文章目录
一、对象持久化
对象持久化必要性
概论:所有程序运行过程,就是使用我们编写的指令,来调度运算我们特定的数据或数据结构,但这个运算过程在内存里边;我们知道内存不是永久性存储,当我们断电,内存中的状态或数据就会丢失,当然在实际计算可能需要将当前需要计算的某个数据结果永久存储起来,就要用到对象的持久化。如:玩游戏过关时,这个状态是在内存中表现的,若想明天接着玩,我们可以把当前进度保存一下。所谓当前进度保存即将当前程序游戏运行的内存的结果存储在硬盘中或其他物理存储介质上。此时下次打开时可以接着上次的进度继续玩了,即将进度与状态存储在媒介上,这个过程就称为序列化 ,当第二天接着玩时,要将存储的内容反序列化到内存中,还原之前的状态,这个称为反序列化。
实际开发中,对象持久化技术有:可以使用文本文件来存储,这种形式即以扁平的文件来持久化我们的数据。还可以使用Python提供的pickle,还提供了类似字典表存储的shelve,实际开发中会用到数据库,即可以是典型的关系型数据库,在面向对象可能还有一些文档型数据库mongdb数据库也都是数据持久化的技术;其次为了便于在编程中做映射操作,还会用到orm,叫对象关系映射的框架即对象关系映射技术。
我们学习:扁平文件,pickle,shelve如何序列化持久化保存我们的对象在Python编程中,以及在特定场景下如何反序列化我们已经保存的持久化的对象。
使用格式化文本文件
注:二进制文件也可以保存我们的信息,不过操作起来麻烦一些。
文本初衷就是保存一些文本信息,若要保存运算的结果或数据对象,有个问题要解决,因为在内存中运行的对象有特定的结构或类型,如列表,字典表,类型的实例,若一旦存储在文本中,变成纯文字,当再反序列化载入到内存中,还原当前状态时,要有类型还原步骤,即相对麻烦。
1文本文件操作
1with会自动关闭文件,并将文件存储在本地硬盘中。
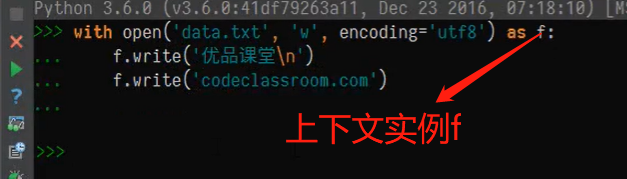
2 当从内存中写到文本文件中。
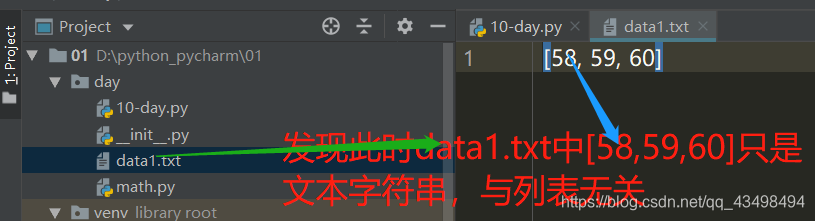
scores=[58,59,60]
#将列表存储在文件中
def writescore():
with open('data1.txt','w',encoding='UTF-8') as f:
f.write(str(scores))#只能写字符串,所以转一下。
print('写文件完成')
if __name__=='__main__':
writescore()
测试结果:
3读取到程序中来,并还原它本来的类型。
内置函数eval,它可以将读到的字符串转换为Python的表达式,此时可以将他当作Python语句来运行了。
注:但当存储的类型复杂时,如字典表,类的实例对象时,必须小心。所以一般文本文件就让它存一些文本信息就行。若想持久化对象,并很容易还原之前类型可以用pickle
#读取文本文件到内存中。
def readscore():
with open('data1.txt','r',encoding='UTF-8') as f:
#ls=f.read()#一次将文本文件信息所有都读出来
#但此时ls是字符串,若用list()函数转换呢?
