WWDC 2018 session 408: ++Building Faster in Xcode++
引言
这个session主要讲的是如何在Xcode中构建的更快。基于不同的项目本身的配置及复杂性,有很多机会可以让您对其进行改造。在某些情况下,可以显著的提高您的构建内容的运行情况。接下来会从两个不同的角度来提高Xcode的构建速度。一是提升您的整理构建效率;二是减少您在构建中需要做的工作,尤其是您的增量式构建。
并行您的构建
Xcode通过使用目标来配置您的项目,目标指定了您想构建的输出或者产品。有一些例子是iOS App框架和单元测试,还有另一个信息那就是目标之间的依赖项。Xcode为定义我们的依赖项提供了两种方法。有一种很清楚的方法就是通过目标依赖项阶段(target dependencies phase),另外还有一种隐含的方法就是链接二进制和库阶段(linked binary with libraries phase)。

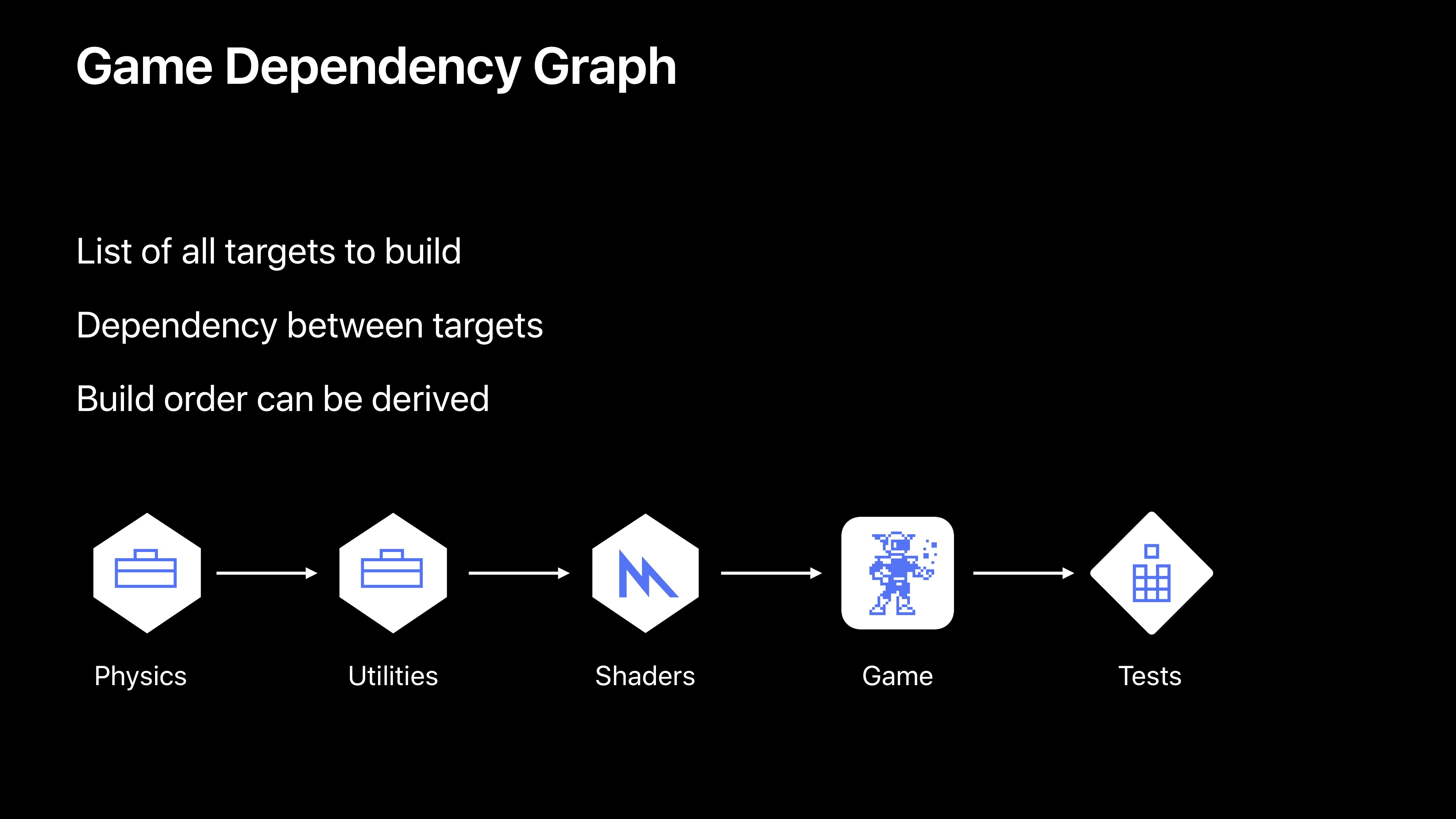
接下来是一个例子,我们将看到这个项目的依赖图。现在这个依赖图只是包含所有目标的清单。
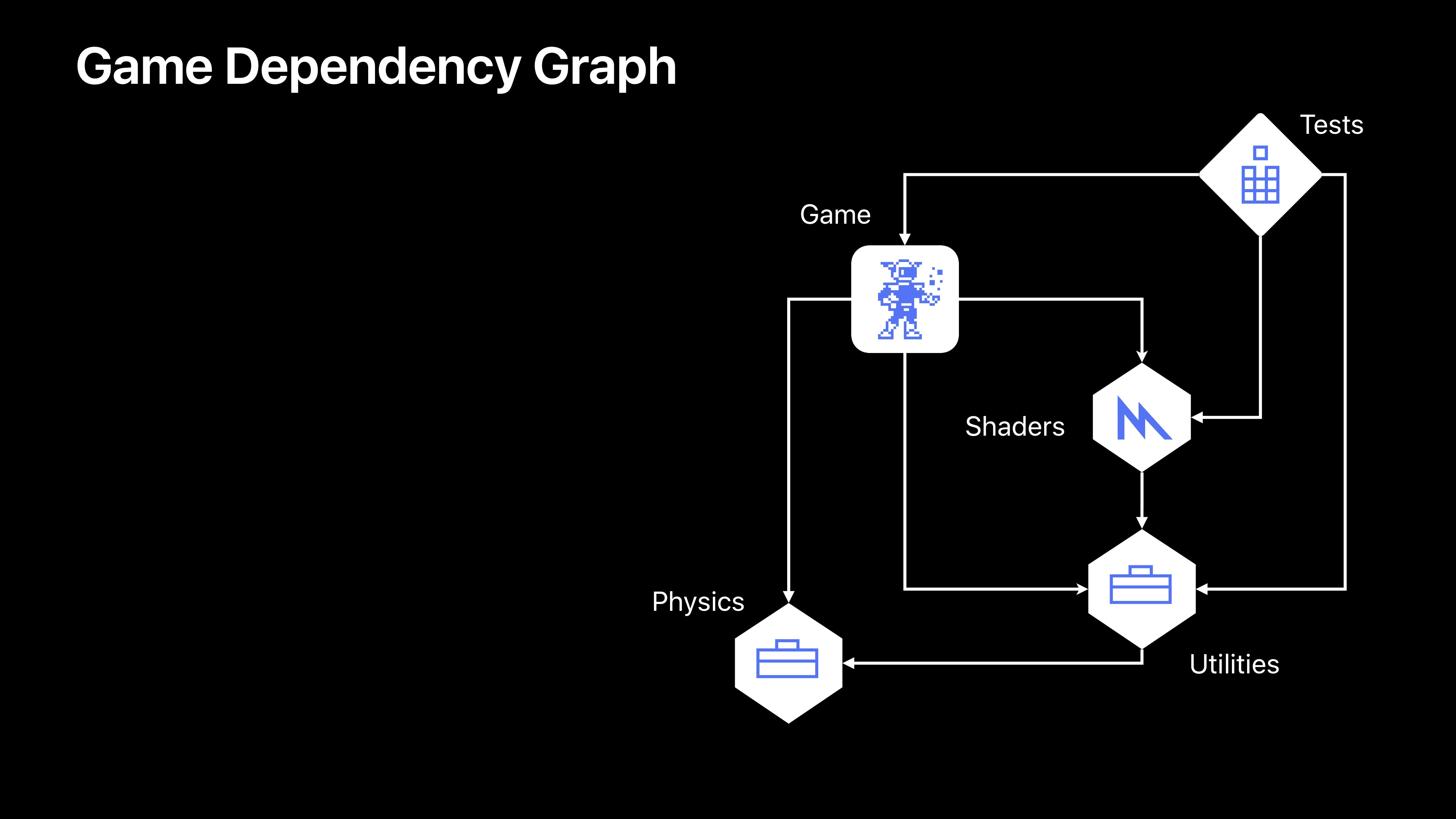
我们可以看到将要构建五个目标,这些目标之间有依赖性信息,基于这两个信息,Xcode可以得到我们的构建次序。
在时间轴上,他们是按照顺序构建的(下图中上方时间轴)。他们都需要等待之前的目标构建完毕,构建时间轴并没有什么错,但是这代表了对潜在硬件资源应用的浪费。尤其是在你有一个如iMac Pro的多核或微核机器是,这对于作为开发者的您来说就是一种时间的浪费。因此我们要采用另一种方法,看了起来大概如图中的下方时间轴。
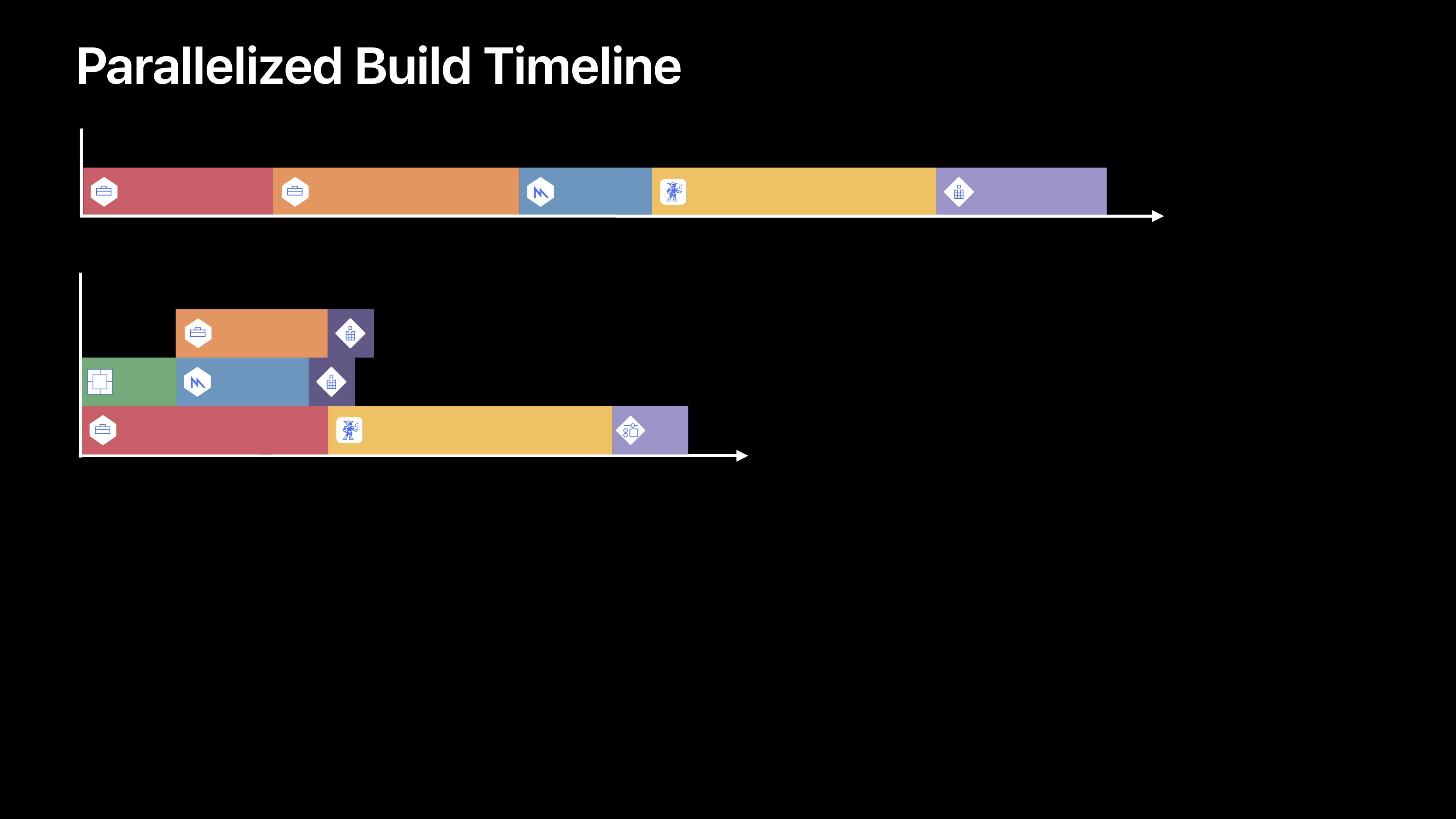
首先,这种环境下我们构建项目中的所做的工作量并没有变化,但是用来构建的时间确缩短了。在这种情况下,时间其实大幅度缩短了。我们可以通过更好的利用可用的硬件来减少构建的时间。
虽然并行是好的,但却不能将所有的任务并行,这是因为依赖信息是项目配置的重要部分,有些依赖是必须有顺序的。所以我们如何从漫长的系列化构建时间线转换为并行的构建时间?
