开发环境:R STUDIO
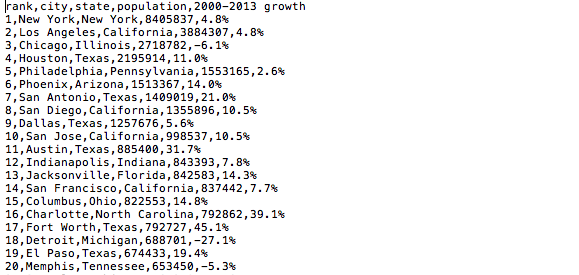
数据样本:美国城市人口及2000-2013年的人口增长率
格式:txt
1. 首先,基于对数据的观察,提出的几个问题:
- 2013年,人口排在前五的城市是哪些?
- 2013年,人口增长率排在前五的城市是哪些?
- 2013年,人口负增长率排在前五的城市是哪些?
- 2000年,各个城市的人口是多少?
2. 数据导入和预处理
setwd("/Users/mac/Desktop/Data Sample")
Add = read.csv("gistfile1 copy.csv", header = T, stringsAsFactors = F,)
1)去掉原有行标
mydataframe <- Add[2:5]
2)转化为数据框
as.data.frame(mydataframe)

3)数据类型的转换
先查看各列数据类型的情况
sapply(mydataframe, mode)
sapply(mydataframe, class)

可以发现,人口数值和增长率默认储存为字符型数据,我们要将其转化为数值型
另外,人口增长率在此为百分数,而我们需将其转化为小数以方便后续计算。可先将列中数值百分号去除,再除以100,代码如下
mydataframe$X2000.2013.growth <- sub("%","", mydataframe$X2000.2013.growth)
mydataframe$X2000.2013.growth <- sapply(mydataframe$X2000.2013.growth, as.numeric)
mydataframe$X2000.2013.growth <- mydataframe$X2000.2013.growth / 100
处理后:


4) 删除缺失数据
mydataframe <- na.omit(mydataframe)
5) 预览

3. 解决提出的问题
1)2013年,人排在前五的城市是哪些?
newdata3 <- mydataframe[order(-mydataframe$population),]
newdata3[1:5,]
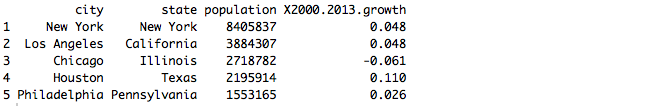
2013年人口排在前五的城市:
New York, Los Angeles, Chicago, Houston, Philadelphia
2)2013年,人口增长率排在前五的城市是哪些?
newdata <- mydataframe[order(-mydataframe$X2000.2013.growth),]
newdata[1:5,]
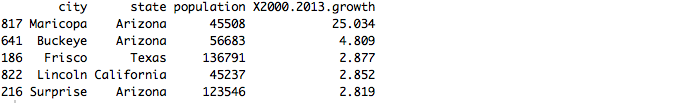
2013年人口增长率排在前五的城市:
Maricopa, Buckeye, Fresco, lincoln, Surprise
*观察发现,Maricopa的人口增长率远高于其他城市,此数据为异常值还是实际数据?
于是维基百科:
“Maricopa was officially incorporated as a city on October 15, 2003, becoming the 88th incorporated city in Arizona.
Between 2000 and 2010, the city's population grew from 1,040 residents to 43,482,
an increase of 4080%.[8]”
可以发现根据记载2000-2010年此城市人口呈爆炸性增长,数据属实。
3)2013年,人口负增长率排在前五的城市是哪些?
newdata2 <- mydataframe[order(mydataframe$X2000.2013.growth),]
newdata2[1:5,]
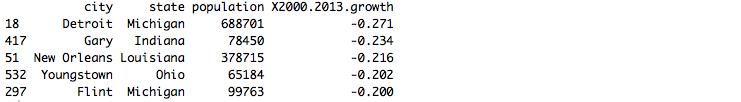
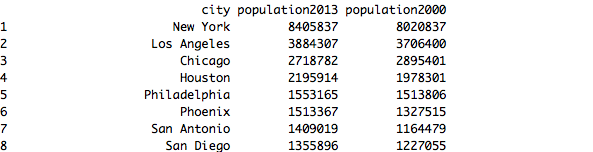
4) 2000年,各个城市的人口是多少?
city <- mydataframe$city
population2013 <- mydataframe$population
population2000 <- round(mydataframe$population / (1 + mydataframe$X2000.2013.growth))
mydataframe2 <- data.frame(city, population2013, population2000)
mydataframe2
输出结果为包含城市名称,2000年及2013年人口的数据框
最后,由此练习可以总结出,R语言数据分析中需要注意的几点:
- 导入数据时,需注意数据的储存类型,尤其是数字有时默认以字符型储存。
- 百分数的处理,需先转化为小数
- 异常值的分辨