#结果为:['[', '5', '8', ',', ' ', '5', '9', ',', ' ', '6', '0', ']'],原因是:因为list转换是将字符串中每个字符都会转换为列表中的一个元素,所以出现了这个结果。
#所以用文本存储有类型的对象比较麻烦。
#但Python为我们提供了一个内置函数eval,它可以将读到的字符串转换为Python的表达式,即此时在文本文件声明的中括号即[58, 59, 60]为Python语句,或在上下文中直接可以表示成列表。
#即可以转换为Python中声明的表达式了,并声明为列表了。即
ln =eval(f.read())#此时ln已经是一个列表了。
ln[0]=99#列表支持改值
print(ln)#结果为:[99, 59, 60]
2使用常见的pickle进行对象持久化
首先pickle为我们提供了一个pickle模块,这个模块封装了一系列方法和接口,就是让我们将内存中原有的Python对象序列化为字符串或本地的一个文件。
序列化到字符串中,再反序列化为原来类型
import pickle
person={'name':'tom','age':15}
#1选择,我可以将它转换为字符串,以后需要时,再将字符串存到文本中,
# 读取时再把字符串还原为之前的内容,这个过程由pickle的内置方法帮我们完成。
s=pickle.dumps(person)#不管你什么类型,几乎所有类型,dumps都可以将他序列化为一个字符串
print(s)#此时就是一个字符串,只不过存的是二进制字符串如:b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x03\x00\x00\x00tomq\x02X\x03\x00\x00\x00ageq\x03K\x0fu.'
#我们不用关心里边存储细节,需要时可以将字符串还原为字典表。
a=pickle.loads(s)#从字符串中载入一个对象变为a,此时a即为原来的字典表了,即原来的类似与特征了。
print(a)#{'name': 'tom', 'age': 15}
序列化到二进制文件中,再反序列化为原来类型
import pickle
person={'name':'tom','age':15}
#2使用pickle将有类型的对象序列化保存到文件中。再从文件中反序列化读取。此过程中使用二进制文本文件
pickle.dump(person,open('db','wb'))#参数一:要序列化哪个对象;参数2:将这个序列化后对象存储在那个文件中;
# 可以告诉它在当前工作目录下准备一个叫db文件,但不要当成一般文件,而是二进制文本文件,所以为'wb'
#此时这个文件即在工作目录下了,没办法打开,因为不是.txt,没办法识别,就是因为是一个二进制文件,
p=pickle.load(open('db','rb'))#载入时,从db文件以二进制方式给我读取这个文件,即反序列化给变量p
print(p)#即p就是{'name': 'tom', 'age': 15},原来的字典表了。
总结:
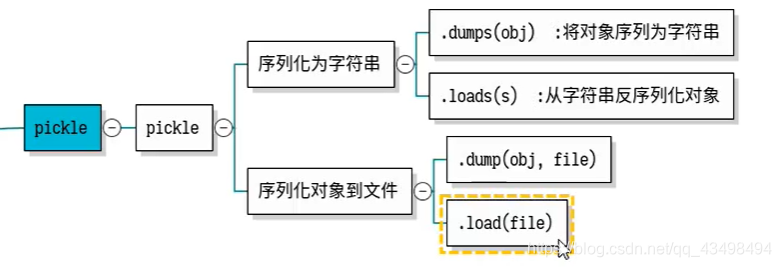
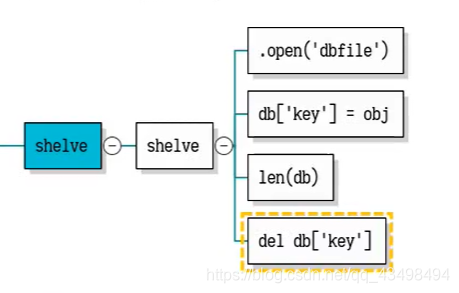
3使用常见的shelve进行对象持久化
注:1当pickle将多个对象存储在一个文件中时,反序列化时是把整个文件进行反序列化,所以剥离出我们想要的对象时麻烦。如可以将不同的对象存储在不同的文件中,但是这样维护起来又麻烦。若将多个对象存在文件中,我们可以通过字典表,不同的键值对组织也可以,但还是有另外工作做。
