1. 基本定义
| 符号 |
表示的意义 |
例子 |
|
u |
对于给定的用户,将这个用户的对物品的不完全评分数组称为
evaluation,这个
evaluation表示用户对物品的评分 |
u=<ui,uj,uk> 数组
u表示用户对物品
i,
j,
k的评分数组 |
|
ui |
表示用户对物品
i的评分 |
|
|
uAi |
表示用户
A对物品i的评分 |
|
|
S(u) |
表示用户的评分数组
u中包含的物品子集 |
例如对于数组
u=<ui,uj,uk>,
S(u)={i,j,k}表示用户有行为的关系的物品集合 |
|
χ |
表示训练数据中用户评分数组的集合 |
χ={uA,uB,uC} |
|
card(S) |
表示物品集合
S 中,物品元素的个数 |
card(S)=card({i,j,k})=3 |
|
u |
表示用户评分数组
u的平均评分 |
u=card(S(u))∑i∈S(u)ui |
|
Si(χ) |
表示在训练集
χ中所有包含物品
i的的评分数组 |
Si(χ)={u∣i∈S(u)} |
2. SlopeOne方案
在SlopeOne方案中基本思路如图Fig1.1。
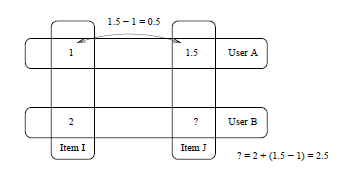
在图Fig1.1中,给出了两个用户
UserA和
UserB以及两个物品
ItemI和
ItemJ。在上图中可以得到一个稀疏评分矩阵
|
Item
i |
Item
j |
|
UserA |
1.0 |
1.5 |
|
UserB |
2.0 |
? |
根据上述的稀疏矩阵,需要我们预测
UserB对于
Item
j的评分。采用SlopeOne方案对评分预测的计算结果如下。
uBj=uBi−(uAi−uAj)=2.0−(1.0−1.5)=2.5(2.0)
根据SlopeOne评分预测方案,我们进一步扩展数据集中用户的数目和物品的数目,得到如下表所示的评分矩阵。
|
Item
i |
Item
j |
Item
k |
Item
l |
Item
m |
|
UserA |
1.5 |
1.0 |
1.2 |
1.0 |
2.0 |
|
UserB |
2.0 |
? |
4.0 |
2.1 |
4.0 |
|
UserC |
4.0 |
2.1 |
3.5 |
3.1 |
2.6 |
|
UserD |
3.0 |
2.3 |
2.0 |
2.1 |
1.0 |
|
UserE |
1.0 |
2.4 |
2.0 |
1.1 |
3.0 |
基于上述图Fig1.1给出的Demo,我们将两个用户两个物品的情况扩展到多个用户以及多个物品的情况。那么对于稀疏矩阵中所有
Item在所有用户下共同出现的评分差值计算结果如下。
| 物品 |
Item
i |
Item
j |
Item
k |
Item
l |
Item
m |
|
Item
i |
— |
0.425 |
-0.24 |
0.42 |
-0.22 |
|
Item
j |
-0.425 |
— |
0.225 |
0.125 |
-0.2 |
|
Item
k |
0.24 |
-0.225 |
— |
0.66 |
0.02 |
|
Item
l |
-0.42 |
-0.125 |
-0.66 |
— |
-0.67 |
|
Item
m |
0.22 |
0.2 |
-0.02 |
0.67 |
— |
评分矩阵的不同物品评分差值的结果计算方式如公式2.1所示。
devij=u∈Si(χ)∩Sj(χ)∑card(Si,j(χ))ui−uj(2.1)
通过公式2.1可以计算得到所有物品之间总的评分差,那么根据评分矩阵预测
User
B对
Item
j的评分计算方式如公式2.2所示。
P(uj)=card(S(uB))∑i∈S(uB)(devij+ui)(2.2)
根据上述公式计算得到
User
B对
Item
J的评分计算如下
P(uj)=4(2.0−0.425)+(4.0−(−0.225))+(2.1−(−0.125))+(4.0−0.2)=2.95625(2.3)
我们将公式(2.2)的分子累加部分拆开,得到的结果为:
P(uj)=card(S(u))∑i∈S(u)devij+card(S(u))∑i∈S(u)ui≈uˉ+card(S(u))∑i∈S(u)devij(2.4)
对于上述情况,前提条件是在用户评分
u中所有被评分的物品
i 都与需要被评分的物品
j 存在共现关系,在大的数据集合下,我们用物品已经观影用户的物品平均评分,代表所有与
Item
J共同出现的物品的平均评分,从而进行近似表示。
3 加权Slope One方案
在基本Slope One算法的基础上,没有考虑到物品之间贡献次数带来的关系。例如有三个物品I,J,K,现在需要预测对于物品K的评分。给出User A对于I和对J物品的评分如下,以及I与K,J与K的评分差和共现次数。
|
Item
i |
Item
j |
Item
k |
| User A |
3.5 |
2.4 |
? |
|
Item
i |
Item
j |
| 共现次数 |
1000 |
30 |
| Item K 评分偏差 |
0.5 |
0.2 |
如果根据原来的slopeOne计算方式,对评分的计算策略如下所示:
P(uk)=2.95+20.5+0.2=2.95+0.35=3.3(3.1)
在上述分析中,我们可以发现Item I和Item J与Item K共现的次数无论是多少,最终考虑的都是平均评分差,那么没有用到物品之间共现次数这个数据。在此基础之上,采用的加权slopeOne将共现次数引入到预测器中。我们认为一个物品和目标物品共现次数越多,更适合作为一个预测器,或者说所预测出来的得分置信度更高得到加权的SlopeOne方案如下所示。
