1.选一个自己感兴趣的主题(所有人不能雷同)。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
一、准备阶段
首先打开广州番禺职业技术学院学校要闻,网址是:http://www.gzpyp.edu.cn/pyzyjsxy/xxyw/list.shtml

在这里可以通过审查模式看到第一页的详细信息,而目的则是通过爬取新闻页面的每个新闻的发布方是哪里
环境如下:
python3.6.2 PyCharm
Windows7 第三方库(jieba,wordcloud,bs4,Requests)
(1)首先我是通过利用requests库和BeautifulSoup库,将第2~100页的发每条新闻的发布方全部查找出来且存放在tit.txt种
代码如下:
import requests
from bs4 import BeautifulSoup
# import jieba
for i in range(2,100):
pages = i;
url = 'http://www.gzpyp.edu.cn/pyzyjsxy/xxyw/list_{}.shtml'.format(i)
res = requests.get(url)
res.encoding = 'utf-8'
soup_list = BeautifulSoup(res.text, 'html.parser')
for news in soup_list.find_all('div',class_='list_source'):
print(news.text)
f = open('tit.txt', 'a', encoding='utf-8')
f.write(news.text)
f.close()
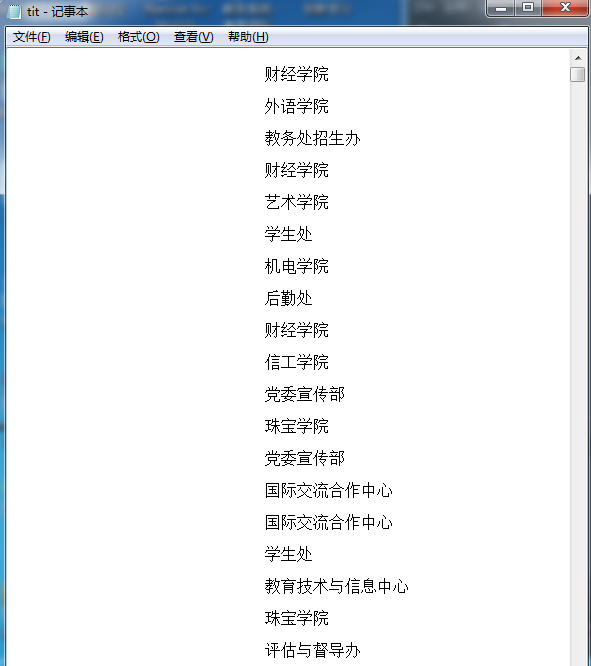
(2)将上述查询到的内容去掉一些不要的符号等,并把它存放到字典里面。
代码实现如下:
def TitleToDict():
f = open("tit.txt", "r", encoding='utf-8')
str = f.read()
my_dict = list(jieba.cut(str))
delete = {" ","、","与","所"}
my_set = set(my_dict) - delete
title_dict = {}
for i in my_set:
title_dict[i] = my_dict.count(i)
return title_dict
(3)统计出现频率最多的20个词组
代码如下:
pgh_dict=TitleToDict()
dictList = list(pgh_dict.items())
dictList.sort(key=lambda x:x[1],reverse=True)
f = open('wordcount.txt', 'a', encoding='utf-8')
for i in range(30):
print(dictList[i])
f.write(dictList[i][0] + ' ' + str(dictList[i][1]) + '\n')
f.close()
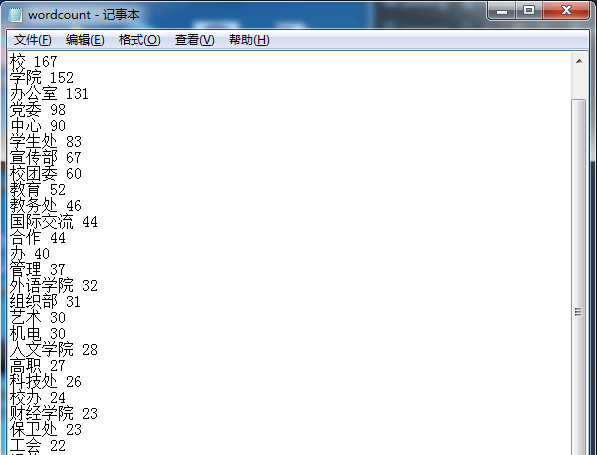
(3)选择一张自己心仪的图片,并将其生成词云
代码实现:
from PIL import Image, ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
font = r'C:\Windows\Fonts\simhei.TTF' # 引入字体
pgh_dict = TitleToDict()
# 读取背景图片
image = Image.open('./timg.jpg')
pgh = np.array(image)
cy = WordCloud(font_path=font, # 设置字体
background_color='White',
mask=pgh, # 设置背景图片,背景是树叶
max_words=200)
cy.generate_from_frequencies(pgh_dict)
image_color = ImageColorGenerator(pgh) # 绘制词云图
plt.imshow(cy)
plt.axis("off")
plt.show()
1、我选择的图片是:

2、生成的词云为:

二、遇到的问题和解决方法:
1.在导入wordcloud这个包的时候,遇到很多问题
首先通过cmd使用pip install wordcloud这个方法进行包的下载,最后会报错误error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: http://landinghub.visualstudio.com/visual-cpp-build-tools
这需要我们去下载VS2017中的工具包,但是网上说文件较大,所以放弃。
之后尝试去https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载whl文件,然后安装。
下载对应的python版本进行安装,如我的就下载wordcloud-1.4.1-cp36-cp36m-win32.whl,wordcloud-1.4.1-cp36-cp36m-win_amd64
两个文件都放到项目目录中,两种文件都尝试安装
通过cd到这个文件的目录中,通过pip install wordcloud-1.4.1-cp36-cp36m-win_amd64,进行导入
但是两个尝试后只有win32的能导入,64位的不支持,所以最后只能将下好的wordcloud放到项目lib中,在Pycharm中import wordcloud,最后成功
三、源代码如下:
import requests
from bs4 import BeautifulSoup
import jieba
for i in range(2,100):
pages = i;
url = 'http://www.gzpyp.edu.cn/pyzyjsxy/xxyw/list_{}.shtml'.format(i)
res = requests.get(url)
res.encoding = 'utf-8'
soup_list = BeautifulSoup(res.text, 'html.parser')
for news in soup_list.find_all('div',class_='list_source'):
print(news.text)
f = open('tit.txt', 'a', encoding='utf-8')
f.write(news.text)
f.close()
def TitleToDict():
f = open("tit.txt", "r", encoding='utf-8')
str = f.read()
my_dict = list(jieba.cut(str))
delete = {" ","、","与","所"}
my_set = set(my_dict) - delete
title_dict = {}
for i in my_set:
title_dict[i] = my_dict.count(i)
return title_dict
pgh_dict=TitleToDict()
dictList = list(pgh_dict.items())
dictList.sort(key=lambda x:x[1],reverse=True)
f = open('wordcount.txt', 'a', encoding='utf-8')
for i in range(30):
print(dictList[i])
f.write(dictList[i][0] + ' ' + str(dictList[i][1]) + '\n')
f.close()
from PIL import Image, ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
font = r'C:\Windows\Fonts\simhei.TTF' # 引入字体
pgh_dict = TitleToDict()
# 读取背景图片
image = Image.open('./timg.jpg')
pgh = np.array(image)
cy = WordCloud(font_path=font, # 设置字体
background_color='White',
mask=pgh, # 设置背景图片,背景是树叶
max_words=200)
cy.generate_from_frequencies(pgh_dict)
image_color = ImageColorGenerator(pgh) # 绘制词云图
plt.imshow(cy)
plt.axis("off")
plt.show()