2 因此我们使用Python内置的shelve模块来帮助我们实现。它可以将多个对象存储在一个文件中,之后访问类似我们字典表的形式,即通过给不同的对象加上键,这样存取都可以通过键值来访问了。。
1、存对象到指定文件中
import shelve
#建立两个对象
score=[58,59,30,65]
person={'name':'tom','age':15}
#我们通过shelve下的一个方法open来帮助建立一个文件来存储数据
#声明一个叫db的数据库,只是意义上的数据库,不是真的mysql那种数据库,如下:
db=shelve.open('student')#这里不用指定是写还是读,是文本还是二进制, #直接就可以建个二进制student文件来存储我们信息
#有了db数据库文件后,可以直接把对象往里边放了。
db['s']=person#这样来保存一个人的信息,此时可将字典表序列化到意义上的数据库文件db中了,通过键‘s’
db['scores']=score
#检查一下db数据库中保存了几个对象,#检查一下db数据库中保存了几个对象,使用len查看保存几个对象
len(db)#结果为2个键值
2、成功建立了文件,说明存过程完毕。
3 读取对象反序列过程。
a=db['s']#通过键s即可以返回取到之前的对象了
print(a)#即返回之前存的字典表了
b=db['scores']
print(b)#即返回之前存的列表了
4 删除对象在数据库文件中
#删除数据库db中的一个对象
#全局函数del
del db['scores']
print(len(db))#此时只剩1个对象了,即访问不到scores了
5 一个自己定义的类,创建实例也可以通过shelve序列化存我们的实例对象
import shelve
class student:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self):#定义打印实例的呈现方式
return self.name
#将类的实例化进行文件保存
def write_shelve():#存方法
s=student('tom','age')
#1声明数据库文件,构建一个叫student_db的二进制文件
db=shelve.open('student_db')
#2通过指定键往里边存,一个实例
db['s']=s
db.close()#关掉数据库这个二进制文件保险一点
if __name__=='__main__':
#运行存取过程,会出来好多文件,有目录文件及备份文件等
write_shelve()
运行存取过程,会出来好多文件,有目录文件及备份文件等:说明存成功。
将内容从文件中读取出来
import shelve
class student:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self):#定义打印实例的呈现方式
return self.name
#将类的实例化进行文件保存
def write_shelve():#存方法
s=student('tom','age')
#1声明数据库文件,构建一个叫student_db的二进制文件
db=shelve.open('student_db')
#2通过指定键往里边存,一个实例
db['s']=s
db.close()#关掉数据库这个二进制文件保险一点
def read_shelve():#来读取内容出来,反序列化
#1打开数据库的二进制文件
dc=shelve.open('student_db')