首先,您要确保Xcode被设置并配置成允许我们的目标被平行构建。我们在Scheme Editor中勾选Parallelize Build即可。并行化构建会允许Xcode通过您的目标来使用依赖项信息,这样就可以让其尝试着并行构建您的目标。
其次,我们看下如何配置依赖项。这是通过Build Phase Editor实现的。这里注意一下Link Binary With Libraries,这是你定义所有你想链接到你目标的项目的构建过程阶段。
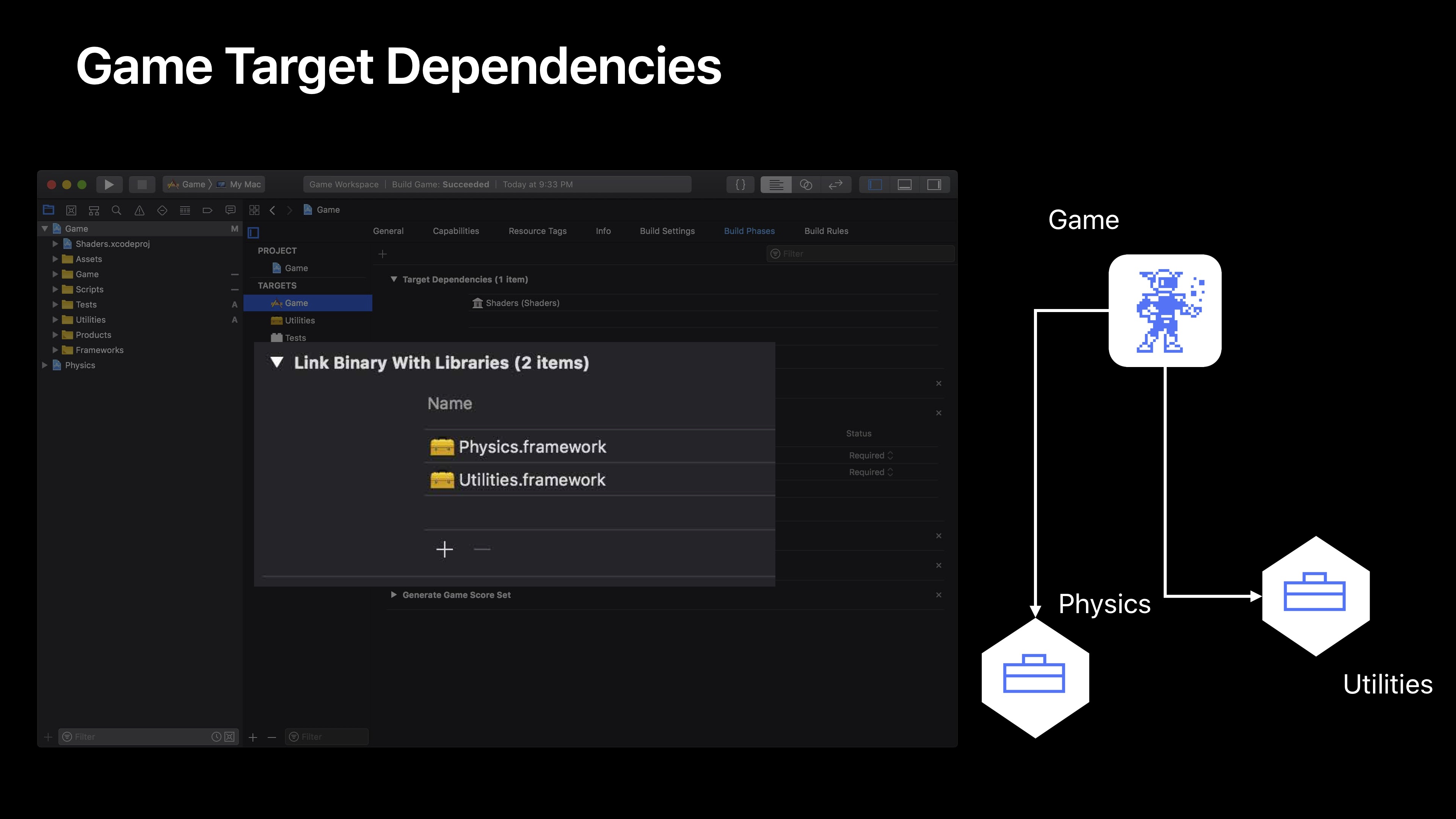
在这个例子下,我们有两个项目Physics.framework和Utilities.framework,这种情况下,Xcode可以在这些目标中创建一个隐式依赖项。如果你在使用自动连接或者其他的LD构建标志来构建设置的话,这些不会暗中在你这里生效。你需要在这个构建阶段或者在目标依赖项的构建阶段横撑一个显式依赖项。

这里我们看到,还有一个名为Shaders的另一个项目,Shaders并不在链接时使用,而是在我们现有的目标中被另一个构建过程使用。很重要的一件事就是我们让Xcode知道,这是一个依赖项而且我们需要等待Shaders完成编辑,并在我们构建现有的目标前就进行构建。于是我们得到了我们的依赖关系。
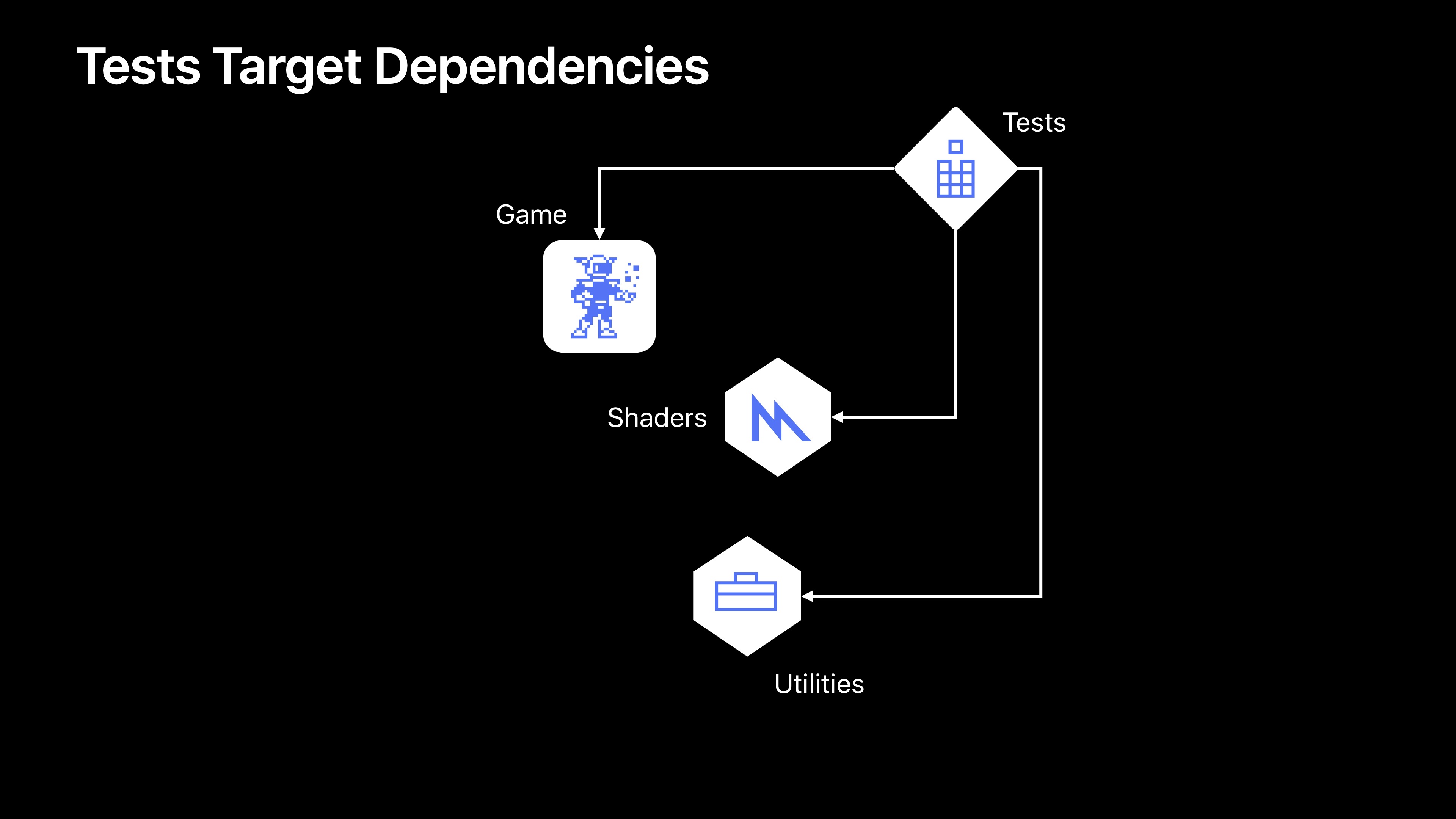
然后我们要将这个序列化的构建过程,变成并行的构建步骤。看下依赖项,我将测试依赖项分成了我想要谈论的三种不同类型。
第一个依赖项,称之为“执行所有操作依赖项”。有一点很清楚,这个测试测试了很多组件(Game、Shaders、Untilities)。在这个例子中,我们最好将测试分解。这样他就能测试每个单独的组件。我们来试试这样操作会怎样。我们在三个依赖项中都被构建了的测试目标现在可以之构建在Game测试中查找的组件,Shaders测试和Utilities测试可以被移出去,与我们其他的目标并行构建。当他们各自的组件Shaders和Utilities完成时即可进行构建。
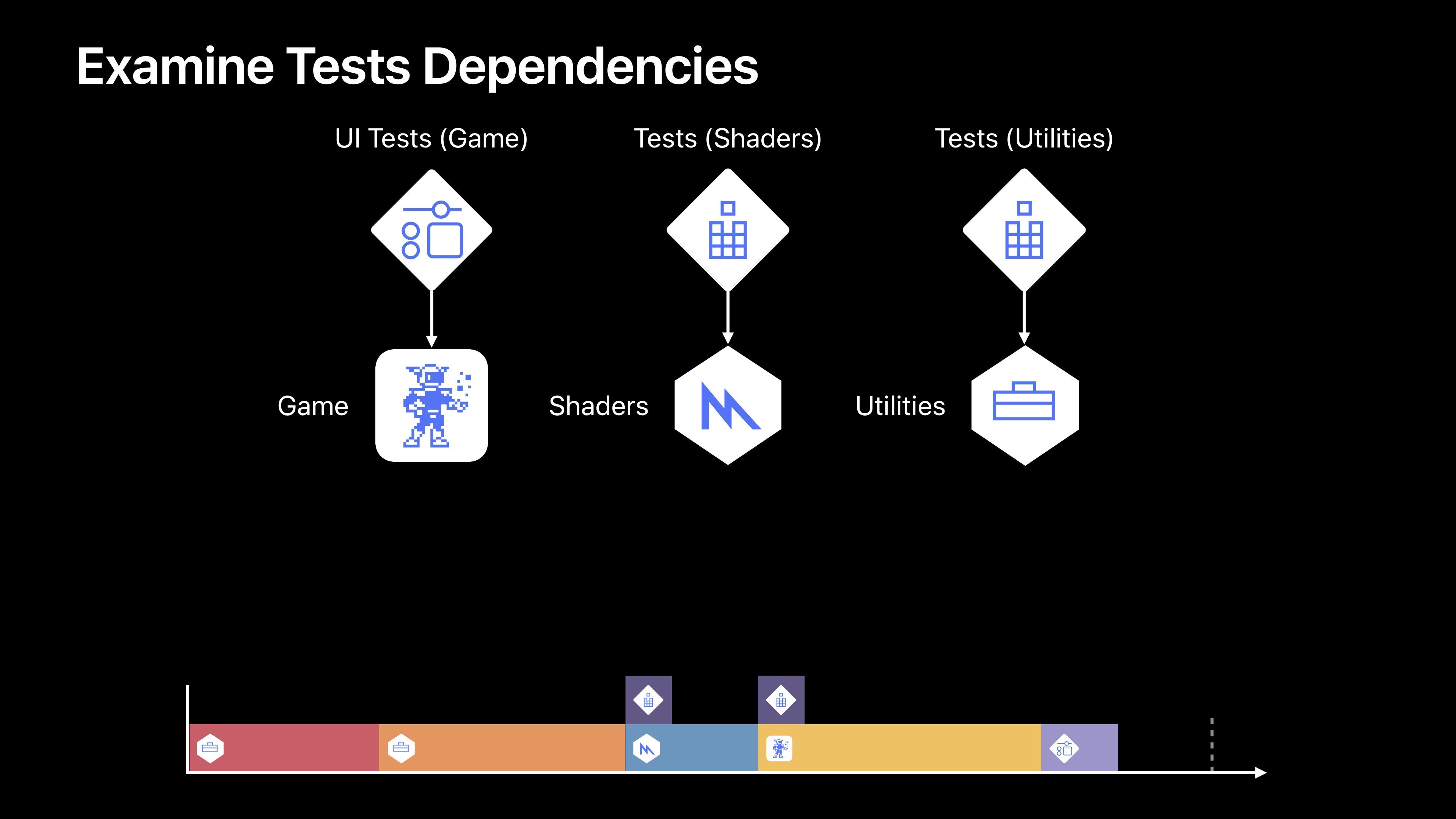
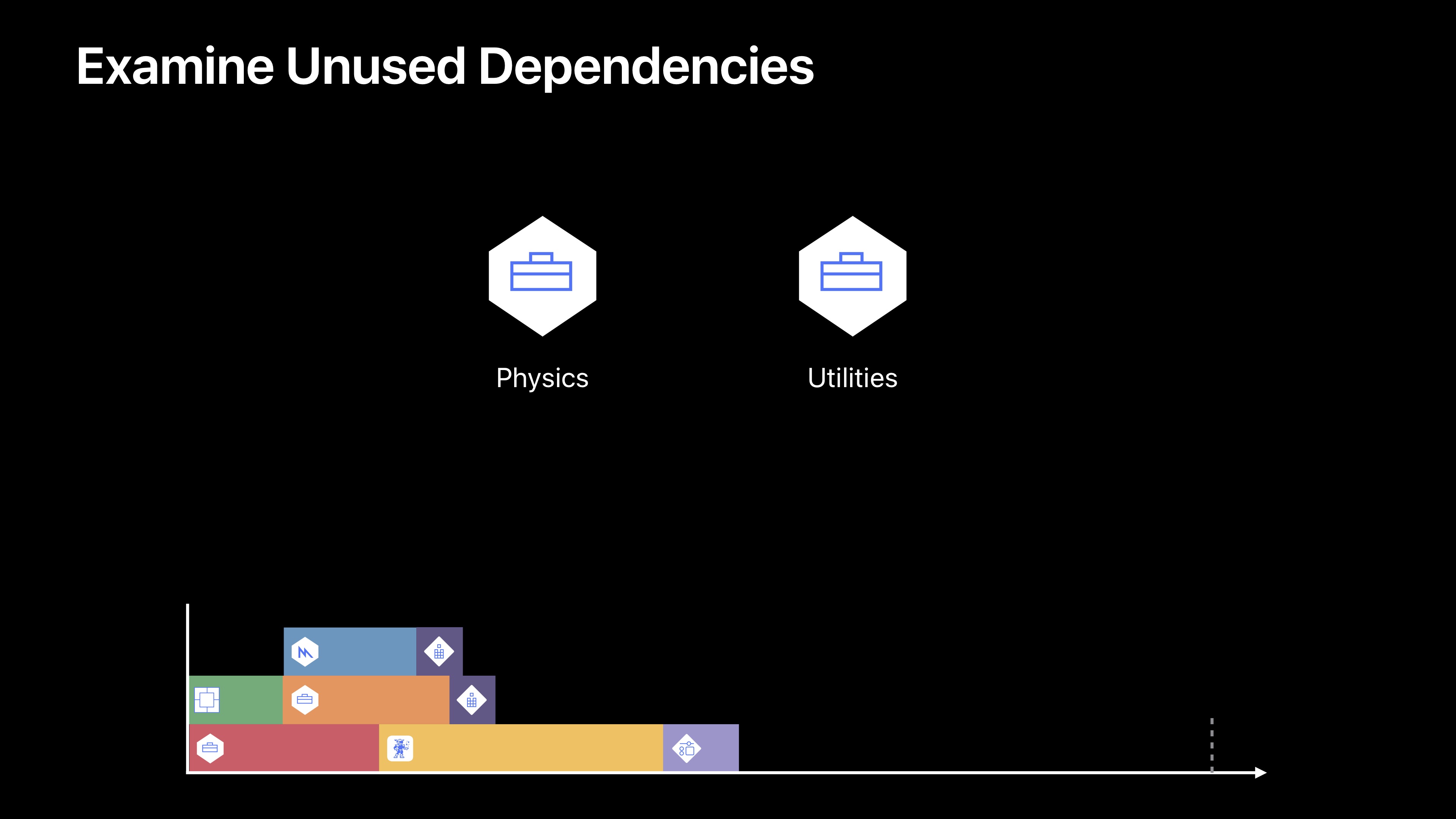
下一类依赖项就是我称之为“爱管闲事的邻居”的依赖项。这个要考虑另一个目标,但是它只需要那个目标的一点,不过它将获取那个目标中的一切。
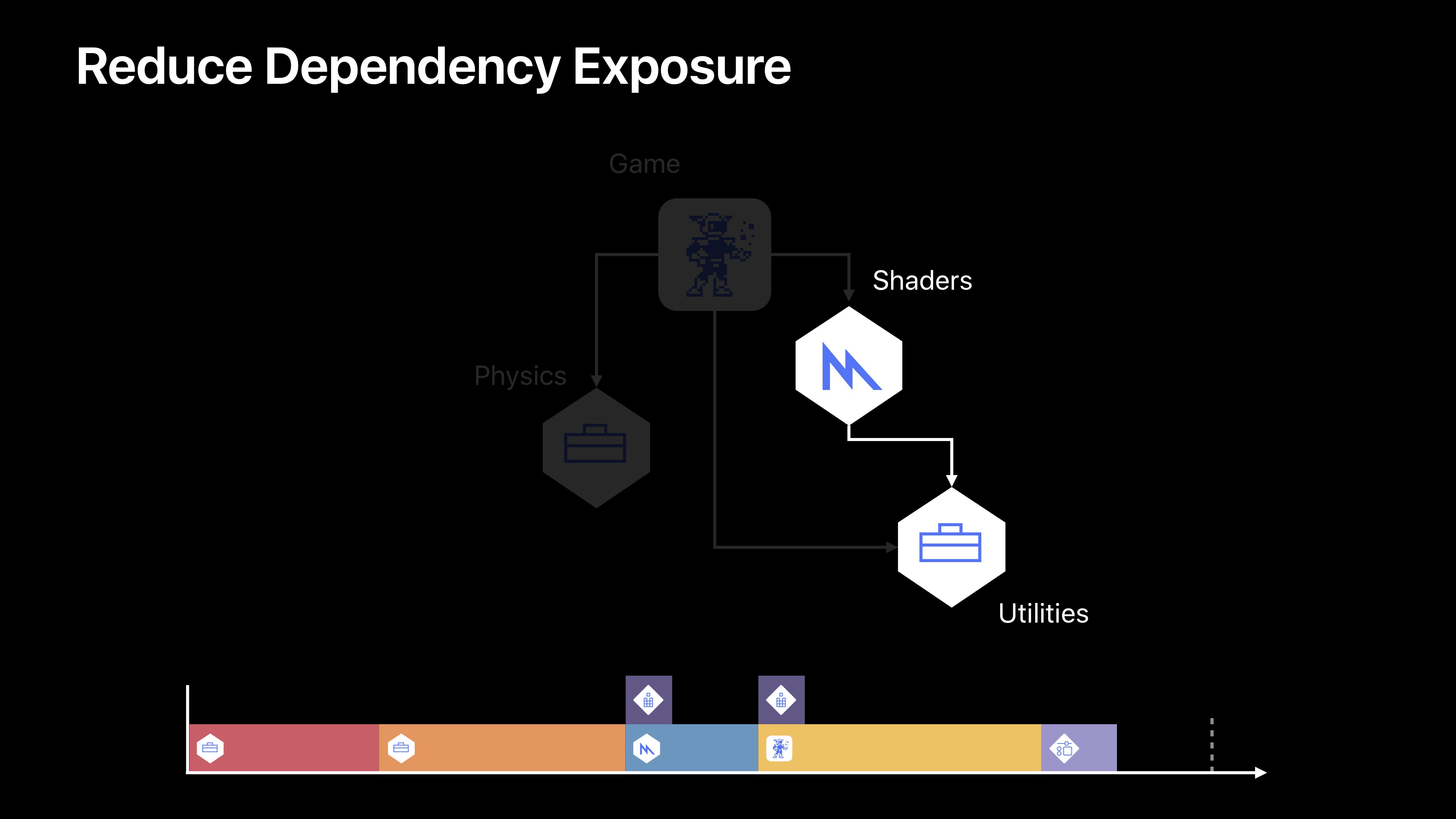
