用 pyecharts 对爬虫后的数据进行可视化处理(生成饼图、柱状图、地理位置图、3D旋转动图、词云图)及地图问题的解决
首先,pyecharts 是一款融合了Python和echarts技术的强大的数据可视化工具,它的可视化类型比较多也很丰富,具体的可以参考pyecharts 中文网站:https://pyecharts.org/#/zh-cn/intro
pyecharts 的安装方法
可以参考 Selenium 的两种安装方法选一种就可以,有图和安装步骤
综合案例
1、爬取猫眼中的《一出好戏》的数据
__author__ = 'xiaoguo'
from urllib import request
import ssl, json
from datetime import datetime, timedelta
import time
# 获取数据
def get_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
req = request.Request(url, headers=headers)
response = request.urlopen(req, context=ssl._create_unverified_context())
if response.getcode() == 200:
result = response.read()
return result
# 处理数据
def parse_data(html):
data = json.loads(html)['cmts']
contents = []
for item in data:
content ={
'id': item['id'],
'nickName': item['nickName'],
'cityName': item['cityName'] if 'cityName' in item else ' ', # 处理cityName不存在的情况
'content': item['content'].replace('\n', ' '), # 处理评论内容中有 \n 的情况
'score': item['score'],
'startTime': item['startTime']
}
contents.append(content)
return contents
# 存储数据到文本文件中
def save_to_txt():