st=dc['s']
print(st)#打印实例,即呈现方式为定义的__str__打印方式
print(st.name)
print(st.age)
#读取完后,可以关闭当前操作的二进制student_db文件
dc.close()
if __name__=='__main__':
#因为已经有文件存在了,所以可以使用读函数直接去读了。
read_shelve()
测试结果:
tom
tom
age
二、字符串的本质
Python3的字符串存储机制
字符串类型分类
1一般可见可读的,用单双引号声明的类型,即str类型。
2 bytes字节类型,不可变类型
3 bytearray,字节数组类型,可变类型
三种类型的转换
将字符串类型以字节形式通过文件进行读取
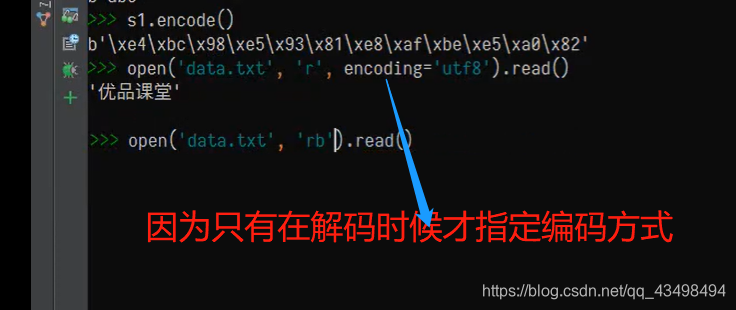
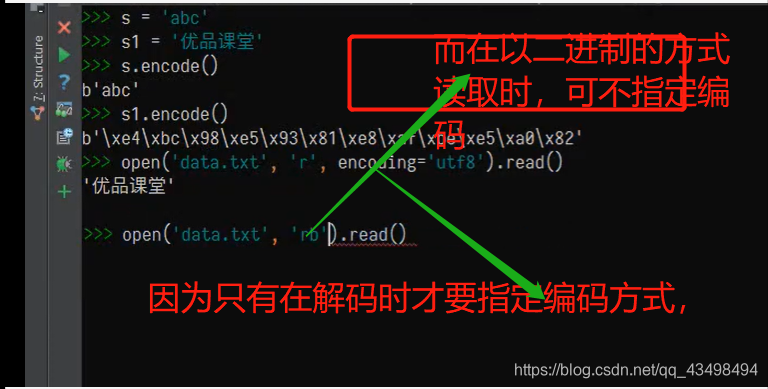
即可以通过文件读取形式,直接可以读取对应的二进制编码的字节,可以不指定编码,如下: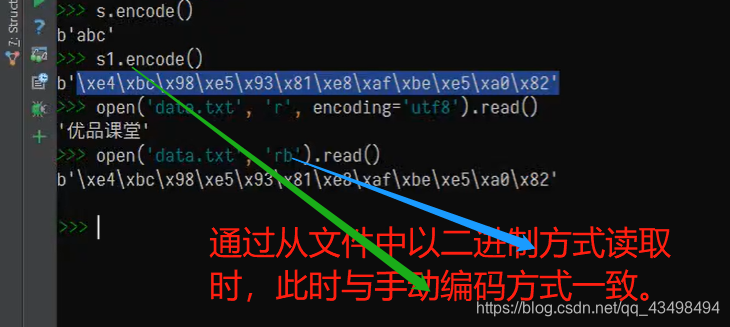
bytes字节类型
2获取字节型的字符串方法
#1 也可以通过函数bytes来转换,获取字节字符串
# bytes('abc','ascii')#将字符串转化为字节形式时,要指定其编成字节形式的编码方式。
# print(bytes('abc','ascii')#结果为:b'abc'有b,即为字节了。
print(bytes('优品课堂','utf-8'))#结果:b'\xe4\xbc\x98\xe5\x93\x81\xe8\xaf\xbe\xe5\xa0\x82'
#也可将序列中对应代码点的字符以字节呈现出来。
print(bytes([88,89,65]))#结果为b'XYA' 注意这种整型数字不要超过256,因为默认只处理一个字节存储的字符
#2也可以直接赋值,获取字节字符串
a=b'abc'#此时a的类型就是字节型字符串了
print(a)
print(a[0])#可得出字符串a的第一个字符元素代码点为97
a[0]=98#会报错,'bytes' object does not support item assignment, 即字符串的字节型不支持原位改变赋值。
# 即与字符串也不支持原位改变一样,区别在于一个是字节,一个是字符文本
#3通过encoede获取字节字符串
s.encode()
bytearray字节数组类型,支持原位改变,类似列表类型
注:因此我们之所以使用字节数组,相对字节在某些场景要二进制操作时,字节数组支持原位改变
s1='abc'
s2='优品课堂'
s3=bytearray(s1,'utf8')#一定要指定得到的字节数组是通过什么编码得到的。,否则还原解码时不好解码。
print(s3)#结果为:bytearray(b'abc')
#1对应一些操作,以前列表的类似操作基本可以应用到字节数组上
print(s3[0])#也可以获取每个索引对应字符的代码点如97
s3[0]=98
print(s3)#支持原位改变之后的为:bytearray(b'bbc')
#2 s3.append(2048)
#print(s3.append(2048))#会报错,因为提示我们追加的范围不能超过256,尽管采用utf8编码,这点要注意
s3.append(212)#运行结果为:bytearray(b'bbc\xd4')
print(s3)
#3也可以相加操作
print(s3+b'C!')#bytearray(b'bbc\xd4C!')