如果我们看一下我们的Game,它对Physics、Shaders、Utilities有一个依赖项。这其实没问题,值得怀疑的是Shaders目标和Utilities目标之间的依赖项。现在我们的Shader目标产生了一个元库。基本上是一组在显卡上运行的GPU代码。我们的Utilities目标生成的则是一个正常的框架。也就是CPU代码。所以已经有一些疑似依赖项了。当我们深入挖掘时,我们会发现Utilities目标实际上有一个构建阶段,该阶段会生成两个目标使用的信息。这样很好,只不过Shaders不再需要从Utilities目标汇总获取任何其他信息了,所以最好将其转入其目标。我们可以看到这个潇潇的增量改变,其实对我们整个的构建时间轴有着巨大的影响。
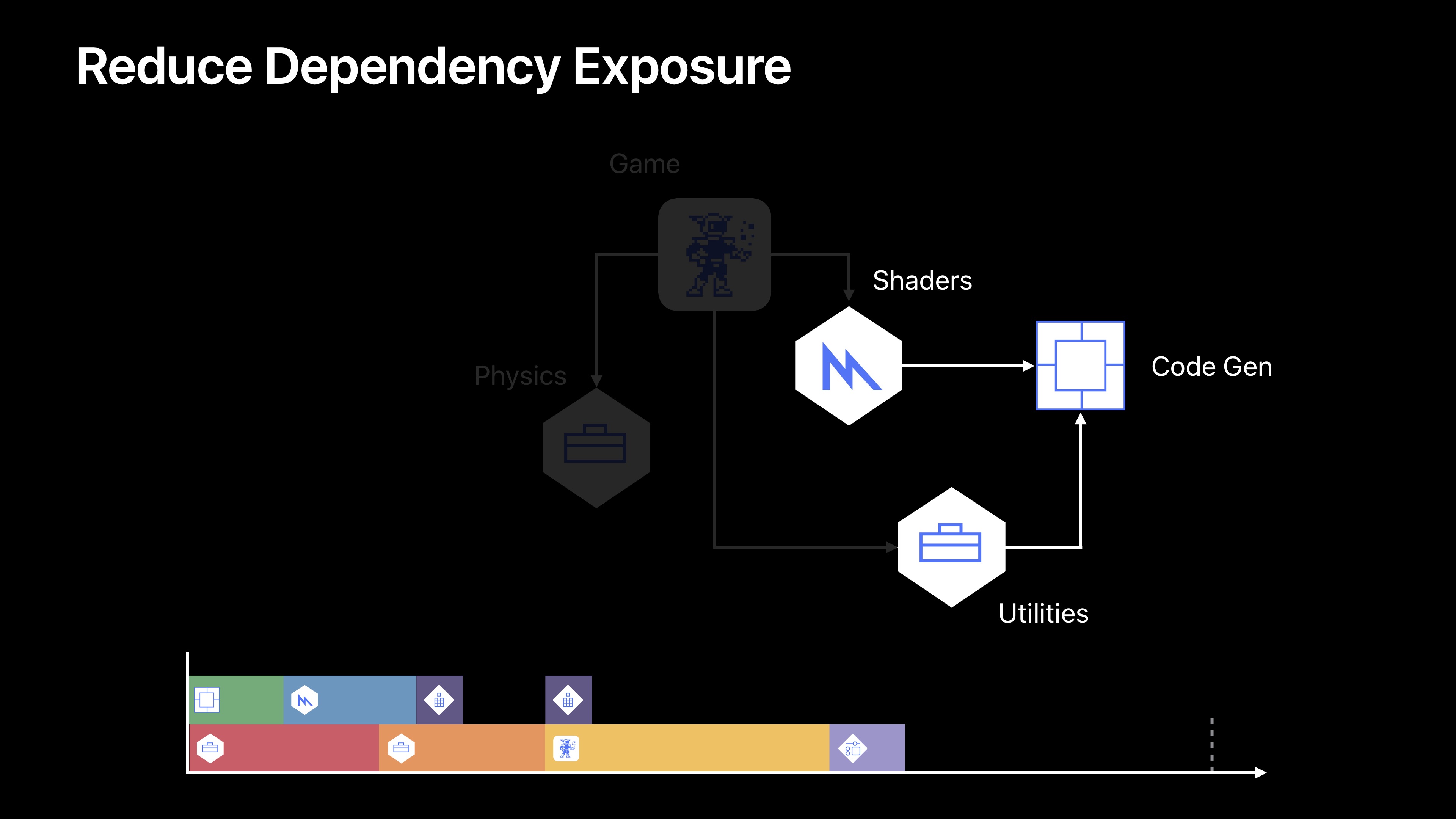
图中的绿色框是我们新的代码目标,现在我们可以缩小我们的实用程序目标,因为我们将其一如到了Code Gen。因为Code Gen没有其他依赖项,它可以移动到我们构建过程的前端,还可以与Physics目标一起并行构建。最后因为Shader不再依赖于Utilities,它不需要等待Utilities和Physics目标的构建。与此相反,一旦Code Gen目标完成后它就能被构建。
最后一类依赖称为“被遗忘项”。在我们的产品或代码的进化或生命周期中,我们需要移动代码并删除了调用,我们得到的仿佛是无作用程序代码。我们的依赖项也会发生这样的事情。我们有时候只是忘记清理他们。在这些情况下,移除该依赖项是比较安全的。
最后一个变化将通过Utilities目标在Code Gen目标之后立马构建,来加强或构件图,而不需要等待Physics目标完成。在Xcode之前版本中,当你构建对其他目标有依赖项目标时,你必须要等待依赖项目标完成他的整体构建过程。在Xcode10中有一个新性能,可以为构建汇总引入一些并行。一旦构建阶段与适合我们编辑的依赖项完成了,我们就可以开始编辑你的目标了。像链接之类的事情可以并行完成。
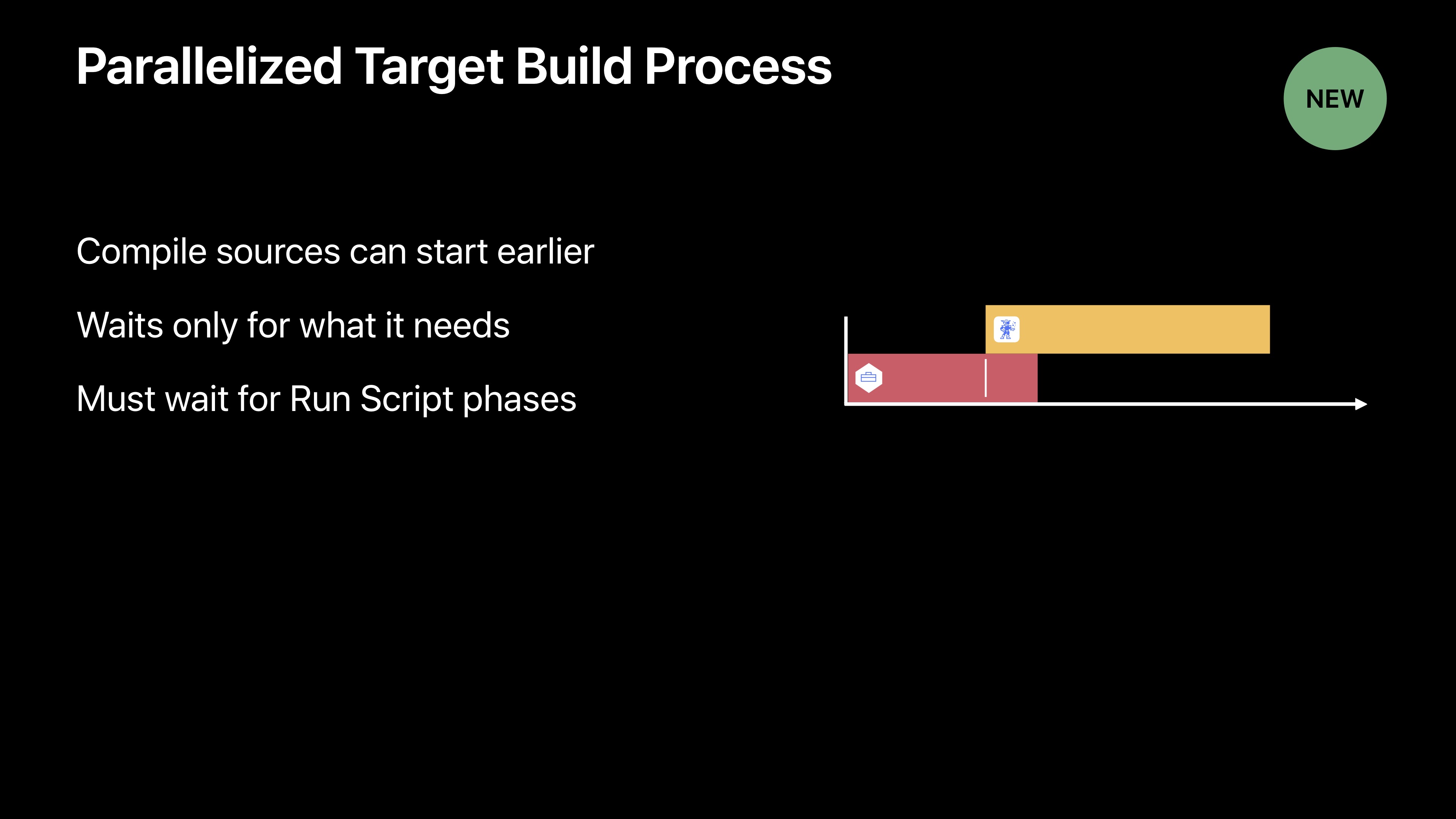
现在如果您运行了一个脚本阶段,这就是一个构建阶段。期间你必须在它利用这些新并行项之前等待依次完成。
运行脚本阶段
运行脚本阶段允许你根据你的需求自定义你的构建过程。接下来看下如何配置。
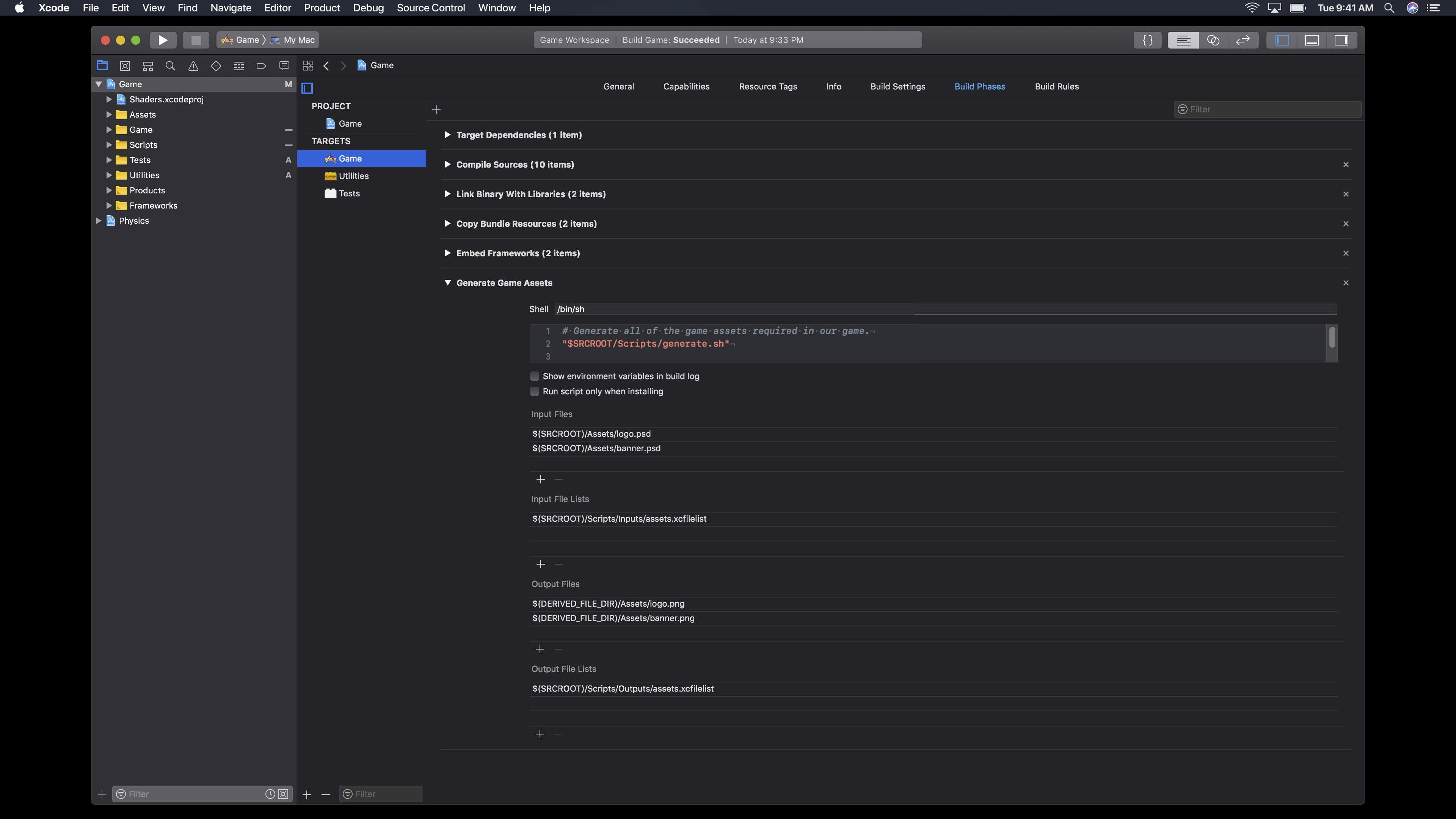
