一、简介
前面介绍了redis主从复制和redis哨兵模式,它们能在一定程度上提高系统的稳定性,但是当数据量比较大的时候,单个主节点压力可能会过于太大,这个时候可以考虑将redis集群部署,本文将详细介绍redis集群搭建的详细过程。
二、redis集群介绍
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。
Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.
Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令.
Redis 集群的优势:
- 自动分割数据到不同的节点上。
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
三、Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
四、Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了
不过当B和B1 都失败后,集群是不可用的.
五、搭建并使用Redis集群
注意,这里使用的是redis5.0.7,好像redis5.0之后不需要使用ruby环境搭建集群了,直接使用redis-cli也可以搭建。
【a】准备环境
根据官网可知redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。要让集群正常运作至少需要三个主节点,不过在刚开始试用集群功能时, 强烈建议使用六个节点: 其中三个为主节点, 而其余三个则是各个主节点的从节点,所以我们以3主3从模型搭建redis集群。
这里以虚拟机启动多个redis服务模拟伪分布式redis集群,端口号分别为:
192.168.8.130:6379
192.168.8.130:6380
192.168.8.130:6381
192.168.8.130:6382
192.168.8.130:6383
192.168.8.130:6384模型图大体如下:

【b】配置多个redis.conf配置文件,用于启动多个redis服务
首先,我们复制六份redis.conf,名字分别为:redis6379.conf、redis6380.conf、redis6381.conf、redis6382.conf、redis6383.conf、redis6384.conf
cp redis.conf redis6379.conf
cp redis.conf redis6380.conf
cp redis.conf redis6381.conf
cp redis.conf redis6382.conf
cp redis.conf redis6383.conf
cp redis.conf redis6384.conf
【c】修改配置文件
依次修改下面几项地方:这里以修改redis6380.conf为例子,其他几个配置文件依次类推。
- (1). 端口号
port 6380![]()
- (2). 关闭保护模式
protected-mode no![]()
- (3). 修改IP绑定为0.0.0.0
bind 0.0.0.0![]()
- (4). rdb文件名称
dbfilename "dump6380.rdb"![]()
- (5). aof文件名称
appendfilename "appendonly6380.aof"- (6). pid进程管道文件名称
pidfile "/var/run/redis_6380.pid"![]()
- (7). 日志文件名称
logfile "redis6380.log"
- (8). 打开集群开关
cluster-enabled yes
- (9).集群节点配置文件
cluster-config-file nodes-6380.conf
- (10).集群节点超时时间
cluster-node-timeout 15000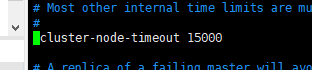
【d】依次启动6个redis服务
redis-server ../etc/redis6379.conf
redis-server ../etc/redis6380.conf
redis-server ../etc/redis6381.conf
redis-server ../etc/redis6382.conf
redis-server ../etc/redis6383.conf
redis-server ../etc/redis6384.conf
查看redis服务是否启动成功:
ps -ef | grep redis【e】创建集群
redis-cli --cluster create 192.168.8.130:6379 192.168.8.130:6380 192.168.8.130:6381 192.168.8.130:6382 192.168.8.130:6383 192.168.8.130:6384 --cluster-replicas 1使用上面的命令创建集群,参数说明:
--cluster-replicas 1:希望为集群中的每个主节点创建一个从节点
192.168.8.130:6379 192.168.8.130:6380 192.168.8.130:6381 192.168.8.130:6382 192.168.8.130:6383 192.168.8.130:6384:集群实例的地址列表启动实例时可能会报下面的错误:

这是因为集群中的redis可能存在数据或者存在rdb、aof持久化文件的原因,解决方法就是清除数据以及删除跟配置文件同一级目录存在的.rdb、.aof、nodes.conf文件。

【f】然后继续执行创建集群的语句:

redis打印出一份预想中的配置给你看, 如果没问题, 就可以输入 yes, redis-cli就会将这份配置应用到集群当中,让各个节点开始互相通讯。
不过很不幸的是,这个时候又给我报了另外一个错误如下:
[ERR] Not all 16384 slots are covered by nodes. 
说明16384个槽没有全部覆盖到所有节点上面,slots分布不正确,解决方法如下:
- (1). 第一步:修复集群
redis-cli --cluster fix 192.168.8.130:6379- (2). 第二步:修复完成后再用check命令检查下是否正确
只要输入任意集群中节点即可,会自动检查所有相关节点
redis-cli --cluster check 192.168.8.130:6379- (3). 第三步:重新分配slot
redis-cli --cluster reshard 192.168.8.130:6379通过上面的命令重新分配之后,slot就正常了。
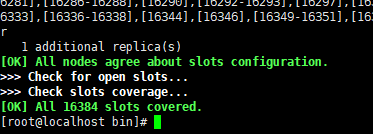
【g】测试集群
首先登录集群中任意一台redis客户端,然后测试一下。
redis-cli -p 6379 -c
ping
set k1 v1
set k2 v2
set k3 v3
set k4 v4
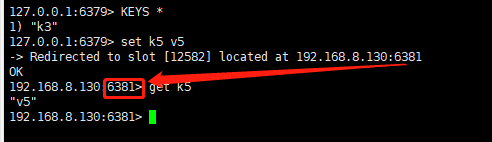
如上图,添加一个key被分配到6381节点上,注意连接的端口变为了6381。
接着,我们打印集群的信息:
CLUSTER INFO当然也可以使用命令 cluster nodes 列出集群当前已知的所有节点( node),以及这些节点的相关信息。好了,上面已经成功搭建了一个redis集群,下面我们看看如何添加主节点、从节点以及删除节点。
六、添加主节点
【a】准备配置文件redis6385.conf
cd /usr/local/redis-5.0.7/etc/
cp redis6384.conf redis6385.conf【b】修改配置文件,这跟之前修改的地方都一样,这里不再详细说明,下面是需要进行修改的地方:
port 6385
protected-mode no
pidfile "/var/run/redis_6385.pid"
logfile "6385.log"
dbfilename "dump6385.rdb"
appendfilename "appendonly6385.aof"
cluster-config-file nodes-6385.conf
cluster-node-timeout 15000
cluster-enabled yes
bind 0.0.0.0【c】启动redis 6385服务:
redis-server ../etc/redis6385.conf
ps -ef | grep redis
【d】添加主节点到集群中
redis-cli --cluster add-node 192.168.8.130:6385 192.168.8.130:6379参数说明:
192.168.8.130:6385:新节点的地址
192.168.8.130:6379:集群中任意一个已经存在的节点的IP和端口使用上面的命令就可以将192.168.8.130:6385服务添加到之前的集群中。