#3最终根据需要又要转换为字符串,z字节数组也有decode解码方法,通过解码即可以了
#s3.decode('utf8')
#print(s3.decode('utf8'))#会报错,UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd4 in position 3: unexpected end of data
#因为刚才的代码点212对应的字符没在utf8中,所以解码时出错了。
s4=bytearray('abc','utf8')
s4.append(93)
print(s4)#将代码点93传进去,即会增加93对应的字符进去,结果:bytearray(b'abc]')
#将字节数组以utf8的编码方式,给我去解码成字符串
s4.decode('utf8')
print(s4.decode('utf8'))#结果为abc]即字符串了。
总之:在把文件文本存储到媒介,或者是在网络上传输时,此时要将字符串转换为字节形式进行传输。注意不同的编码方式可能会转换到不同的二进制字节上。
概述
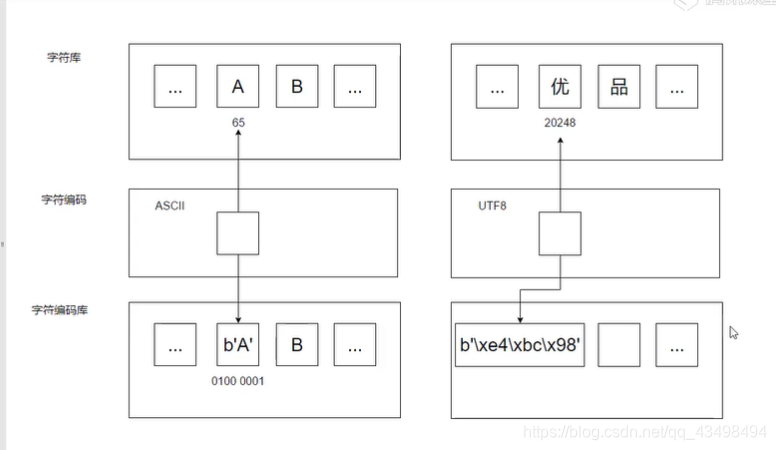
字符串的编码架构,编码方式如utf-8,ascii码只是将字符与字节编码之间来回转换。
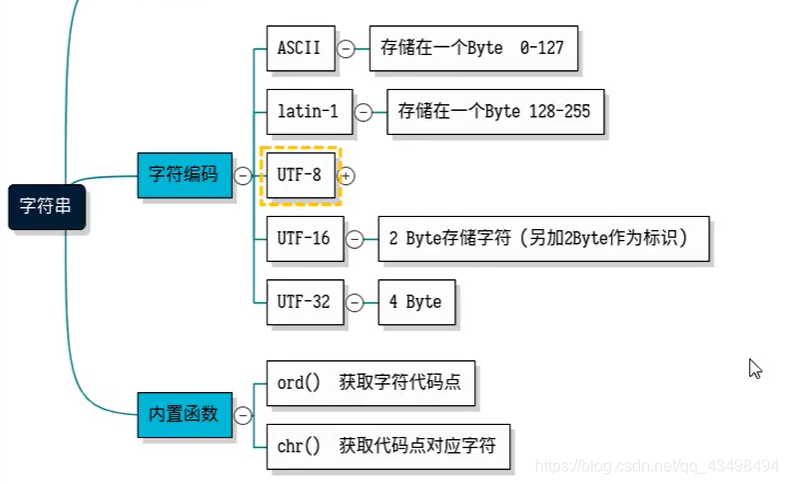
三 、UTF-8、ASCII常用字符串编码
此处为各编码方式的在字符库中代码点与字符对应:并未涉及最终编码的字节,如下图:
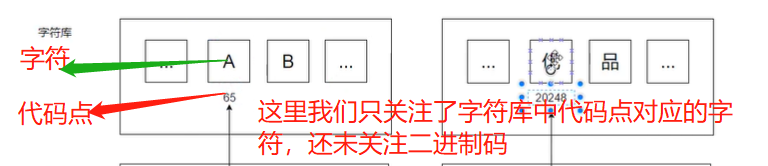
ASCII 0-127代码点之间
存储在一个字节里面,即8位,0-127对应相应的字符的代码点,即字符在字符库中的代码点。
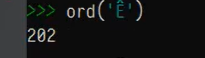
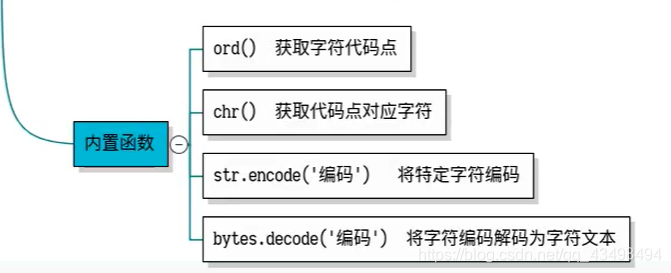
# 函数ord获取字符代码点
ord('a')#可以获取字符a在字符库中的代码点如97