首先最上面,就是你要运行的脚本。Input Files是脚本的输入,这里很重要,Xcode用来决定你的运行脚本是否能成功运行的关键。这里应该包含脚本内容涉及的所有文件。Input File Lists是针对Input Files过多,来设定的,方便维护。文件清单格式如下:
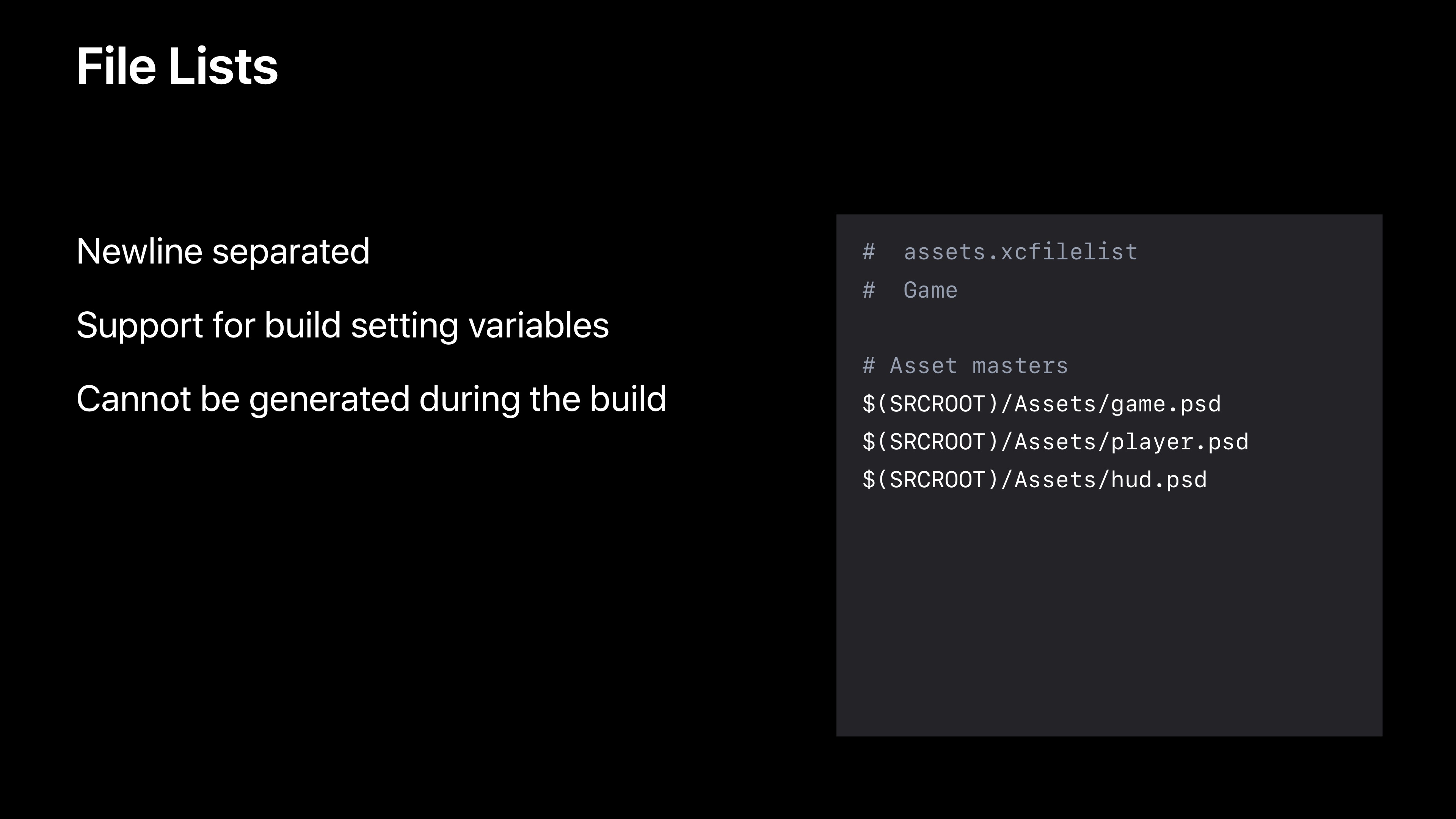
该文件清单不可以在构建过程中修改或生成,在构建开始时,他们就可以读取了,所有信息都被使用了。接下来是Output Files为输出文件,Xcode会根据这些信息,来决定运行脚本阶段您的脚本是否需要运行。当然也可以设置Output File Lists输出文件清单。
Xcode 10还为运行脚本阶段提供了文档。
依赖周期
当你设定你的运行脚本阶段并声明所有新的依赖项,包括你在目标中修改依赖项时,你都可能遇到依赖性周期。依赖周期是一个有着回路的相互依赖的图。在Xcode10中,我们有检测这些周期的更好诊断,同时会告诉你错误,包括扩大该选框获得输入的能力。这些输入是Xcode系统了解的参与了周期系统创建的内容。
其实周期因为一些原因,并不是很好。首先他们代表了你项目中的一个配置问题。其次,他们可能是你项目中虚假重建的来源或者在你的构建过程中获得过时的信息。我们还在依赖周期中更新了一些话题。里面包括了一些常见文件及解决方法。
测量构建时间
在Xcode10中针对这一点,有两个新的功能。第一个就是内嵌任务时间,它可以告诉你每个任务运行的时间。
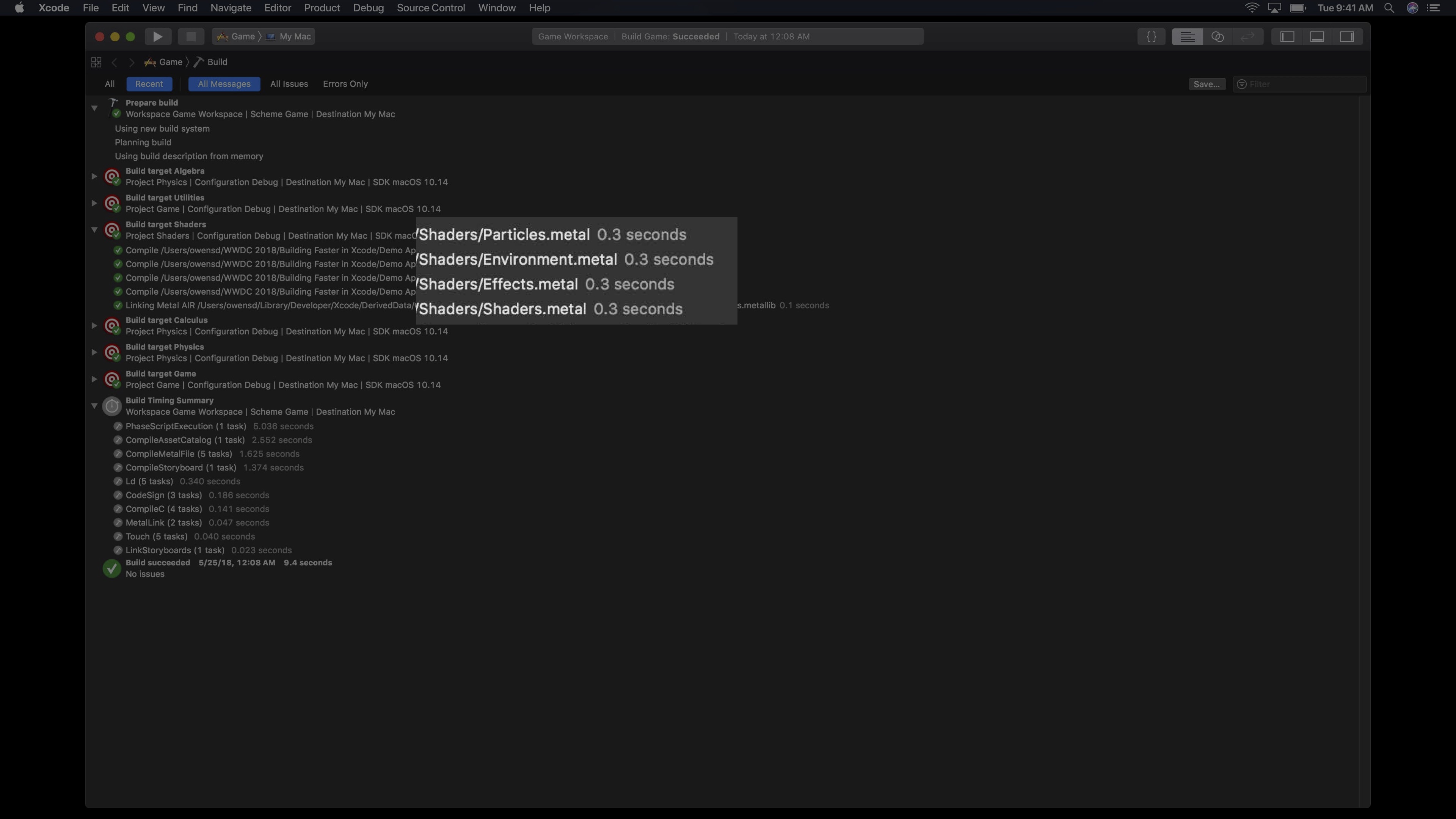
顶部筛选器如果选择的是All,则会展示帮助你创建最终产品整体输出的所有任务。这些往往是你不想看到的,尤其是在增量构建中。那么点击Recent选项,则将会为你展示先前构建运行中的所有构建路径。
Xcode10中另外一个新的特征是一个计时总结。
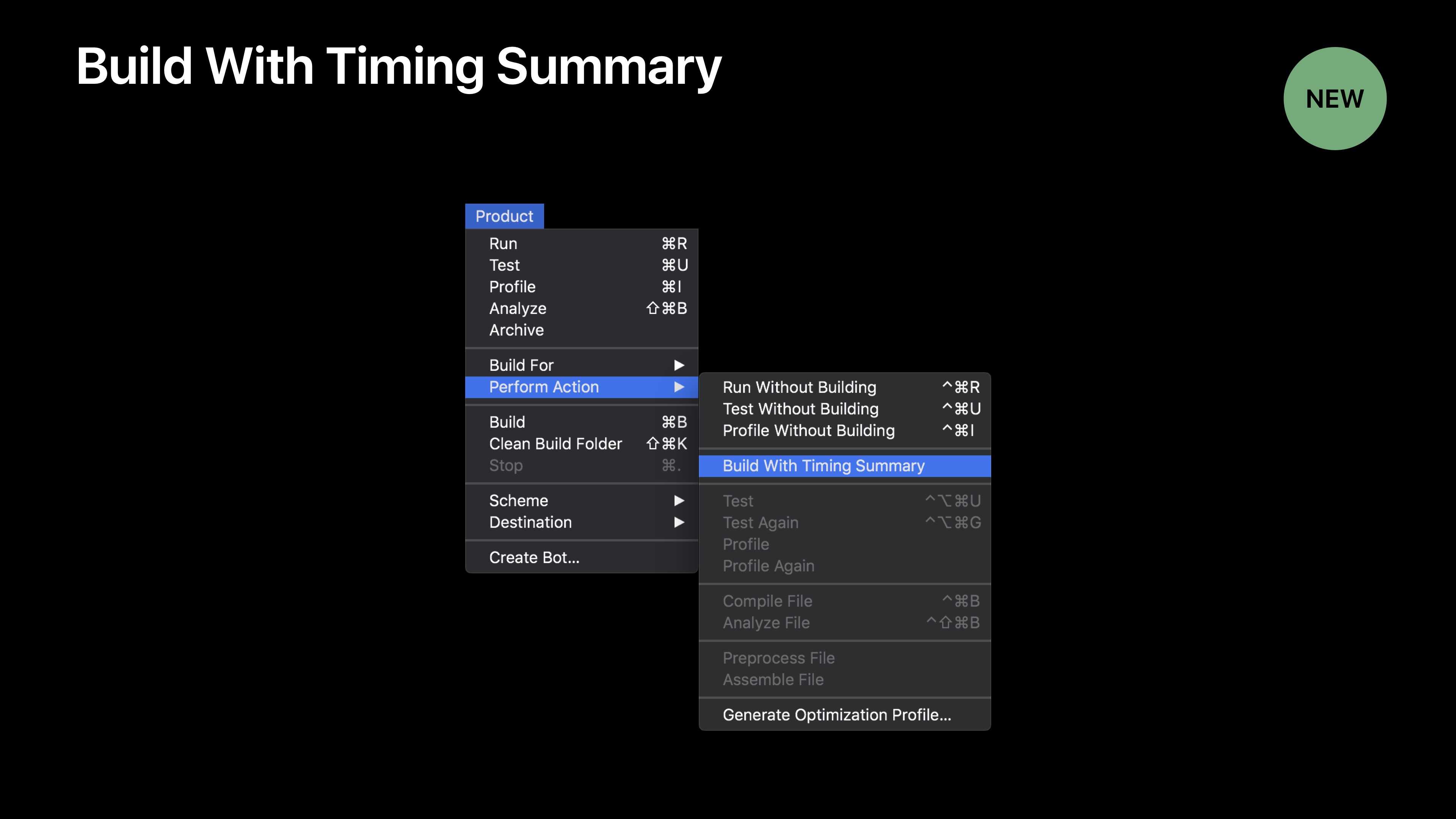
选择Build with Timing Summary后,会在构建日志后得到一个新的日志部分。
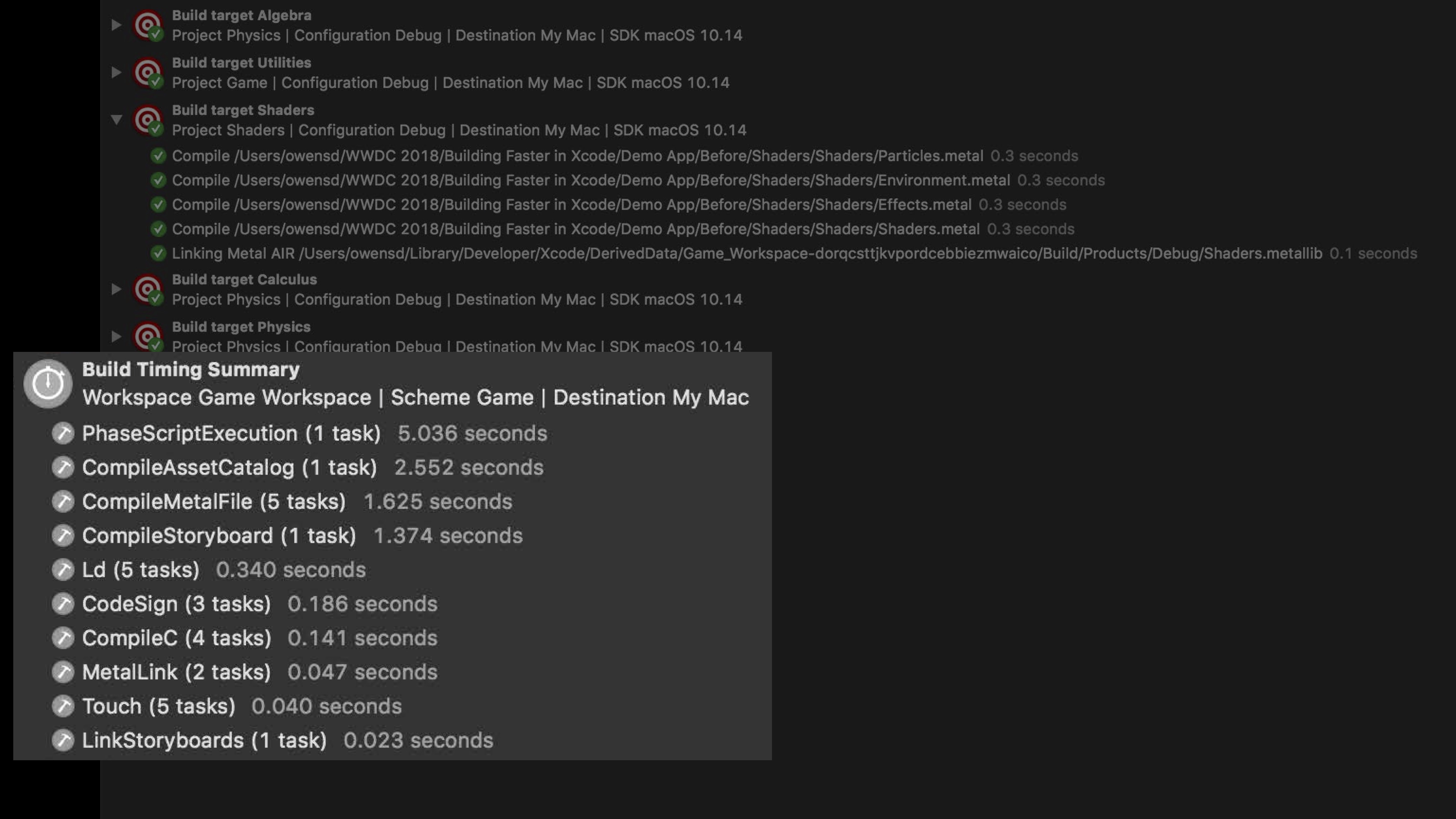
这里会展示你最后构建的操作内所有任务的时间总和。PhaseScriptExecution操作指明花费了5秒钟。如果你在每一个增量构建中都看到这个时间花费,那么这就是你需要为了减少整体构建时间而去要优化的地方。
从命令行输入xcodebuild -showBuildTimingSummary也可以获取构建计时总结。