P(uj)=∑i∈S(u)−{j}cj,i∑i∈S(u)−{j}(devj,i+ui)cj,i(3.2)
根据上述公式计算得到User A对物品K的评分,计算方式如下所示:
P(uj)=1000+301000∗(3.5+0.5)+30∗(2.4+0.2)=3.9592(3.3)
4 两极Slope One方案
通过上述加权的方式,对于头部流量的Item是具有优势的,这一部分Item出现的频率相对来说比较高。在下一步的方案中讨论的两极SlopeOne模式采用了一种新得评分预测方式。
在两极slopeOne的实现中,我们将预测分为两个部分:
并在此基础之上采用加权SlopeOne进行计算,利用用户喜欢的物品和不喜欢的物品预测对物品的评分。
首先给出一个从0~10 的评分范围,在给出的评分范围中,可能认为去中间值5作为阈值比较合理,这样的话我们将用户对Item评分大于5的表示为喜欢,小于5的表示为不喜欢,如果用户的评分是均匀分布的话,这样的设置会有一个较好的效果。然而在电影评分中70%的评分数据大概集中在中间位置。当我们希望这个喜欢和不喜欢的阈值划分适用于所有的用户(无论是倾向于高分评价用户,低分评价用户,两极评分用户)的时候,我们取每一个用户对物品的平均评分作为评分标准。
例如一个积极的用户,这样的用户可能对所有的物品都有较高的评分,那么对于低于他们平均评分的数据我们认为他们是不喜欢的。因此通过这个阈值,使得所有的用户都有合理的喜欢物品数和不喜欢物品数目。
根据上述Fig 1.1中的图示,那么在两极slopeOne中,我们需要如果通过
Item
J和
Item
I之间的共现次数来计算User B对
Item
J的评分。我们首先需要将用户分成喜欢这个物品和不喜欢这个物品两个用户组。
在SlopeOne方案中,对于物品的预测评分约束要求的更加严格。首先对于物品而言,只有对于两个g共现的物品都喜欢或者是两个物品都不喜欢的用户,我们才说这样的评分是有效的。也就是,一个用户对两个物品的评分在喜好上趋于一致的时候我们才说用用户对其中一个物品的一个评分去预测另外物品的一个评分是可靠的。其次,对于用户而言,只有一个用户对
Item
I和
Item
J同时表现出相同的喜好的时候,这个
Item
I才会用来去预测
Item
J的评分。
为了进一步解释上诉的例子,我们给出如下五个用户对五个物品的评分。
|
Item
i |
Item
j |
Item
k |
Item
l |
Item
m |
u |
|
UserA |
1.5 |
1.0 |
1.2 |
1.0 |
2.0 |
1.34 |
|
UserB |
2.0 |
? |
4.0 |
2.1 |
4.0 |
3.025 |
|
UserC |
4.0 |
2.1 |
3.5 |
3.1 |
2.6 |
3.06 |
|
UserD |
3.0 |
2.3 |
2.0 |
2.1 |
1.0 |
2.08 |
|
UserE |
1.0 |
2.4 |
2.0 |
1.1 |
3.0 |
1.9 |
根据上面的表格,在
UserA的行为评分数据中,只有
{i,m}和
{j,k,l}这两组共现是有效的。
将每一个用户分为喜欢用户和不喜欢用户,能够使得用户的数目增加。然后,我们需要注意的在两极方案通过严格的评分限制会减少在预测用户评分时候的共现次数。在用户评分的稀疏矩阵中,还要通过划分喜欢用户和不喜欢用户来提高准确度确实是不符合我们的直觉,但是如果考虑将不相关的物品在一起共同出现,可能引入更多的问题。至关重要的是,两极slope One方案没有从用户
A喜欢
Item
K和用户
B不喜欢
Item
K中预测任何东西
为了形式化描述,我们将每一个用户的评分数组
u分为两个评分集合:
| 符号 |
形式化描述 |
含义 |
表示作用 |
|
Slike(u) |
{i∈S(u)∣ui>u} |
表示在用户评分数组中大于平均评分的评分组成的物品评分数组 |
用户喜欢的
Item评分 |
|
Sdislike(u) |
{i∈S(u)∣ui<u} |
表示在用户评分数组中小于平均评分的物品评分组成的评分数组 |
用户不喜欢的
Item评分 |
在上述描述的基础上对于每一组共现物品评分集合都可以分为两个部分,这两个部分分别是同时喜欢
Item
i和
Item
J的一级同时不喜欢
Item
I和
tem
J的用户
evaluations,具体的形式化描述如下。
Si,jlike={u∈χ∣i,j∈Slike(u)}(4.1)
Si,jdislike={u∈χ∣i,j∈Sdislike(u)}(4.2)
使用这两个评分集合我们可以计算喜欢
Item
I和
Item
J的用户对这两个物品的评分差计算方式为。
devjlike,i=u∈Sj,ilike(χ)∑card(Sj,ilike(χ))uj−ui(4.3)
同样地对于同时不喜欢$Item
I和
Item
J的用户评分差的计算方式如下。
devjdislike,i=u∈Sj,idislike(χ)∑card(Sj,idislike(χ))uj−ui(4.4)
那么根据上述的描述可知,如果我们需要基于一个
Item
i预测一个
Item
J的评分,那么有两种方式具体如下所示。
P(uj)={devj,ilike+ui,devj,idislike+ui,ui>uui<u(4.5)
从而得到两极SlopeOne方案,实现用户对物品的评分计算如下图所示。
PbpSl(u)j=∑i∈Slike(u)−{j}cj,ilike+∑i∈Sdislike(u)−{j}cj,idislike∑i∈Slike(u)−{j}pj,ilikecj,ilike+∑i∈Sdislike(u)−{j}pj,idislikecj,idislike(4.6)