# 当前时间
start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# 结束时间
end_time = '2018-08-08 00:00:00'
while start_time > end_time:
url = 'http://m.maoyan.com/mmdb/comments/movie/1203084.json?_v_=yes&offset=0&startTime=' + start_time.replace(' ', '%20')
try:
html = get_data(url)
except:
time.sleep(0.5)
html = get_data(url)
else:
time.sleep(0.2)
contents = parse_data(html)
print(contents)
start_time = contents[len(contents)-1]['startTime'] # 获取每次加载后的最后一个评论时间
# 将取出的字符串时间转换为时间格式
start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S')-timedelta(seconds=1)
start_time = datetime.strftime(start_time, '%Y-%m-%d %H:%M:%S')
for item in contents:
with open('maoyanContent.txt', mode='a', encoding='utf-8') as f:
f.write(str(item['id']) + ',' + item['nickName'] + ',' + item['cityName'] + ',' + item['content'] + ',' + str(item['score']) + ',' + item['startTime'] + '\n')
if __name__ == '__main__':
save_to_txt()2、用pyecharts对爬取到的星级评分进行饼图可视化处理

starScore.py
__author__ = 'xiaoguo'
from pyecharts import Pie
# 获取评论中的所有评分
star_rates = []
with open('maoyanContent.txt', mode='r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
