数据分类/组处理
groupby() 分组函数
分组之后必聚合,只对数字的列聚合
单列进行分组
data.groupby(“attack_range”).mean()[“hp_max”]
使用列表进行多条件分组
data.groupby([“attack_range”,“role_main”]).mean()[“hp_max”]
对不同列求不同的聚合指标
gp = data.groupby([“attack_range”])
gp.agg({“hp_max”:“mean”,“mp_max”:“min”})
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值/
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同的组得到的结果合并起来
数据处理的核心: - groupby()函数
- groups属性查看分组情况
练习:

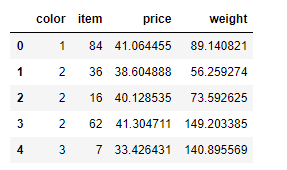
data = DataFrame(data={
"item":np.random.randint(0,100,size=(100)),
"color":np.random.randint(1,4,size=(100)),
"weight":np.random.random(size=100)*100 + 50,
"price":np.random.random(size=100)*40 + 10
})
data.head()
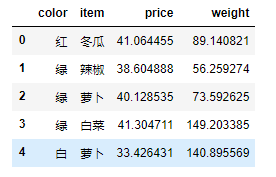
定义一个函数
def map_item(x):
if x < 25:
return "萝卜"
elif x < 50:
return "辣椒"
elif x < 75:
return "白菜"
else:
return "冬瓜"
data.item = data.item.map(map_item)
data.head()
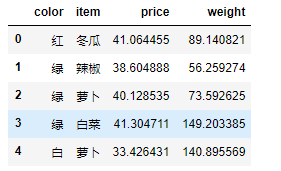
第二种方式:使用字典方式
color_dic = {
1:"红",
2:"绿",
3:"白"
}
data.color = data.color.map(color_dic)
data.head()
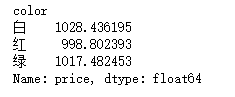
data.groupby("color").sum()["price"]
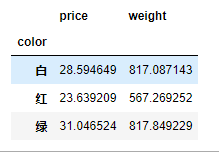
data.groupby(["item","color"]).agg({"price":"mean","weight":"sum"}).loc["萝卜"]
高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby(‘item’)[‘price’].sum() <==> df.groupby(‘item’)[‘price’].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传函数即可
- transform和apply也可以传入一个lambda表达式
注意 - transform 会自动匹配列索引返回值,不去重
- apply 会根据分组情况返回值,去重
交叉表
交叉表(cross-tabulation, 简称crosstab)是一种用于计算分组频率的特殊透视表。
eg:
a = np.array(["foo", "foo", "foo", "foo", "bar", "bar",
"bar", "bar", "foo", "foo", "foo"], dtype=object)
b = np.array(["one", "one", "one", "two", "one", "one",
"one", "two", "two", "two", "one"], dtype=object)
c = np.array(["dull", "dull", "shiny", "dull", "dull", "shiny",
"shiny", "dull", "shiny", "shiny", "shiny"],
dtype=object)
pd.crosstab(a, [b, c])
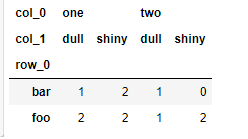
交叉表是一个特殊的透视表
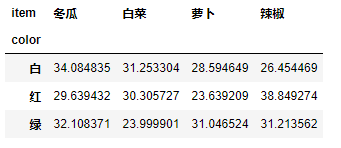
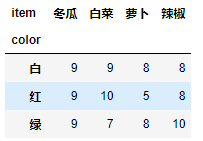
data.groupby([“color”,“item”]).count()[“price”].unstack(level=-1)
透视表
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上得分组建将数据分配到各个矩形区域中。在Python和pandas中,可以通过本章所介绍的groupby功能以及(能够利用层次化索引的)DataFrame有一个pivot_table方法,此外还有一个顶级的pandas.pivot_table函数。除了能为groupby提供便利之外,pivot_table还可以添加分项小计(也叫margins)。
特殊的分组表(多条件的分组)
data.groupby(["color","item"]).mean()["price"].unstack()
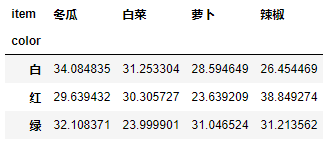
pd.pivot_table(data=data, values="price", index="color", columns="item")