【e】登录redis客户端查看集群节点信息
redis-cli -p 6379 -c
CLUSTER NODES![]()
可见,新节点6385没有包含任何数据, 因为它没有包含任何哈希槽。所以我们需要将集群中的某些哈希桶移动到新节点里面, 新节点就会成为真正的主节点。
【f】重新分配slot
./redis-cli --cluster reshard 192.168.8.130:6379 
 继续查看集群节点信息:
继续查看集群节点信息:
CLUSTER NODES![]()
可见,6385服务成功分配了slot哈希槽。
七、添加从节点
【a】准备配置文件
cp redis6385.conf redis6386.conf
vim redis6386.conf【b】修改配置文件
port 6386
pidfile "/var/run/redis_6386.pid"
logfile "6386.log"
dbfilename "dump6386.rdb"
appendfilename "appendonly6386.aof"
cluster-config-file nodes-6386.conf
cluster-enabled yes
cluster-node-timeout 15000【c】启动redis6386服务:
redis-server ../etc/redis6386.conf
ps -ef | grep redis
【d】添加从节点到集群中
redis-cli --cluster add-node 192.168.8.130:6386 192.168.8.130:6379 --cluster-slave注意后面有 --cluster-slave参数
参数说明:
192.168.8.130:6386:新节点的地址
192.168.8.130:6379:集群中任意一个已经存在的节点的IP和端口
可见,成功将6386从节点加入到集群中。当然如果想指定添加的从节点在某个主节点下的话,可以使用下面的命令:
redis-cli --cluster add-node 192.168.8.130:6386 192.168.8.130:6379 --cluster-slave --cluster-master-id 主节点ID注意配置:--cluster-master-id 主节点ID
八、删除集群节点
redis-cli --cluster del-node 192.168.8.130:6379 40d83a1b6284f4cd5e9c30cddf1de936ccc18a2参数说明:
192.168.8.130:6379:集群中任意一个已经存在的节点的IP和端口
40d83a1b6284f4cd5e9c30cddf1de936ccc18a2:想移除的节点ID九、集群相关操作命令
redis-cli --cluster helpCluster Manager Commands:
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
check host:port
--cluster-search-multiple-owners
info host:port
fix host:port
--cluster-search-multiple-owners
reshard host:port
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
rebalance host:port
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg>
--cluster-simulate
--cluster-pipeline <arg>
--cluster-threshold <arg>
--cluster-replace
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
del-node host:port node_id
call host:port command arg arg .. arg
set-timeout host:port milliseconds
import host:port
--cluster-from <arg>
--cluster-copy
--cluster-replace
help 十、总结
下面总结三个需要注意的问题:
- 【a】集群是如何判断是否有某个节点挂掉
首先要说的是,每一个节点都存有这个集群所有主节点以及从节点的信息。它们之间通过互相的ping-pong判断是否节点可以连接上。如果有一半以上的节点去ping一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的备用节点。
- 【b】集群进入fail状态的必要条件
A、某个主节点和所有从节点全部挂掉,我们集群就进入faill状态。
B、如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态.
C、如果集群任意master挂掉,且当前master没有slave.集群进入fail状态
- 【c】 集群中的主从复制
集群中的每个节点都有1个至N个复制品,其中一个为主节点,其余的为从节点,如果主节点下线了,集群就会把这个主节点的一个从节点设置为新的主节点继续工作,这样集群就不会因为一个主节点的下线而无法正常工作。
注意:
- 1、如果某一个主节点和他所有的从节点都下线的话,redis集群就会停止工作了。redis集群不保证数据的强一致性,在特定的情况下,redis集群会丢失已经被执行过的写命令。
- 2、使用异步复制(asynchronous replication)是redis 集群可能会丢失写命令的其中一个原因,有时候由于网络原因,如果网络断开时间太长,redis集群就会启用新的主节点,之前发给主节点的数据就会丢失
至此,我们成功搭建了一个redis集群,以上都是笔者实际搭建时的一些总结,如果不当之处,还望及时指正~,希望能对小伙伴们的学习有所帮助。
参考资料:
