Pix2Pix——基于GAN的图像风格迁移模型
写在前面
本文是文献Image-to-image translation with conditional adversarial networks的笔记。Pix2Pix 基于 GAN 架构,利用成对的图片进行图像翻译,即输入为同一张图片的两种不同风格,可用于进行风格迁移。
本文目录
引言部分
计算机视觉方面有许多问题涉及到了将输入图像转换成相应的输出图像。即使为解决某种特定问题有针对性的设计的算法,归根结底都是像素到像素的映射(Pixel to Pixel)。
由此,文章认为条件对抗网络(GAN, Generative Adversarial Networks )是对该类问题的一种通用解决方案。
为什么要基于GAN
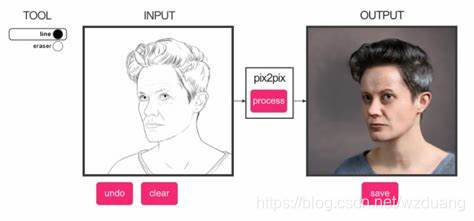
如今,卷积神经网络(CNN)成为了各种图像预测问题背后的常用方法。 但是要使得一个 CNN 学会最小化损失函数,仍然需要大量的人工甚至专家知识进行损失函数的设计。如果只是随意地采取一个简单的损失函数,例如欧氏距离。仅仅最小化预测像素与地面真实像素之间的欧氏距离,而欧式距离平均了所有可能输出,所得到的结果将会是模糊的。
因此,如果我们可以只指定一个高级目标,例如“无法区分输出与现实(make the output indistinguishable from reality)”,然后自动学习适合于实现该目标的损失函数,就可以得到一个解决该类问题的通用框架,而GAN正好可以做到。
对于为何选择 GAN ,文章的原话是这样的:
GANs learn a loss that tries to classify if the output image is real or fake, while simultaneously training a generative model to minimize this loss. Blurry images will not be tolerated since they look obviously fake. Because GANs learn a loss that adapts to the data, they can be applied to a multitude of tasks that traditionally would require very different kinds of loss functions.
