach而G没有detach可以看我写的[2]。
我们来比较一下DCGAN是怎么做的,下面是DCGAN的代码:
# 训练判别器
optimizer_d.zero_grad()
## 尽可能把真图片判别为正
output = netd(real_img)
error_d_real = criterion(output, true_labels)
error_d_real.backward()
## 尽可能把假图片判断为错误
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
# 使用detach来关闭G求梯度,加速训练
fake_img = netg(noises).detach()
output = netd(fake_img)
error_d_fake = criterion(output, fake_labels)
error_d_fake.backward()
optimizer_d.step()
error_d = error_d_fake + error_d_real
errord_meter.add(error_d.item())
DCGAN和cGAN不太一样的地方就是输入数据不需要concatenate,也就是没有条件c的意思。pix2pix中判别器有两个输入是要求,两个图片必须匹配才算是正确的。
如果对optimzer,loss等流程不太清楚,可以看参考[3]
PatchGAN
pix2pix判别器另外一个设计点,就在PatchGAN了。我们先来看一下PatchGAN的网络结构。

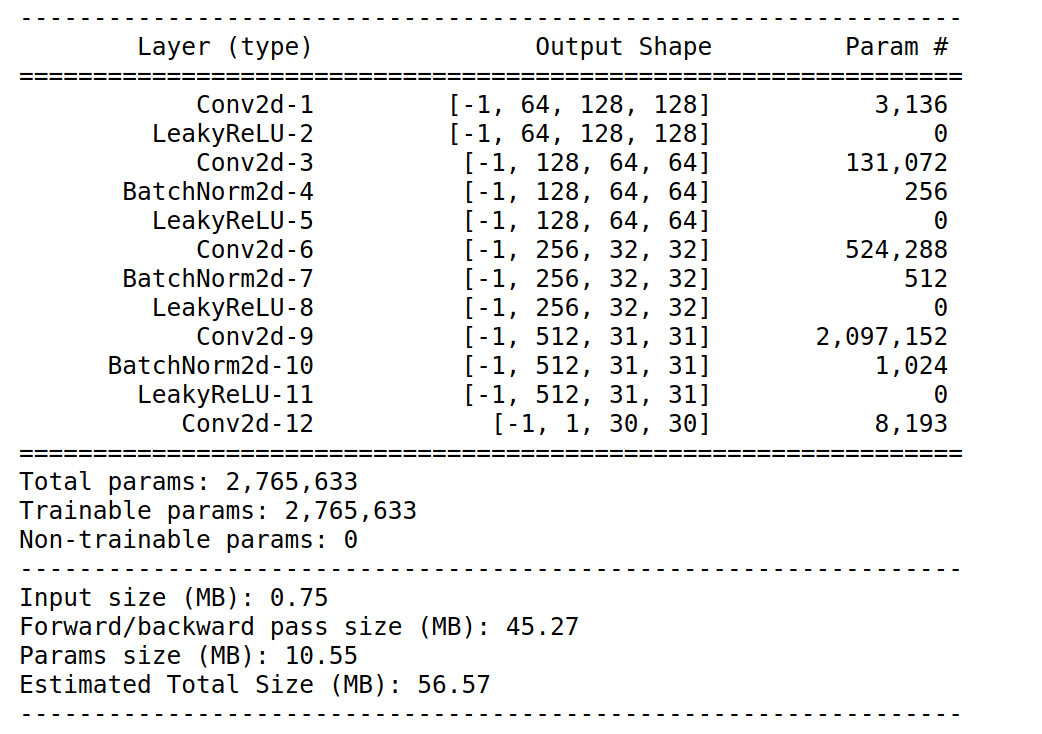
下面是对应代码部分:
class NLayerDiscriminator(nn.Module):
"""
定义PatchGAN判别器
"""
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d, use_sigmoid=False):
"""
构建PatchGAN判别器
参数:
input_nc --输入图片通道数
ndf --最后一个卷积层过滤器的数量
n_layers --判别器卷积层的数量
norm_layer --标准化层
use_sigmoid --是否使用sigmoid函数
"""
super(NLayerDiscriminator, self).__init__()
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
kw = 4 # kernel size
padw = 1 # padding
sequence = [
nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw),
nn.LeakyReLU(0.2, True)
]
nf_mult = 1
nf_mult_prev = 1
# 逐渐增加过滤器的数量
for n in range(1, n_layers):
nf_mult_prev = nf_mult
nf_mult = min(2**n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult,
kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = min(2**n_layers, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult,
kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)]
if use_sigmoid:
sequence += [nn.Sigmoid()]
self.model = nn.Sequential(*sequence)
def forward(self, input):
return self.model(input)
从网络结构中可以看到,并且结合之前torch.cat我们可以看到,输入的shape是6*256*256,然后输出的shape是1*30*30。
论文中称PatchGAN是一种马尔科夫判别器。关于PatchGAN的理解可以看[6],之前我们说了PatchGAN输出的是一个1*30*30的矩阵。这和我们普通的GAN里面输出一个预测值完全不同。一个矩阵怎么做预测呢?我们的做法是把预测值也扩展成一个1*30*30的矩阵。之后对二者使用最小二乘损失。这相当于对1*30*30的矩阵的每一个点都对应一个label。
通过对图像进行卷积操作,后面的输出矩阵,对前面部分有了更大的感受野(如果不明白感受野,可以看一下这里)。那么,最后输出的30*30的每一个点,相当于最初输入图像的一个Patch,所以命名为PatchGAN。根据论文中描述的,这个Patch大小为70。
这个70是如何计算出来的呢?
感受野计算公式我参考的是[7],下面的表格是PatchGAN网络感受野的计算,可以看到30*30的矩阵,每一个pixel对应的感受野的确是70*70。

| Layer | Input Size | Kernel Size | Stride | Output Size | Receptive Field |
|---|---|---|---|---|---|
| Conv1 | 256*256 | 4*4 | 2 | 128*128 | 4 |
| Conv2 | 128*128 | 4*4 | 2 | 64*64 | 10 |
| Conv3 | 64*64 | 4*4 | 2 | 32*32 | 22 |
| Conv4 | 32*32 | 4*4 | 1 | 31*31 | 46 |
| Conv5 | 31*31 | 4*4 | 1 | 30*30 | 70 |
另外,可以点击这个网站:Fomoro AI,可以自动帮你分析计算感受野。
这样,使用PatchGAN处理之后,pix2pix就将图像切割成30*30份,每一份对应一个70*70的patch,我们想要每个patch的结果都为真。通过聚焦于一个patch的局部位置,可以更好地提高整体识别和判断效果。
参考
[1]李宏毅生成对抗网络2018
[2]训练生成对抗网络的过程中,训练gan的地方为什么这里没有detach,怎么保证训练生成器的时候不会改变判别器
[3Pytorch中的optimizer.zero_grad和loss和net.backward和optimizer.step的理解
[4]pix2pix主要代码学习
[5][GAN笔记] pix2pix
[6]关于PatchGAN的理解
[7]关于感受野的理解与计算