star = line.split(',')[4]
star_rates.append(star)
# 定义星级
attr = ['五星', '四星', '三星', '二星', '一星']
value = [
star_rates.count('5') + star_rates.count('4.5'),
star_rates.count('4') + star_rates.count('3.5'),
star_rates.count('3') + star_rates.count('2.5'),
star_rates.count('2') + star_rates.count('1.5'),
star_rates.count('1') + star_rates.count('0.5'),
]
pie = Pie('《一出好戏》星级评分',
title_pos='center',
width=900,
)
pie.add('',
attr,
value,
is_label_show=True,
legend_pos='left',
legend_orient="vertical",
radius=[20, 60],
)
pie.render('《一出好戏》电影评分饼图.html')3、用pyecharts对爬取到的电影评论进行词云图可视化处理

以下的代码可以根据给定的图片生成和图片一样形状的词云图:
# 导入背景图
bg_image = plt.imread('bg.jpg')commentsWordCloud.py
__author__ = 'xiaoguo'
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from wordcloud import STOPWORDS
# 获取所有评论的内容
contents = []
with open('maoyanContent.txt', mode='r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
ct = line.split(',')[3]
content = ct.replace(',', ',')
if ' ' != content:
contents.append(content)
# 设置分词
content_after_split = jieba.cut(str(contents), cut_all=False)