Whole Module的设置
我们已经通过一系列方法,通过小小的改动就可以提升Xcode项目的构建速度。这里其实还有一个Xcode10的新特性,只不过是一个临时解决方法。如果有很多swift文件时,为了让他们更快的构建,在调试配置中的整理模块设置(Whole Module)。在之前版本的Xocde,开启Whole Module即便是调试模式,也会比在默认增量模式中构建的更快。这确实提升了构建速度。Swift编译器能够以增量模式不可行的方法在不同文件中共享工作。但这也就意味着你每次都要放弃你的增量构建并新建swift的整个文件部分。所以在Xcode10中我们提升了增量构建,让他们也能拥有跨文件共享的工作。因此你不再需要使用整体模式构建,来获得更快的构建时间。所以在调试编译时,删除Whole Module。
处理复杂的表达式
当一个构建花费很长时间时,总会有一个你可以提供给Xcode的用来提升状态的关键信息,所以我们要在复杂Swift表达式语境中先看看它。以下是几个例子
对复杂属性使用显式类型
struct ContrivedExample {
var bigNumber = [4, 3, 2].reduce(1) {
soFar, next in
pow(next, soFar)
}
}
如上面这段代码,这个结构我在各个地方都使用它。拥有一个结构很好,拥有一个有属性的结构很好,拥有一个具有推论数据类型的结构也很好。但是我们在这里推论的表达式有些复杂。例如上面的例子,拥有简化好书和幂函数的大型、复杂表达式,你可能不会猜到结果bigNumber是个double类型。
struct ContrivedExample {
var bigNumber: Double = [4, 3, 2].reduce(1) {
soFar, next in
pow(next, soFar)
}
}
通过在这里提供Double这个信息,节省了编译器使用这个结构在每个文件中需要做的工作。而且其他同事看你的代码也会很直观。
在复杂的闭包中提供类型
func sumNonOptional(i: Int?, j: Int?, k: Int?) -> Int? {
return [i, j, k].reduce(0) {
soFar, next in
soFar != nil && next != nil ? soFar! + next! :
(soFar != nil ? soFar! : (next != nil ? next! : nil))