print(ord('a'))
print(chr(104))#获取对应代码点104对应的字符为h
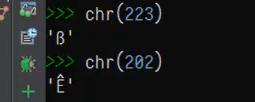
latin-1为拉丁1字符码
1存储也是在一个字节中。即128-255之间
如下面获取的拉丁字符:
UTF-16
通过两个字节来存储,另外加了两个字节来作为标识。
UTF-32
4字节存储字符。兼容性好,里面可以包含任意字符。但是若只存ASCII码,即浪费内存空间。
通用可变字长UTF-8,通用性好。
即通过utf-8编码的话,一个字符用几个字节不确定,即代码点在0-127之间,仍使用单字节来存储。
128-2047这些代码点使用双字节存储。2047之后,使用3或4字节进行存储。
注意:虽然使用了多字节,但每个字节他只使用了一半即128-255的代码点范围,因为他始终要把正在使用的这个字节的前半部分即0-127的范围留给ASCII码。
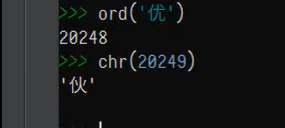
如下为:中文字符‘优’对应的代码点
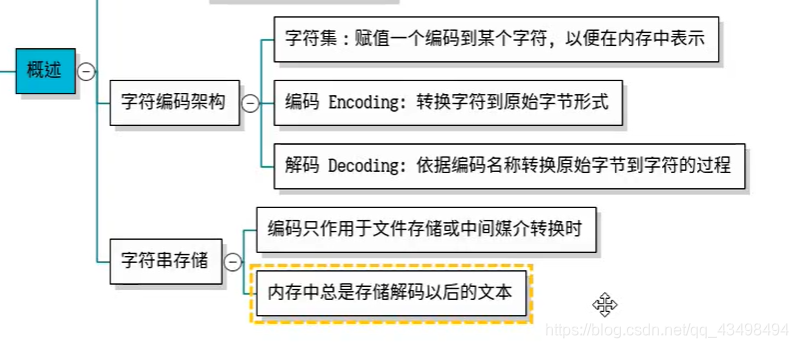
四、字符的编码与解码
注:1这里与在文件读取时的编码与解码是一致的。
注;2可以了解我们字符不仅与代码点有关,以下为字符与编码解码的字节有关介绍。
注:3以后会从网络或硬件端口得到一些数据,都是以字节形式存在的,以b开头九就为字节形式。
如:b’\xe4\xbc\x98\xe5\x93\x81\xe8\xaf\xbe\xe5\xa0\x82’
注:4 字符串的解码与编码默认是utf-8,而文件默认是gbk
编码
#encode编码方法,这个方法依赖于字符串这个类型的。是字符串的一个方法。
#假如我有个字符,不管来自哪个字符集,有可能是ASCII,拉丁,GBK,通过特定编码转化为字节形式。
s='abc'#声明一个字符串
s.encode('ASCII')#采用ASCII编码方式编码为字节形式。
print(s.encode('ASCII'))#结果为:b'abc'