Pix2Pix 的结构
一个 GAN 结构的网络至少由两部分构成:生成器模型(Generative Model)与判别器模型(Discriminative Model)。GAN 通过两个模块的互相博弈学习产生相当好的输出。一个优秀的 GAN 需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
Pix2Pix 的生成器模型
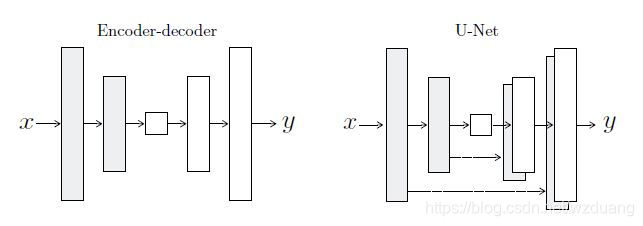
Pix2Pix 的生成器模型基于 U-Net 结构。U-Net 的结构示意图如下:
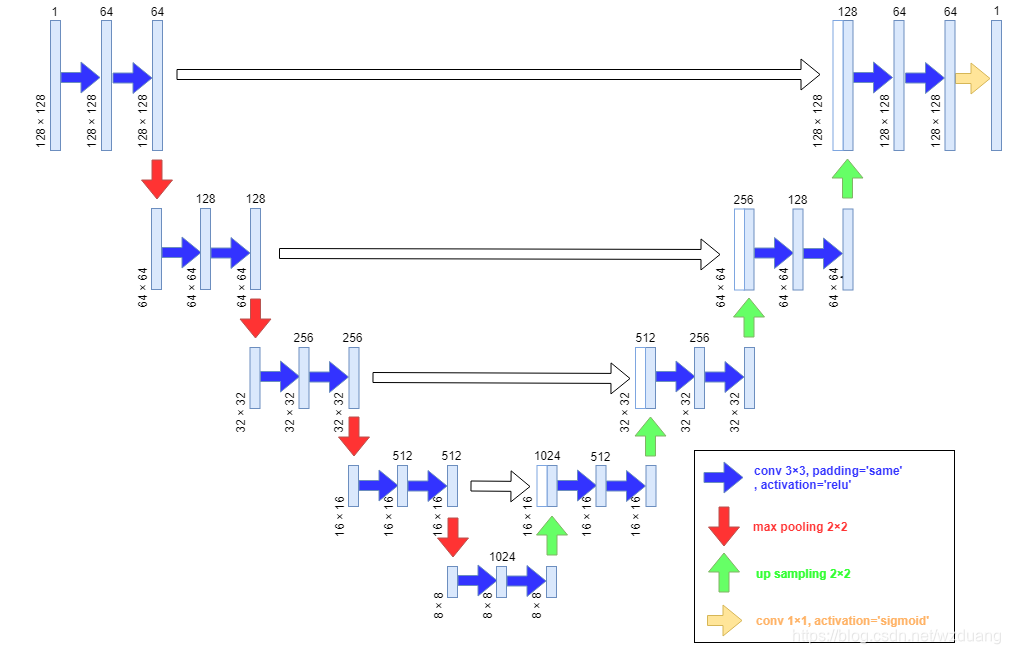
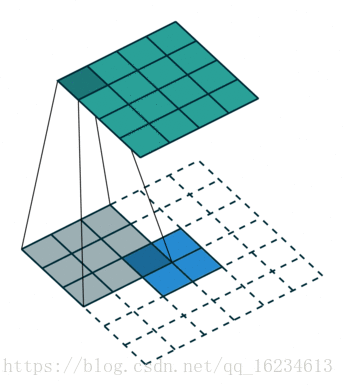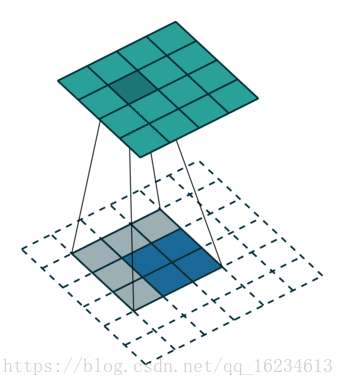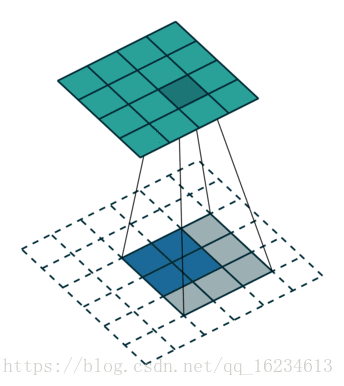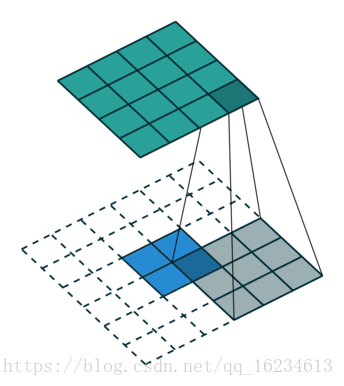
U-Net 是一个全卷积网络,在计算机视觉的语义分割领域同样有着广泛的应用。位于最底层的特征图(feature map)通过逆卷积的形式生成图像。
上图解释了 U-Net 结构如何通过逆卷积生成与输入相同维度的图像。有许多人将 U-Net 的这个架构称为反卷积,但卷积与反卷积是相对于一个卷积核在前向传播与反向传播的两种操作,这两种操作是互相对应的。所以本人认为将其称为逆卷积更为合理。同时,U-Net 除了编码-解码(Encoder-decoder)结构外,还具有跳过连接(skip connections)的结构。
Pix2Pix 的判别器模型
GAN 的判别器采用了 PatchGAN 的判别器结构。PactchGAN 与一般的 GAN 有什么不同之处呢?