}
}
这里定义了一个会返回所有非可选参数值的和的函数。如果这三个参数为0,它就会返回0。然后使用了一个Swift的性能,即如果你在主体内有一个拥有单一表达式的闭包,那么编译器会使用该表达式来决定闭包的类型。有时候很方便,但是有时候代码非常的难看懂(上面的例子)。这样还有一个问题,由于这个表达式太大,拥有着很多独立的块,Swift编译器会报错,说它不能在一个合理数量级时间内完成编译,这个构建时间简直慢到家了,连编译器都放弃了。
这里就可以像上一个例子一样做相同的事情,同时提供附加的类型。通过一个闭包,你可以在In Key词之前就完成这些。
func sumNonOptional(i: Int?, j: Int?, k: Int?) -> Int? {
return [i, j, k].reduce(0) {
// edited here
(soFar: Int?, next: Int?) -> Int? in
soFar != nil && next != nil ? soFar! + next! :
(soFar != nil ? soFar! : (next != nil ? next! : nil))
}
}
将复杂的表达式拆开
上个例子,这针对于这个类型的问题,并不是最好的解决办法。可以在这里写一个表达式,这样它就可以用来决定闭包的类型,但是在这种情况下不太必要。我们已经从Reduce的调用中得到了这个闭包是什么样的。Reduce对一个整形可选择的数据调用,这个结果类型需要匹配这个函数的返回类型。我们已经知道Reduce的回调只能对可选择的证书参数操作,这意味着我们不需要在闭包中放上一个表达式。我们可以把它拆分成各自的部分,成为更可读的代码。
func sumNonOptional(i: Int?, j: Int?, k: Int?) -> Int? {
return [i, j, k].reduce(0) {
(soFar: Int?, next: Int?) -> Int? in
// edited here
if let soFar = soFar {
if let next = next { return soFar + next }
return soFar
} else {
return next
}
}
}
这样更容易维护,而且能在一个快速合理的时间内编译。
谨慎使用AnyObject方法和属性
weak var delegate: AnyObject?
