五、 优化Sql语句
上一章讲了如何设计一张好的表,一张好的表自然需要好的sql语句去操作它。本章就来聊聊如何优化sql语句。
1. Sql语句优化原则
优化需要优化的Query
定位优化对象性能瓶颈
从Explain入手
尽可能在索引中完成排序
只取自己需要的Column
尽可能避免复杂的join和子查询
2. 优化limit
- select * from test1 order by id limit 99999,10
原语句虽然使用了id索引,但是相当于从第一行定位到99999行再去扫描后10行,相当于扫描全表
如果改为- select * from test1 where id>=100000 order by id limit 10
则直接定位到100000查找
3. 尽量避免SELECT *命令
4. 不让排序
在使用group by 分组查询时,默认分组后,还会排序,可能会降低速度.
比如:
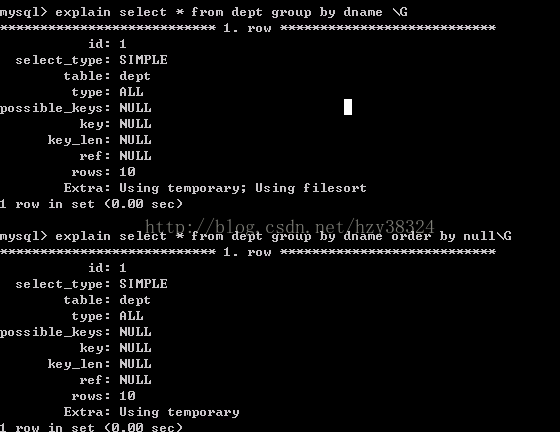
在group by后面增加 order by null 就可以防止排序.
5. 使用连接来替代子查询
有些情况下,可以使用连接来替代子查询。因为使用join,MySQL不需要在内存中创建临时表。
[糟糕的效率]
- select * from sales2 where company_id not in(select id from company2)
[简单处理方式]
- select * from dept, emp where dept.deptno=emp.deptno;
[左外连接,效率最高]
- select * from dept left join emp on dept.deptno=emp.deptno;
6. 利用LIMIT 1取得唯一行
有时,当你要查询一张表是,你知道自己只需要看一行。在这种情况下,增加一个LIMIT 1会令你的查询更加有效。这样数据库引擎发现只有1后将停止扫描,而不是去扫描整个表或索引
7. 使用 EXISTS代替in
EXISTS要远比IN的效率高。里面关系到full table scan和range scan。几乎将所有的IN操作符子查询改写为使用EXISTS的子查询
8. 不要手贱
没有必要时不要用DISTINCT和ORDER BY
这些动作可以改在客户端执行,它们增加了额外的开销