words = ' '.join(content_after_split) # 以空格进行拼接
# 设置屏蔽词汇
stopWords = STOPWORDS.copy()
stopWords.add('电影')
stopWords.add('一出')
stopWords.add('好戏')
stopWords.add('有点')
# 导入背景图
bg_image = plt.imread('bg.jpg')
# 设置词云的参数
wc = WordCloud(width=1024, height=768, background_color='white', mask=bg_image, stopwords=stopWords, max_font_size=400, random_state=50, font_path='STKAITI.TTF')
# 将分词后的数据导入云图
wc.generate_from_text(words)
# 绘制图像
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
plt.show() # 显示图像
# 保存图像到文件
wc.to_file('黄渤一出好戏评论词云图.jpg')
4、用pyecharts对爬取到的粉丝位置进行可视化处理
在处理地理位置的时候可能会报错,缺少城市的包,需要下载以下三个包:
echarts-china-cities-pypkg (0.0.8)
echarts-china-provinces-pypkg (0.0.2)
echarts-countries-pypkg (0.1.4)粉丝地理位置可视化图:

粉丝排行3D可视化动图
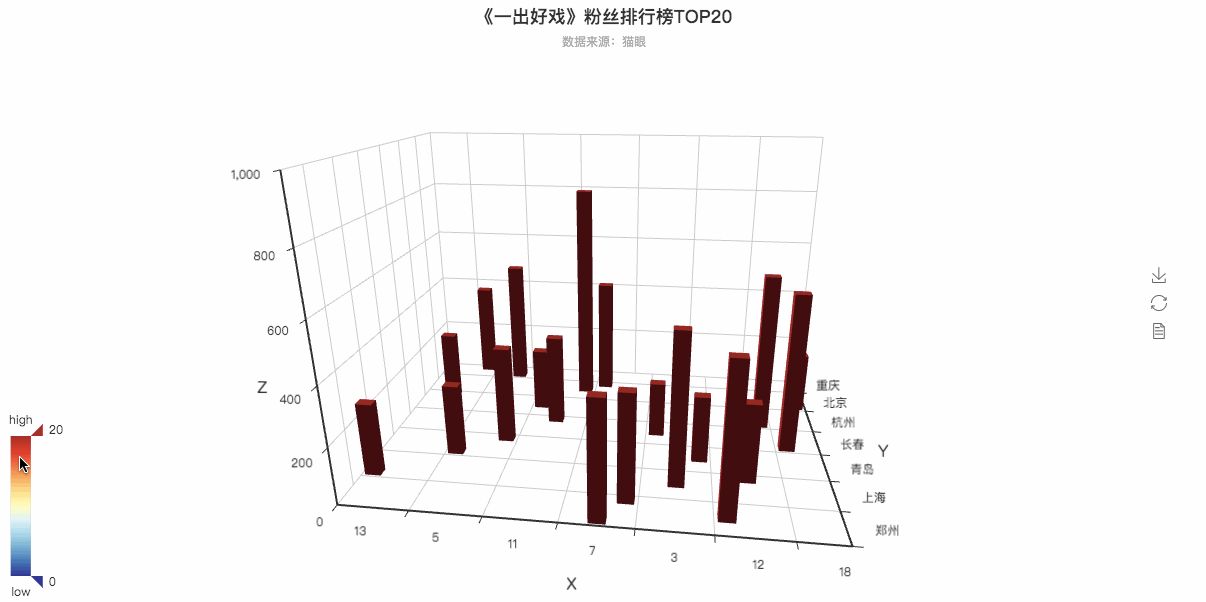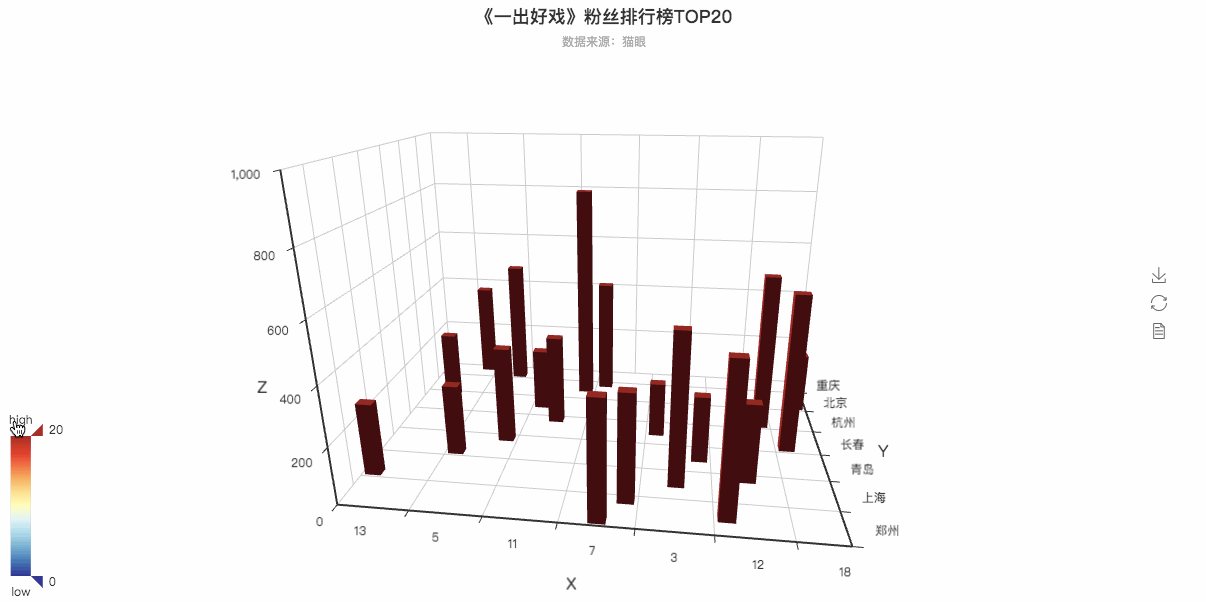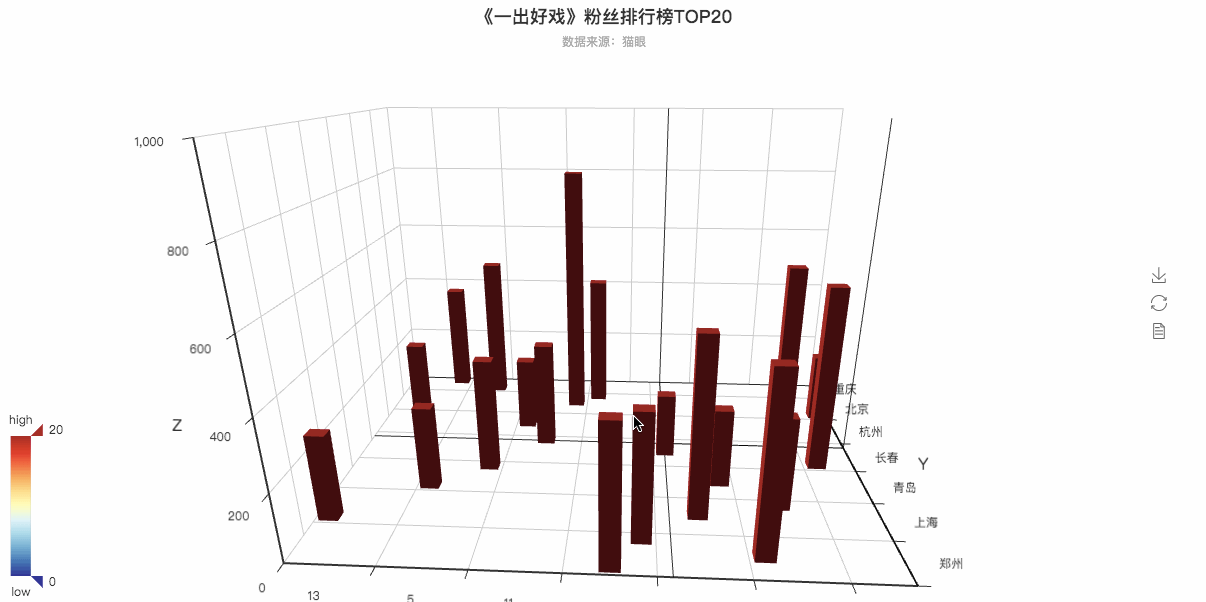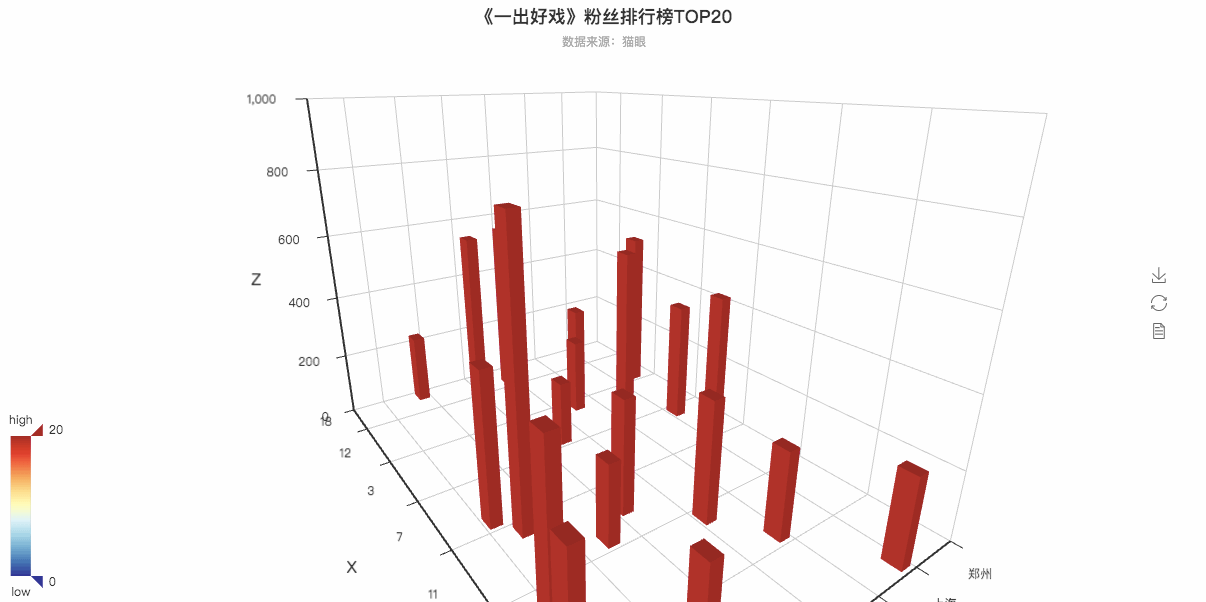
is_grid3d_rotate=True,
grid3d_rotate_speed=50,以上的两行代码是决定这个3D图是否可以转动以及转动的速度
fanLocation.py
__author__ = 'xiaoguo'
# 快速统计元素出现的次数库
from collections import Counter