func reportSuccess() {
delegate?.myOperationDidSucceed(self)
}
AnyObject这个类型是一个描述所有类实例的便利的类型。不是一个结构体或一个枚举,而是一个类,但是我们不知道是哪一个。不过它还有一个从Objective-C的ID类型传递下来的附加功能,就是可以调用任何方法或者读取其性质。Swift允许你这样做,前提是该方法在项目中是可见的,并展示给了Objective-C运行时。不过这也是有代价的,因为编译器不知道我们要调用哪个类的这个方法,所以它需要检索,任何一个类都可能是你要调用的那个。如果没匹配到,那么就报错。
我们可以更好更全面的描述我们的意图,我们可以定义一个协议。它可以在相同的文件或不同的文件中完成,重要的是一旦我们将委托的性质改成去使用我们的协议,而不是AnyObject,那么编译器就知道在调用的是哪个方法。
weak var delegate: MyOperationDelegate?
func reportSuccess() {
delegate?.myOperationDidSucceed(self)
}
protocol MyOperationDelegate: class {
func myOperationDidSucceed(_ operation: MyOperation)
}
理解Swift的依赖模型
当编译器决定重新编译一个文件时,我们可以通过一些技术来减少编译器的工作量。但是如果完全不重新编译,这些文件会怎么样呢?是什么让编译器决定一个文件是否需要重新编译呢?这就需要我们了解Swift的依赖模型。
Swift的依赖模型是基于文件的,这就有点棘手,因为Swift中没有头文件。我们看到的都是在我们的目标中被默认定义的。
比如上面的例子,我在左侧文件定义了Point,在右侧使用,编译器就会知道我是对第一个声明引入的。
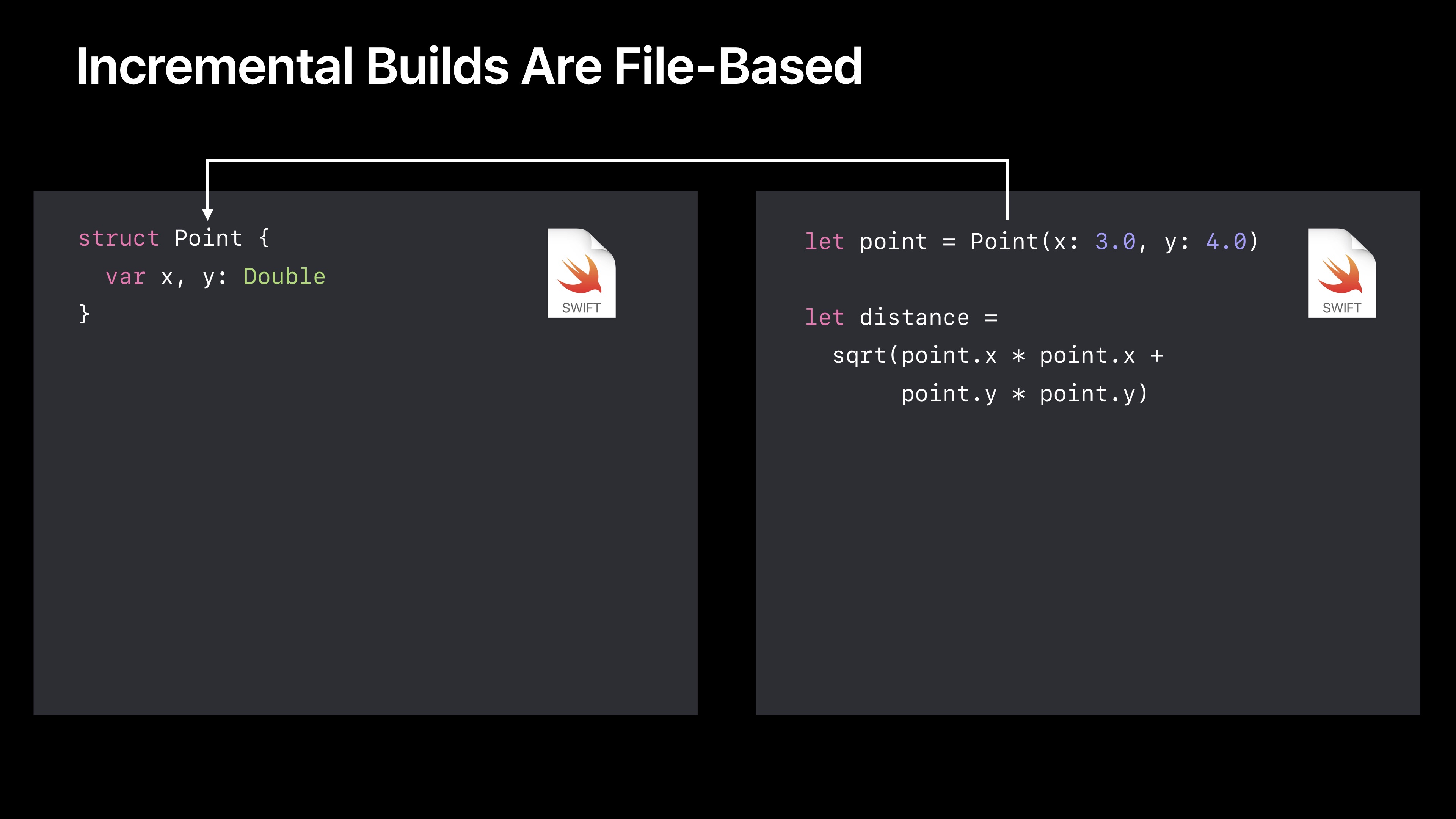
这个文件依赖表示着,如果我改变左边的文件,那么两个文件都需要重新编译。编译器很智能,它能知道你什么时候在一个函数主体中做了修改。
Swift依赖规则
-
编译器必须非常的保守
即使人们知道这个修改不会影响其他文件,但是这不代表编译器就可以知道。
-
函数体的改变不会影响文件的接口
编译器知道如何处理函数体的变化,它知道不会影响接口,所以也不会要气其他文件重新编译
-
模块内的依赖内部每个文件
-
跨目标的依赖项是影响整个目标的(target)
混合开发中限制Objective-C/Swift的接口内容
为了实现这一点,我们先讨论一下混合开发中的一些内容。
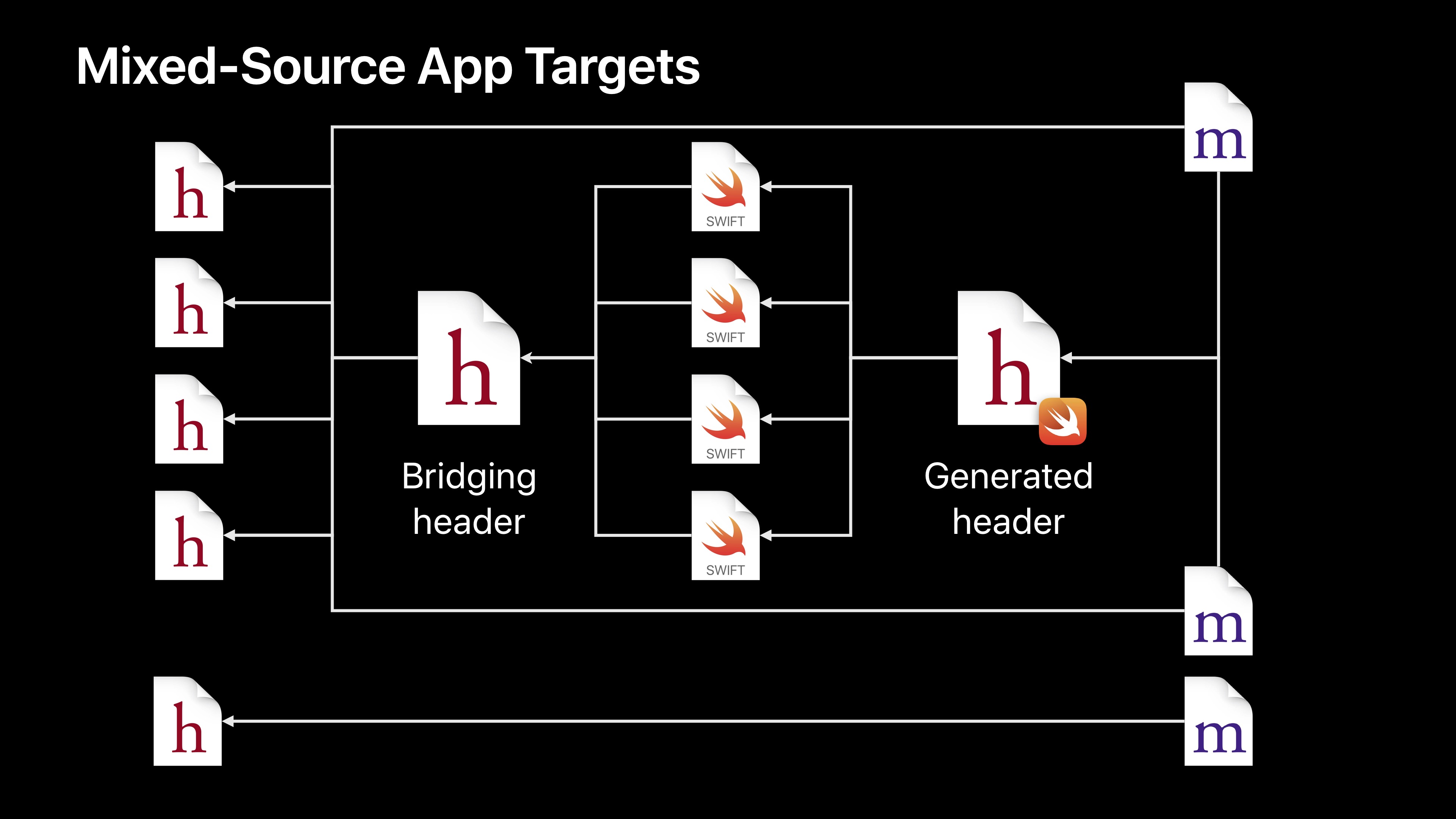
首先最左侧是描述Objective-C接口的头文件,你可能想要把这部分给Swift或者对其他Objective-C部分生命头文件。紧接着往右,桥接头文件,这就是收集你想要展示给你App的Swift部分信息的头文件。这是Xcode中控制头文件使用的构建设置。一旦它设置完成,Swift编译器就知道该把这些Objective-C接口暴露给你的Swift代码。
Swift会接着产生一个生成的头文件(Generated Header),它会反向的做相同的事情。它描述了你的Swift代码中哪些部分会暴露给Objective-C。这个可以在你的Objective-C应用文件中被使用。他们可能会从第一步使用头文件。当然了,你可能拥有不依赖于任何Swift代码的Objective-C代码。这可能不是我们今天在这里要讨论的内容。
所以我们从左到右就有了Objective-C头文件、为了将某些信息接入Swift的桥接头文件、Swift实现文件、将信息送回Objective-C的生成的头文件、Objective-C的实现文件。在像这样的图表中,所有的箭头都代表依赖性。不是目标层面的依赖性,而是目标内的文件间的依赖性。
我们想要做的事关注生成的头文件和桥接头文件。如果我们可以缩小这些头文件的内容,那我们就会知道事情变化的机会其实更少。因此需要重新构建的也更少。对于生成的头文件来说,最有力的工具是私有关键词。

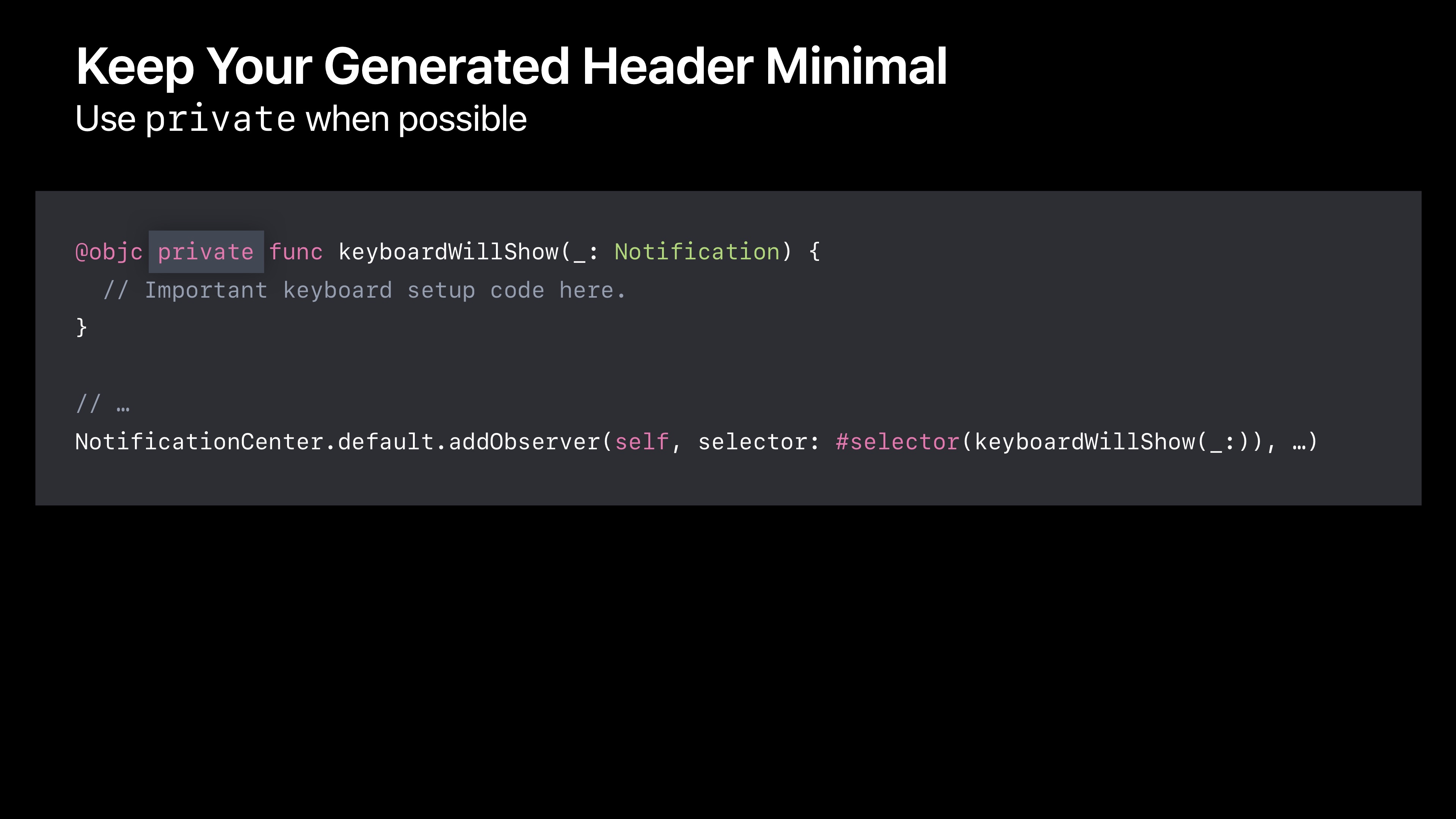
像上面里例子,如果我们在Swift中写了属性和方法,那么会在生成的头文件中自动生成相关的内容。其实如果我们不需要展示给其他文件的话,就可以将不需要展示给其他文件的属性设置为私有。

这样在生成的头文件中也没有相对应的内容了。另外当处理暴露给Objective-C的方法时,以便于Objective-C运行时特征一起使用。如@selector,在这个例子中,使用基础的通知中心API,在通知发送时,使用selector作为回调。这里唯一的要求就是将方法暴露给Objective-C。在我项目中的其他文件中,不论是Swift还是Objective-C,它气死不太被使用,所以我可以把它标记为私有。这样缩小了生成头文件的大小。
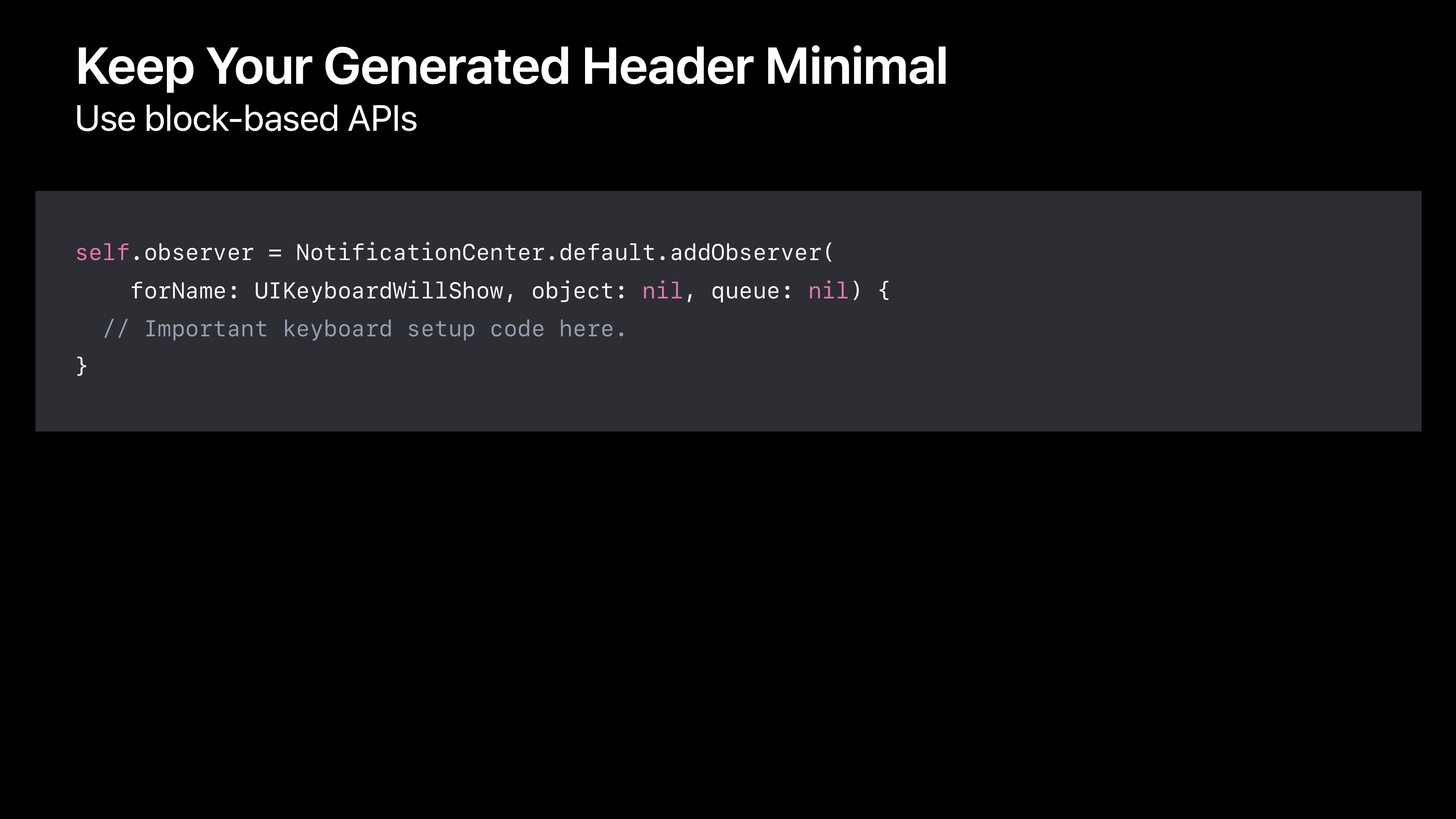
在这种情况下,也可以转换为基于块的API,这样甚至可以让代码更简洁。因为你可从那些注册时间通知的函数暗中的获取状态,而不是一直带着它。
另外在Xcode10中,关闭Swift 3 @objc Inference,在这种情况下,Objective-C属性只会从遵循协议要求的方法和性能或者那些重写自Objective-C的方法中推到出来。
在桥接头文件中,可能包含其他的头文件,当其他头文件中发生变化是,意味着你目标中的Swift代码需要重新编译。将一些Objective-C中不必要暴露出来的属性和方法,都放到者类扩展中实现。
更少的头文件内容,意味着更少的构建工作,同时也意味着出现变化的几率更小了,进而重新构建的几率更小。
总结
提升您的整体构建效率
- 并行化构建过程
- 测量构建时间
- 处理复杂的表达式
减少您在构建中需要做的工作
- 声明脚本的输入和输出
- 理解Swift中的依赖关系
- 混合开发中限制Objective-C/Swift的接口内容
