前言
当今技术进步更新十分的块,外界环境的变化对系统服务提出了更高的要求。传统中心集中式的系统服务管理模式越来越暴露出其不足之处,诸如单点瓶颈问题,不可容错等等。因此分布式的且具有高容错性的服务设计理念应运而生。分布式的服务设计意味着其中会涉及到不同服务之间的通信协调,但同时分布式的服务部署在一定层面带来了更高的系统容错度。本文笔者来讨论一种基于状态机方法构建的分布式容错服务。当今许多成熟的分布式系统都带有部分其中的设计理念。
状态机理论和系统容错性的关联
粗一看文章标题,可能有同学会比较好奇,状态机理论和系统容错性设计到底有哪些关联之处呢?
简单地来做个解释,系统容错性的一个关键点在于说系统服务要具有多个状态完全一致的服务copy。当当前的系统服务出错了,可以随时从备选的copy服务中挑选一个继续提供服务。概括地来说,系统容错性的核心点在于系统具有多实例备份的设计,而多实例服务的核心点又在于各个服务拷贝之间状态的一致性。而这个一致性要求,就和我们本文所提到的状态机理论就有相关性了。
我们可以运用状态机的一些方法,来构建状态一致性的多系统服务拷贝。下面我们来了解了解状态机理论的一些内容。
状态机理论
状态机,英文名称为State Machine,在状态机理论中,有以下一些概念的定义:
- State,状态
- Input,输入
- Output,输出
- 状态转化方法,Input × State → State
- 输出方法,Input × State → Output
- 初始State状态
从上面的概念定义中,我们可以看到里面出现频率最高的词是State,一切都是围绕State展开进行的。在状态机中,一个初始状态经过一次输入转变为下一个状态,同时产生了一个输出内容。当多份初始状态一致的状态机,在经过完全相同、顺序也相同的的Input处理后,将会转变到最终一致的状态,同时将会产生相同的Output内容。
将这套状态机理论应用到高容错性服务设计之中,我们可以以下一些概念转换:
当各服务拷贝状态出现不一致情况时,意味着部分系统发生了错误的情况。这个不一致指某服务状态与大多数其它服务State不一致的时候。
这里我们通常说的“大多数”指的是半数以上。
状态机方法论的实际应用
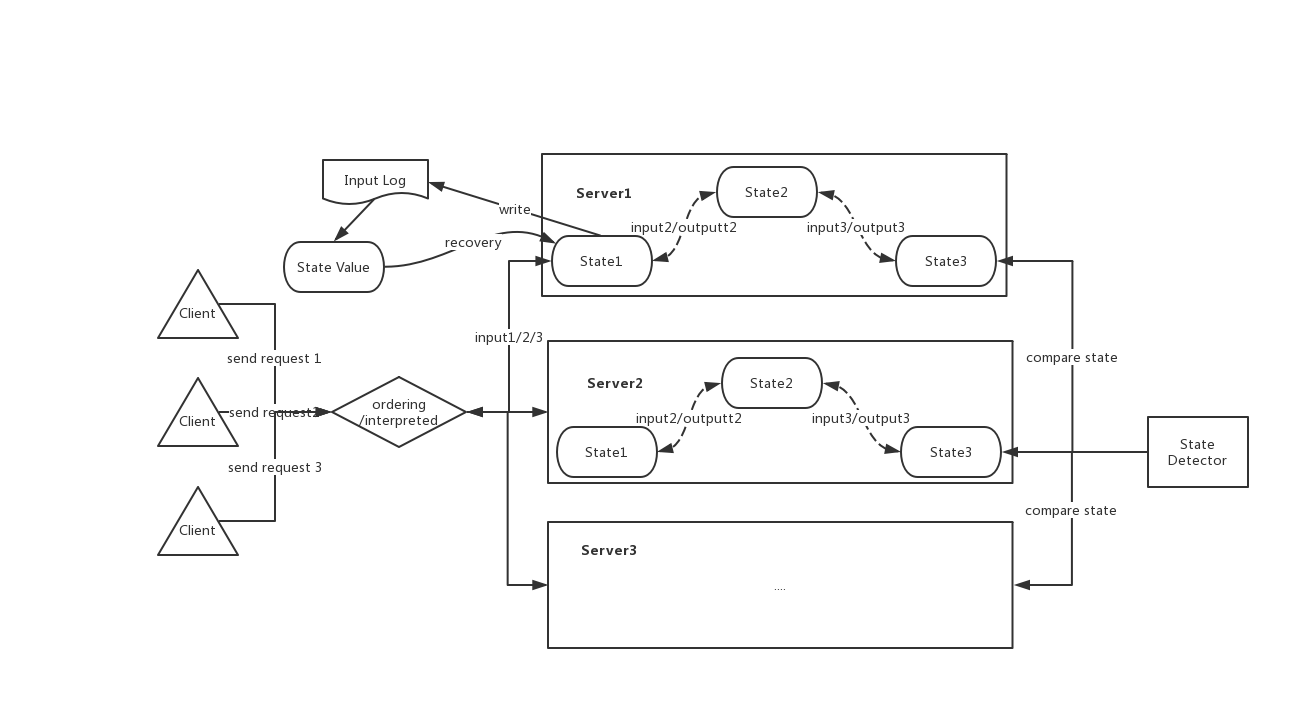
下面我们来聊聊状态机方法论的实际应用,看看它是如何应用在独立,多服务容错性系统设计之中的。在这个方法论里,总共可分为6个子步骤:
- 1)布置初始状态一致的状态机在各个独立的服务拷贝中
- 2)服务接受客户端请求,将其解析为状态机的Input
- 3)定义上述Input的执行顺序
- 4)按照步骤3)定好的顺序,让服务中的状态机执行Input
- 5)返回客户端状态机执行的Output内容作为response
- 6)监控检测服务拷贝间的状态的差异
下面我们一一来对上述部分子步骤进行分析。
步骤3在上述6个步骤中是最为关键的步骤,对于Input排序来说,这里面要求各个状态机之间进行投票协议约定,来达成一致性。
状态机的错误恢复
在上述过程中,有时难免会发生部分状态机实例发生错误现象,为了能够让此状态机能再次恢复到最新状态,我们需要保存历史Input Log作为恢复时使用。如上文所提到的,初始状态一致的状态机在经过相同顺序,相同的Input处理后,会达到最终一致的状态。
但是保存历史所有的Input Log会导致消耗大量的存储空间以及可能的长时间恢复耗时,这里我们会有checkpoint的操作,来定期保存当前状态以及移除掉过去无效的Input Log数据。HDFS的checkpoint机值本质上也是此方法的一个理论实现。
以下是基于状态机的流程处理过程图:
其实回过头来看状态机理论,在当前很多成熟的分布式系统内部或多或少都有其理论原理的体现,比如请求一致性处理,状态一致性检测等等。