from pyecharts import Geo, Bar, Page, Bar3D
import json
import pandas as pd
def render():
# 获取所有城市的信息
cities = []
with open('maoyanContent.txt', mode='r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
city = line.split(',')[2]
if '' != city:
cities.append(city)
# 对地图中的城市数据和坐标文件中的地名进行处理
handle(cities)
data = Counter(cities).most_common()
page = Page(page_title='《一出好戏》')
# 根据城市生成地理坐标图
geo = Geo(
"《一出好戏》粉丝位置分布图",
"数据来源:猫眼",
title_color="#fff",
title_pos="center",
width=1200,
height=600,
background_color="#404a59",
)
attr, value = geo.cast(data)
geo.add(
"",
attr,
value,
visual_range=[0, 400],
visual_text_color="#fff",
symbol_size=15,
is_visualmap=True,
)
geo.render('《一出好戏》粉丝位置分布图.html')
page.add(geo)
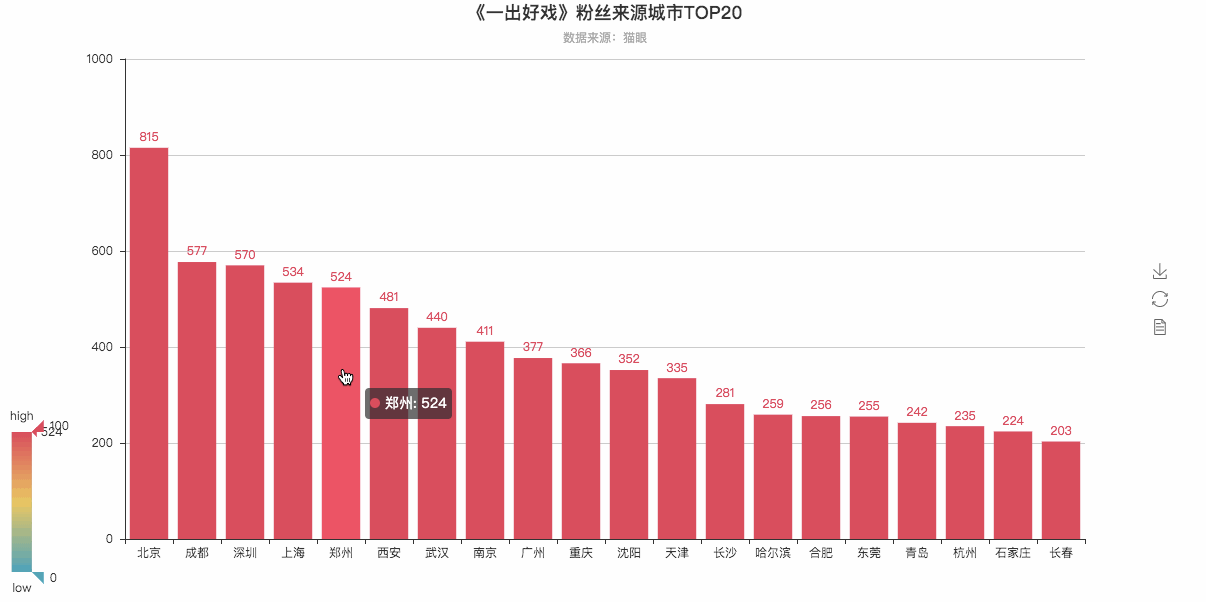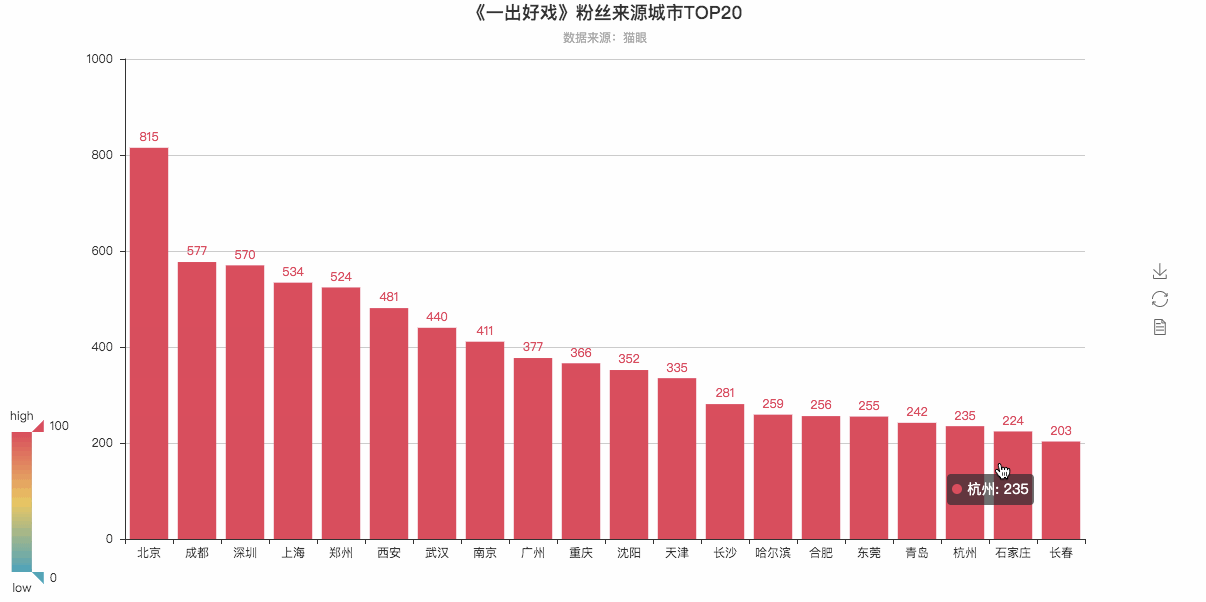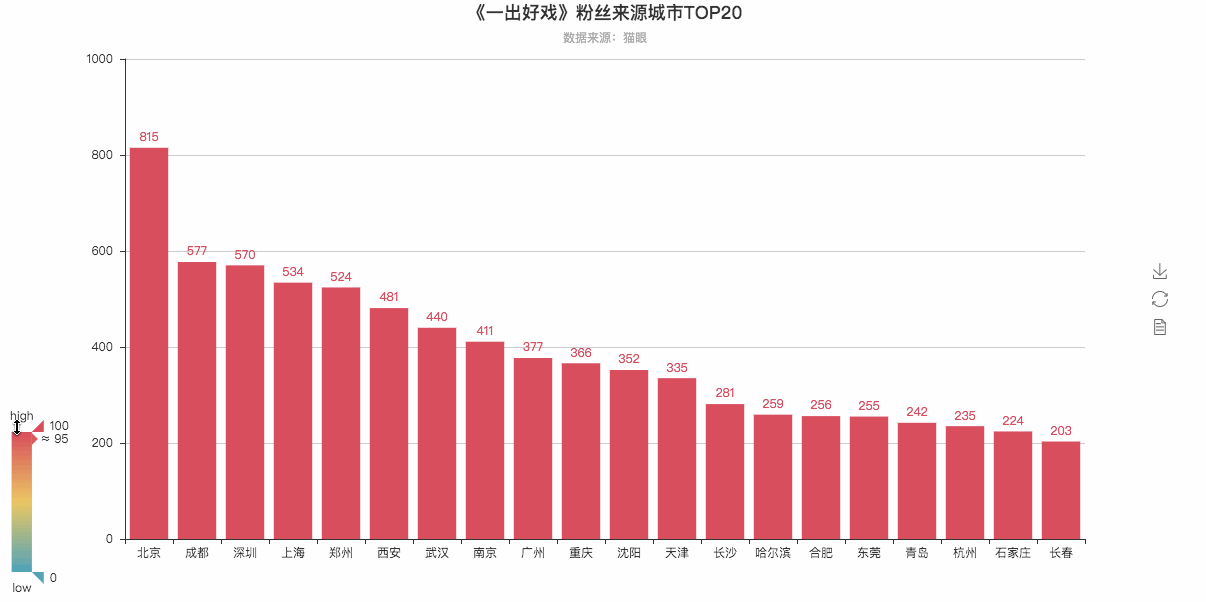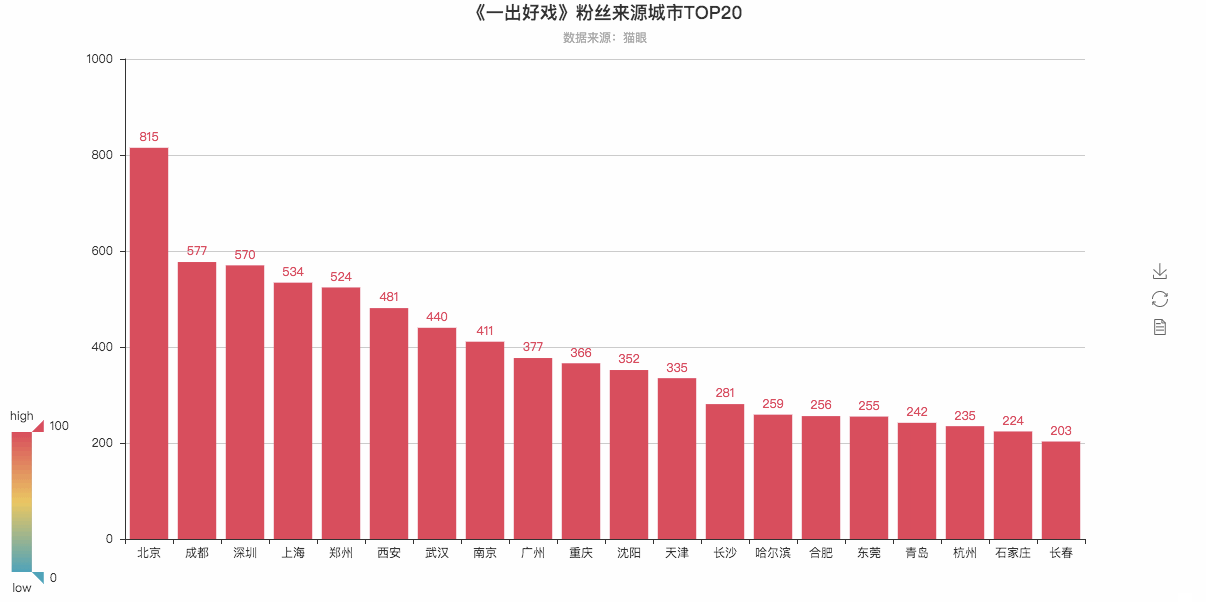
# 根据城市数据生成柱状图
cities_top20 = Counter(cities).most_common(20) # 返回出现次数最多的20条
bar = Bar(
"《一出好戏》粉丝来源城市TOP20",
"数据来源:猫眼",
# title_color="#fff",
title_pos="center",
width=1200,
height=600,
)
attr, value = bar.cast(cities_top20)
bar.add('',
attr,
value,
is_label_show=True,
is_visualmap=True,
)
bar.render('《一出好戏》粉丝来源排行榜TOP20—柱状图.html')
page.add(bar)
# 根据城市数据生成Bar3D图
xt = []
yt = []
for city in cities_top20:
xt.append(city[1])
yData = city[0]
yt.append(yData)
xs = [str(i) for i in range(20)]
data = pd.DataFrame({'ls': xs, 'city': yt, 'sales': xt})
x_name = list(set(data.iloc[:, 0]))
y_name = list(set(data.iloc[:, 1]))
data_xyz = []
for i in range(len(data)):
x = x_name.index(data.iloc[i, 0])
y = y_name.index(data.iloc[i, 1])
z = data.iloc[i, 2]
data_xyz.append([x, y, z])
range_color = ['#313695', '#4575b4', '#74add1', '#abd9e9', '#e0f3f8', '#ffffbf',
'#fee090', '#fdae61', '#f46d43', '#d73027', '#a50026']
bar3D = Bar3D(
'《一出好戏》粉丝排行榜TOP20',
'数据来源:猫眼',
width=1200,
height=600,
title_pos='center',
)
bar3D.add(
"",
x_name,
y_name,
data_xyz,
is_visualmap=True,
visual_range=[0, 20],
visual_range_color=range_color,
grid3d_width=150,
grid3d_depth=100,
is_grid3d_rotate=True,
grid3d_rotate_speed=50,
grid3d_shading="lambert",
)
bar3D.render('《一出好戏》粉丝排行榜TOP—Bar3D.html')
page.add(bar3D)
page.render('《一出好戏粉丝分布及排行榜TOP20》.html')
# 用来处理地名数据,解析坐标文件中找不到地名的问题
def handle(cities):
with open('/存储文件的位置/Library/Python/3.6/lib/python/site-packages/pyecharts/datasets/city_coordinates.json', mode='r', encoding='utf-8') as f:
# 将字符串转换成字典
data = json.loads(f.read())
# print(data)
# 循环判断处理
data_new = data.copy() # 把地图库里面的数据复制一份
for city in set(cities):
count = 0
for key in data:
count += 1
if key == city: # 如果找到相同的就停止
break
if key.startswith(city): # 用来处理简写的地名 如:把 '郑州市' 简写为 '郑州'
data_new[city] = data[key]
break
if key.startswith(city[0:-1]) and len(city) >= 3: # 用来处理行政变更的地名 如: 把 '溧水县' 改写成 '溧水区'
data_new[city] = data[key]
break
# 用来处理不存在的情况
if count == len(data):
while city in cities:
cities.remove(city)
# print(len(data), len(data_new))
# 将修改后的坐标数据写入坐标文件
with open('/存储文件的位置/Library/Python/3.6/lib/python/site-packages/pyecharts/datasets/city_coordinates.json', mode='w', encoding='utf-8') as f:
# 将字典转换成字符串 (ensure_ascii=False 指定支持中文)
data_new = json.dumps(data_new, ensure_ascii=False)
f.write(data_new)
if __name__ == '__main__':
render()
粉丝Top20可视化柱状图