前言
对于大部分使用HDFS作为大数据存储系统的用户而言,NameNode的启动过程缓慢已经可以算是一个十分痛点的问题。尤其是当NN的元数据规模达到数亿万级别时,这个过程总的耗时时间将会达到几小时的级别。这意味着什么呢?这意味着假设当系统因为异常退出时,再次恢复服务需要至少等超过1个小时以上。最近社区完成了一个重要的改进,benchmark结果显示可以让NN加载时间提速将近1倍,本文笔者来聊聊这个重要的改动,相信对于HDFS开发者来说绝对是个意义重大的改进。
HDFS NN的启动过程
在介绍正文之前,先来说说NN的启动加载过程,我们总是说NN启动好慢,那么它到底是慢在什么阶段呢?如果我们想做里面的启动加速,我们首先要知道问题的点在于哪里。
NN的启动过程里面包含了如下几个阶段(从先往后的顺序):
- 1)INode数据的加载
- 2)Editlog的apply
- 3)等待DN的block report,达到block report阈值后,退出Safe Mode模式
在以上3个子过程中,耗时时间排序依次为1)>3)>2)(这里假设是亿万INode规模下),其中1)过程的耗时远远超出2), 3)的执行耗时,可以说这里面主要耗时的过程要属于INode数据的加载了。INode数据的加载耗时最长其实也不难理解,因为这里会有大量的INode对象的解析行为,更为关键的一点是这个过程是单步串行操作的。那么假设我们可以让这个过程从串行的方式变为多步并行的方式,那么是否可以极大地提高NN的启动过程呢?
目前NN串行加载的方式本质上来说是由于其FSImage文件的内部结构所决定的。FSImage内部通过以不同的Section段作为划分,逐段写入每类Section的对象数据。从先往后以此写入INode数据,最后再写入Section的索引,相关控制代码如下:
...
step = new Step(StepType.INODES, filePath);
prog.beginStep(Phase.SAVING_CHECKPOINT, step);
// Count number of non-fatal errors when saving inodes and snapshots.
long numErrors = saveInodes(b);
numErrors += saveSnapshots(b);
prog.endStep(Phase.SAVING_CHECKPOINT, step);
step = new Step(StepType.DELEGATION_TOKENS, filePath);
prog.beginStep(Phase.SAVING_CHECKPOINT, step);
saveSecretManagerSection(b);
prog.endStep(Phase.SAVING_CHECKPOINT, step);
...
private long saveInodes(FileSummary.Builder summary) throws IOException {
FSImageFormatPBINode.Saver saver = new FSImageFormatPBINode.Saver(this,
summary);
// 按照顺序进行Section的写出
saver.serializeINodeSection(sectionOutputStream);
saver.serializeINodeDirectorySection(sectionOutputStream);
saver.serializeFilesUCSection(sectionOutputStream);
return saver.getNumImageErrors();
}
写完每段Section后,更新索引信息:
void serializeINodeSection(OutputStream out) throws IOException {
INodeMap inodesMap = fsn.dir.getINodeMap();
...
// 在每段Section写完之后,更新索引信息
parent.commitSectionAndSubSection(summary,
FSImageFormatProtobuf.SectionName.INODE,
FSImageFormatProtobuf.SectionName.INODE_SUB);
}
这里的Section索引主要包含2个主要变量信息1)Section的offset, 2)Section的长度。随后加载程序根据Section的索引信息,进行指定区间内的Section加载解析。此部分FSImage的内部结构如下所示:
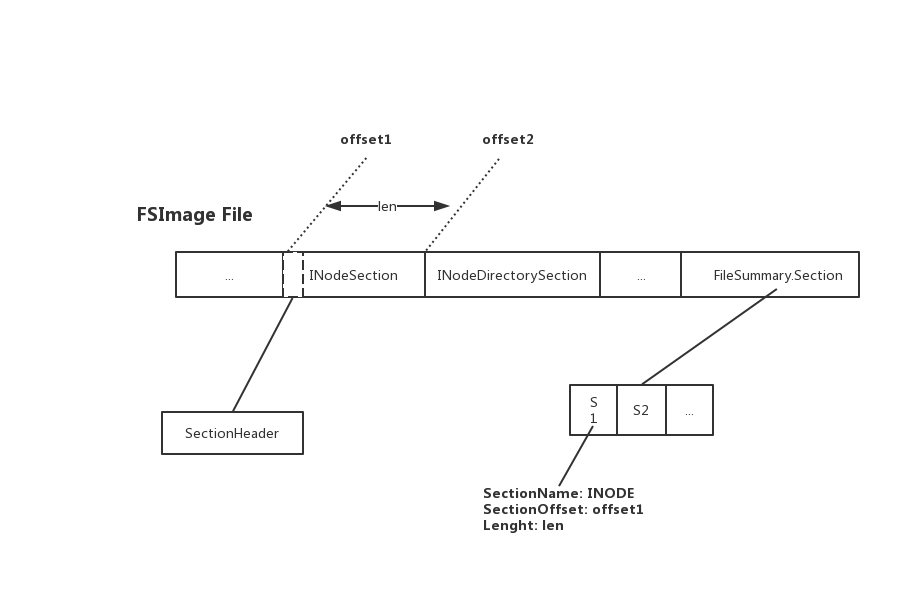
FSImage多索引下的并行加载优化
基于FSImage文件目前的内部结构设计,我们想做优化的并行加载部分其实是中间INodeSection/INodeDirectorySection的部分。但这里FSImage只根据大的Section类型分为了两段,所以如果我们想加速这里面的过程,一种办法是进一步拆分里面大的Section变为内部多个小Sub-Section段,然后更新对应的索引到索引Section内。有了这些额外索引之后,我们就可以启动并行的任务去加载多个索引对应的区间数据,然后坐到真正的并行加载了。因为索引准确记录了每个任务需要加载的offset和对应的length,可以保证加载的绝对精准性。
在加载的时候,我们还可以灵活地设置索引的触发阈值,比如每100w个INode数据建立一个内部索引,如下:
void serializeINodeSection(OutputStream out) throws IOException {
INodeMap inodesMap = fsn.dir.getINodeMap();
...
s.writeDelimitedTo(out);
int i = 0;
Iterator<INodeWithAdditionalFields> iter = inodesMap.getMapIterator();
while (iter.hasNext()) {
INodeWithAdditionalFields n = iter.next();
save(out, n);
++i;
if (i % FSImageFormatProtobuf.Saver.CHECK_CANCEL_INTERVAL == 0) {
context.checkCancelled();
}
// 如果达到内部SubSection阈值,写入索引信息
if (i % parent.getInodesPerSubSection() == 0) {
parent.commitSubSection(summary,
FSImageFormatProtobuf.SectionName.INODE_SUB);
}
}
// 在每段Section写完之后,更新索引信息
parent.commitSectionAndSubSection(summary,
FSImageFormatProtobuf.SectionName.INODE,
FSImageFormatProtobuf.SectionName.INODE_SUB);
}
于是新的FSImage文件内部的组织结构将更新为如下图所示:
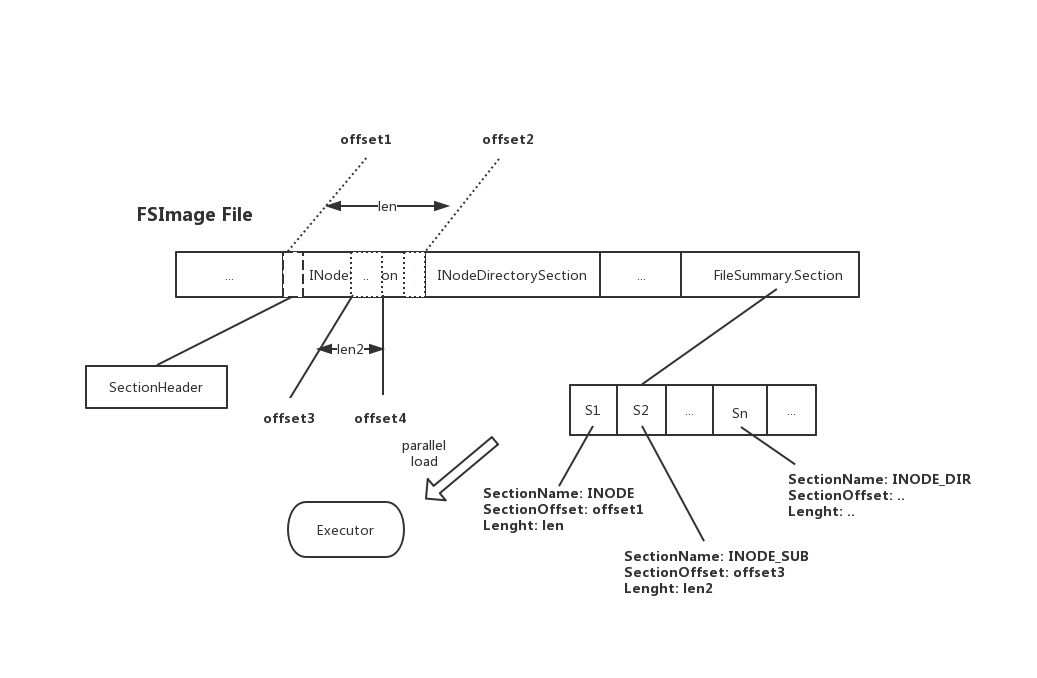
对比原有的FSImage文件格斯,新的FSImage文件中只是在末尾的索引Section中多添加了SUB_SECTION的索引信息,并没有在实质INode Section中添加任何数据,因此它可以保证良好的兼容性。上述INodeSection空格内的虚线即为索引所代表的实际位置。
并行加载的核心逻辑如下:
/**
* INodeSection并行加载核心方法
* @param service 执行线程池
* @param sections Section内部索引
*/
void loadINodeSectionInParallel(ExecutorService service,
ArrayList<FileSummary.Section> sections,
String compressionCodec, StartupProgress prog,
Step currentStep) throws IOException {
LOG.info("Loading the INode section in parallel with {} sub-sections",
sections.size());
long expectedInodes = 0;
CountDownLatch latch = new CountDownLatch(sections.size());
AtomicInteger totalLoaded = new AtomicInteger(0);
final CopyOnWriteArrayList<IOException> exceptions =
new CopyOnWriteArrayList<>();
for (int i=0; i < sections.size(); i++) {
FileSummary.Section s = sections.get(i);
// 1)根据内部索引信息,截取出指定范围内的输入流