# 原因是:ASCII码的代码点与它二进制编码形式一致,
# 所以没有显示数字形式,而是显示的仍是对应字符形式,即b'abc'
#如字符A,代码点为65,其ASCII编码的二进制为:01000001,而只不过是65的二进制表示形式,本质仍然是65,所以仍然显示代码点对应的字符了
#因为b'abc',有b,说明已经是一个字节了,不是字符了。虽然看着像字符,是因为ASCII码的代码点与它二进制编码形式一致, 所以没有显示数字形式,而是显示的仍是对应字符形式,即b'abc'
s1='优品课堂'
#s1.encode('ASCII')#此时会报错,因为在ASCII的字符表中并没有规定中文的编码,所以会报错。
s1.encode('utf8')#可省略-
print(s1.encode('utf8'))#b'\xe4\xbc\x98\xe5\x93\x81\xe8\xaf\xbe\xe5\xa0\x82'
#即将中文编码成字节形式显示了。
print(s1.encode('utf-16'))#此时用这种编码与utf-8编码不一样。即乱码:此时用utf-16编码但用utf-8解码即会乱码了。
#以后会从网络或硬件端口得到一些数据,都是以字节形式存在的,以b开头九就为字节形式。
解码
注:所以在网络或数据库操作时遇到的乱码与现在就是差不多的,肯定是所用的编码与解码不是同一种。所以必须指定正确的编码方式
#将字节形式,知道是字符的字节形式,也知道他编成字节的编码方式,那如何转化为可读可写的字符文本呢。
a=b'\xe4\xbc\x98\xe5\x93\x81\xe8\xaf\xbe\xe5\xa0\x82'
#编码用utf-8,所以解码时也要用utf-8解码
a.decode('utf-8')
print(a.decode('utf-8'))#解码的文本为;优品课堂
#若以utf-16解码时,就会乱码,如
print(a.decode('utf-16'))#볤膓꿨芠
#所以在网络或数据库操作时遇到的乱码与现在就是差不多的,肯定是所用的编码与解码不是同一种。所以必须指定正确的编码方式
字符串默认编码解码
#在Python中不指定编码方式默认为utf-8编码
s1='优品课堂'
print(s1.encode())#即b'\xe4\xbc\x98\xe5\x93\x81\xe8\xaf\xbe\xe5\xa0\x82',
print(s.encode())#b'abc'发现怎么与ascii编码一样,因为utf-8兼容ASCII码
import sys#导入系统模块
#获取默认编码
sys.getdefaultencoding()#当前系统默认为utf-8编码
文件读取的编码与解码
1.所谓文件编码只在文件存储中有意义,而在内存中存储的总是我们人类可读的字符。
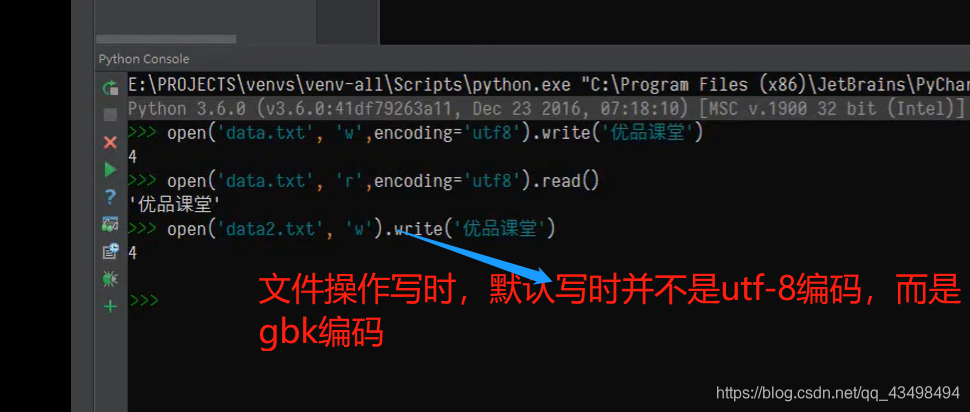
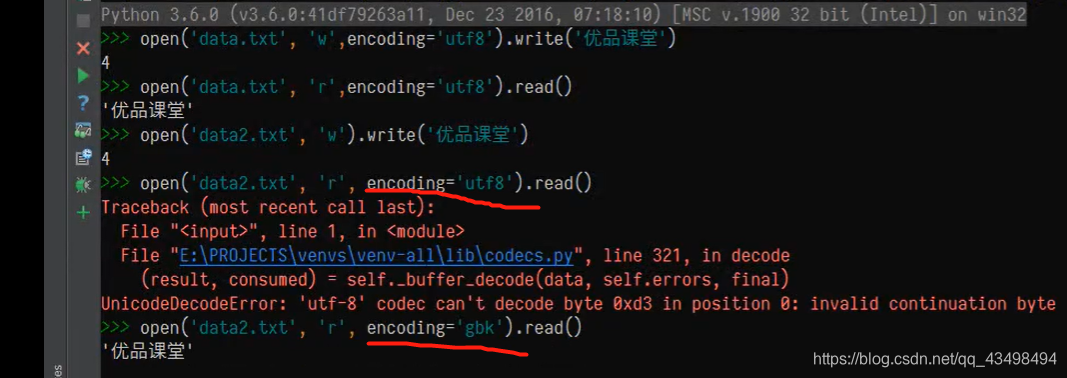
2.因为文件默认编码方式是gbk,所以以utf-8读取文件时肯定会出错,必须以gbk读取时,才对。如下图:
字符串BOM处理(字节顺序标记)
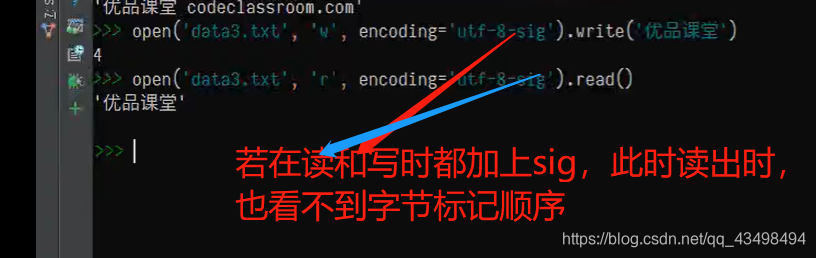
1首先有个文件,可以是别人给的一个文件,或者是从网络上获取到的信息。如图:
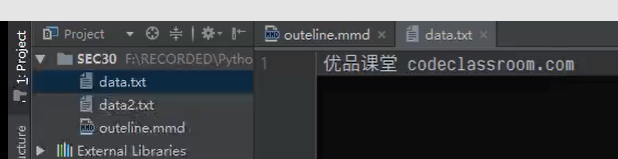
2我们可以通过文件读取。如下图;尽管我们在写好文件时,保存文件时,除了指定编码方式为utf8,还可以加上字节顺序标记。所以我们从别的地方拿到一个文件时,可能带的编码是一致的,也是utf8,但是他额外存储了字节顺序标记,导致我们读取文件之后前边有个顺序标记,尽管不影响我们阅读。
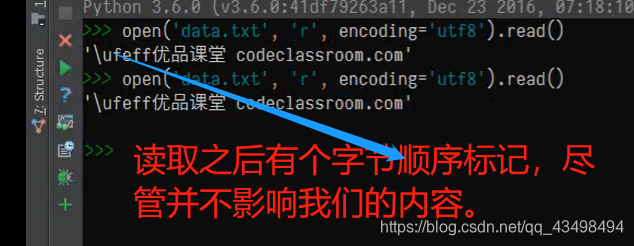
3我们可以采取在读取时就可以忽略这个字节顺序标记。我们在读取文件时,可以指定编码方式,也可以指定字节顺序标记是否添加。
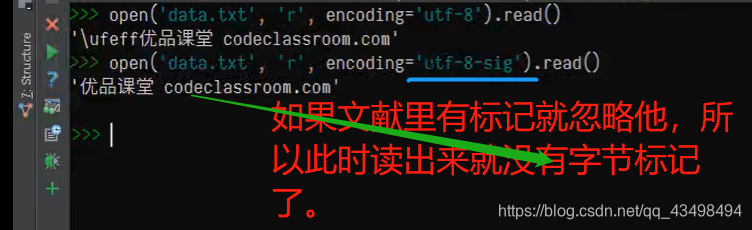
4注意在以下这种情况是,若只在写的时候 加上-sig,则读的时候不加,就会看到字节顺序标记。但这个字节顺序标记你是乱码。