一般 GAN 的判别器只需要输出一个 true or fasle 的矢量,代表对整张图像的评价。但是 PatchGAN 输出的是一个 N x N 的矩阵,这个 N x N 的矩阵里的每一个元素,比如 a(i,j) 只有 True or False 这两个选择即判别器输出的 label 是 N x N 的矩阵,矩阵中的每一个元素是 True 或者 False。
这样的结果往往是通过卷积层来达到的,因为逐次叠加的卷积层最终输出的这个N x N 的矩阵,其中的每一个元素,实际上代表着原图中的一个比较大的感受野,即对应原图的一个 Patch ,因此具有这样结构以及这样输出的 GAN 被称之为 PatchGAN。下面是 Pix2Pix 论文原作者对该问题的回答:
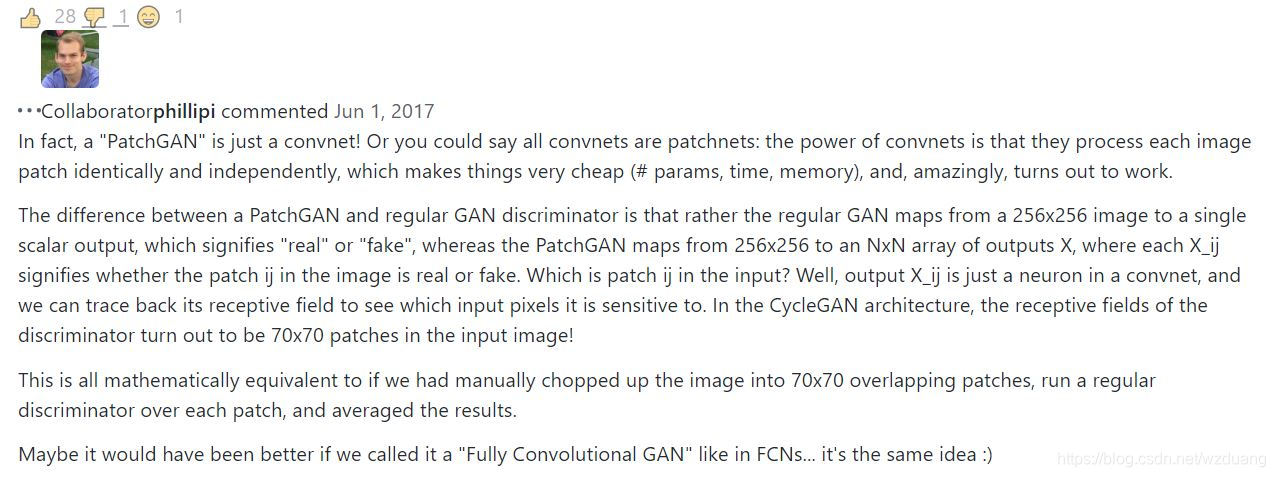
问题链接:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/39
Pix2Pix 目的函数设计
Pix2Pix 的目的可以表示为
L c G A N ( G , D ) = E x , y [ l o g D ( x , y ) ] + E x , z [ l o g ( 1 − D ( x , G ( x , z ) ) ) ] \mathcal{L}_{cGAN}(G,D ) = \mathbb{E}_{x,y} [log D(x,y)]+ \\\mathbb{E}_{x,z}[log(1-D(x,G(x,z)))] LcGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
其中 G 会尝试将目的最大化,而 D 会尝试将目的最小化。可以用下面的公式表示
G ∗ = a r g m i n G m a x D L c G A N ( G , D ) G^{*} =arg min_{G} max_{D} L_{cGAN}(G, D) G∗=argminGmaxDLcGAN(G,D)
为了探索目的函数中各参数的重要性,作者还对这个函数进行了一些探索。例如团队还提出了去掉原图像 x 的函数:
L c G A N ( G , D ) = E y [ l o g D ( y ) ] + E x , z [ l o g ( 1 − D ( G ( x , z ) ) ) ] \mathcal{L}_{cGAN}(G,D ) = \mathbb{E}_{y} [log D(y)]+ \\\mathbb{E}_{x,z}[log(1-D(G(x,z)))] LcGAN(G,D)=Ey[logD(y)]+Ex,z[log(1−D(G(x,z)))]
通过比较该函数与原函数的区别,发现将生成图像与原图像融合是有益的。同时为了更好地使得输出图像接近真实图像,作者使用了 L1 距离而不是 L2 距离,因为 L1 距离鼓励减少模糊。修正后公式如下
L L 1 ( G ) = E x , y , z [ ∣ ∣ y − G ( x , z ) ∣ ∣ 1 ] \mathcal{L}_{L1}(G ) = \mathbb{E}_{x,y,z} [||y-G(x,z)||_{1}] LL1(G)=Ex,y,z[∣∣y−G(x,z)∣∣1]
最终得到的损失函数为
G ∗ = a r g m i n G m a x D L c G A N ( G , D ) + λ L L 1 ( G ) G^{*} =arg min_{G} max_{D} L_{cGAN}(G, D)+\lambda\mathcal{L}_{L1}(G ) G∗=argminGmaxDLcGAN(G,D)+λLL1(G)
Pix2Pix 模型的优化与推理
模型优化
在这部分的内容中,作者的训练始终遵循在判别器 D D D 的一个梯度下降 step 与生成器 G G G 的一个 step 之间交替。同时作者在优化判别器 D D D 的时减慢了 D D D 相对于 G G G 的学习速度。
优化器方面,作者使用了 minibatch SGD 并使用了 Adam solver。初始学习率(learning rate)为 0.0002,动量参数设置 β 1 = 0.5 \beta_{1} = 0.5 β1=0.5, β 2 = 0.999 \beta_{2} = 0.999 β2=0.999
模型推理
在模型推理的过程中,相对于训练作者添加了 drop out 与 batch normalization 。并通过实验证明这些这些添加项对图像生成任务有效。
除此之外,作者还做了大量的实验验证不同结构与参数对模型训练效果的影响。在这里就不展开讨论了。
Pix2Pix 模型效果
Pix2Pix 作为风格迁移器,可以完成不同风格的图像转换。
例如将一张素描图变成猫的形状:
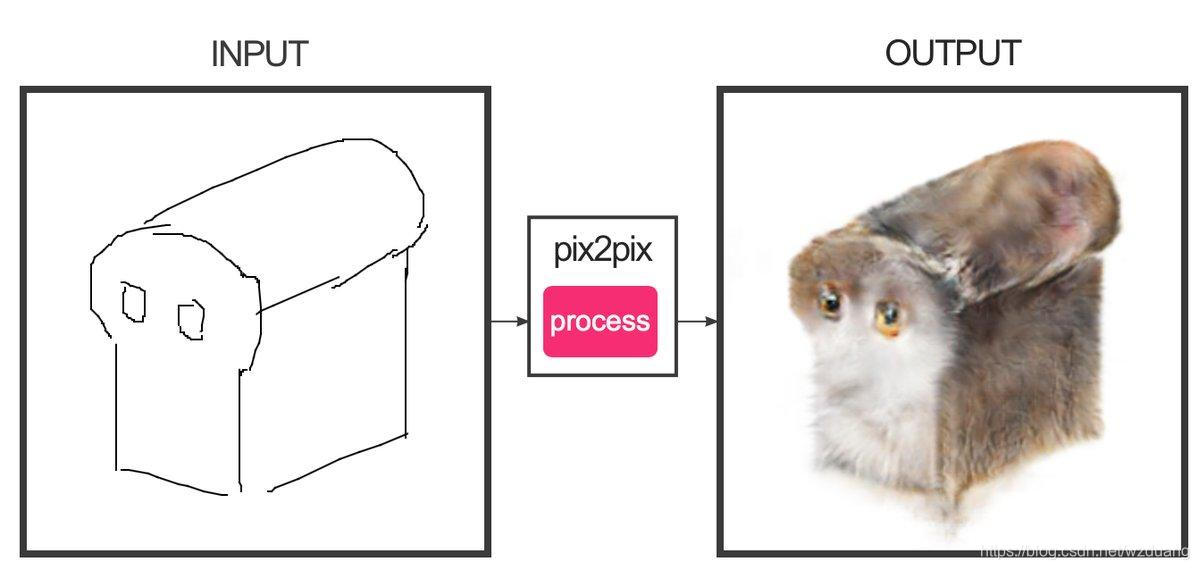
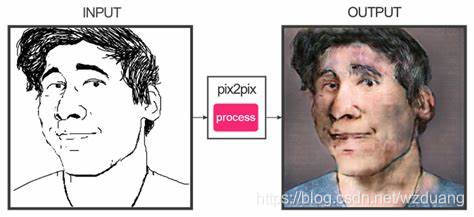
或者由黑白素描生成彩色油画:
也可以完成从卫星遥感图到二维地图的转换:

甚至可以由语义分割图生成逼真的图像:

在图像生成、图像编辑、图像超分辨率、图像风格迁移、文本到图像的翻译等任务中都能得到广泛的应用。
总结
本文基于 Image-to-image translation with conditional adversarial networks 一文谈了谈自己的理解,同时展示了 Pix2Pix 模型的一些实际应用。
本人以后会发布一些关于机器学习模型算法,自动控制算法的其他文章,也会聊一聊自己做的一些小项目,希望读者朋友们能够喜欢。