InputStream ins = parent.getInputStreamForSection(s, compressionCodec);
if (i == 0) {
// The first inode section has a header which must be processed first
expectedInodes = loadINodeSectionHeader(ins, prog, currentStep);
}
service.submit(() -> {
try {
// 2)提交对应此输入文件的load INode行为操作
totalLoaded.addAndGet(loadINodesInSection(ins, null));
prog.setCount(Phase.LOADING_FSIMAGE, currentStep,
totalLoaded.get());
} catch (Exception e) {
LOG.error("An exception occurred loading INodes in parallel", e);
exceptions.add(new IOException(e));
} finally {
latch.countDown();
try {
ins.close();
} catch (IOException ioe) {
LOG.warn("Failed to close the input stream, ignoring", ioe);
}
}
});
}
try {
latch.await();
} catch (InterruptedException e) {
LOG.info("Interrupted waiting for countdown latch");
}
if (exceptions.size() != 0) {
LOG.error("{} exceptions occurred loading INodes", exceptions.size());
throw exceptions.get(0);
}
// 3)判断总加载数和预期数的比较结果是否相符
if (totalLoaded.get() != expectedInodes) {
throw new IOException("Expected to load "+expectedInodes+" in " +
"parallel, but loaded "+totalLoaded.get()+". The image may " +
"be corrupt.");
}
LOG.info("Completed loading all INode sections. Loaded {} inodes.",
totalLoaded.get());
}
其中根据索引信息截取输入流信息的关键方法如下:
public InputStream getInputStreamForSection(FileSummary.Section section,
String compressionCodec)
throws IOException {
// 1)得到原始FSImage文件输入流
FileInputStream fin = new FileInputStream(filename);
FileChannel channel = fin.getChannel();
// 2)定位到此索引的指定的其实position位置
channel.position(section.getOffset());
// 3)截取offset位置往后length长度是数据作为新的输入流数据
InputStream in = new BufferedInputStream(new LimitInputStream(fin,
section.getLength()));
in = FSImageUtil.wrapInputStreamForCompression(conf,
compressionCodec, in);
// 4)返回截取的输入流数据
return in
}
以上改动来自于社区最新JIRA HDFS-14617上的改进,实现的要点就是通过写入内部索引来支持INode加载的并行化,从而加速NN的启动过程。感兴趣的同学可前往此JIRA链接下进行进一步地了解,甚至可以将其backport到自己的内部分支中。
引用
[1].https://issues.apache.org/jira/browse/HDFS-14617 . Improve fsimage load time by writing sub-sections to the fsimage index
