DDIA_Chapter5 学习笔记
Replication:
多个结点存储相同数据的副本:
1.减少延迟——数据和用户再地理位置上相近(CDN?)
2.容错——结点出现异常,其他结点可以继续提供服务
3.扩展性——多结点可以处理更多读请求,提高系统吞吐量
Leader&Follower:
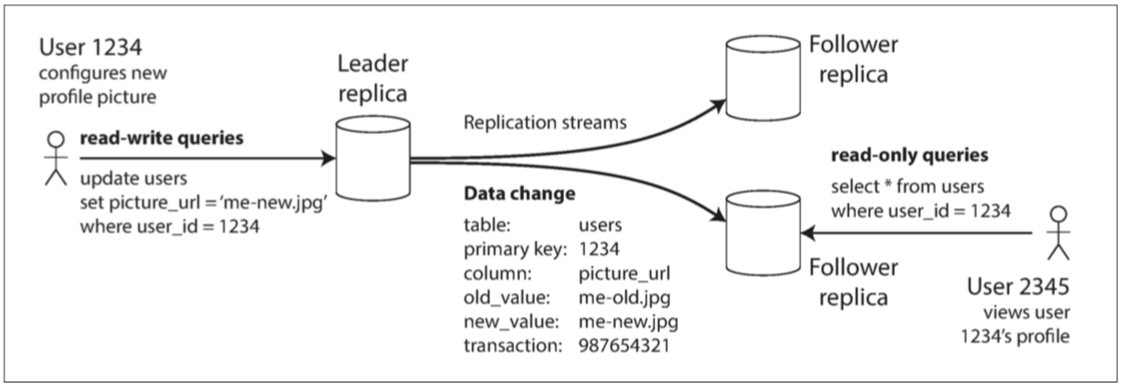
Master:写操作只能通过Master,读操作可以通过Master也可以通过Follower。当写入新数据时,Master会将其写入本地存储;同时会将数据变更——变更日志或变更流发送给所有的Follower。
Follower(只读副本):根据变更日志(按照变更日志的相同操作)变更自身数据。并且只能接收读操作。
1.主从复制(单Master&Slave模式):
Master:写操作只能通过Master,读操作可以通过Master也可以通过Follower。当写入新数据时,Master会将其写入本地存储;同时会将数据变更——变更日志或变更流发送给所有的Follower。
Follower(只读副本):根据变更日志(按照变更日志的相同操作)变更自身数据。并且只能接收读操作。
这种复制模式是许多关系数据库的内置功能,如PostgreSQL(从9.0版本开始),MySQL,Oracle Data Guard 【2】和SQL Server的AlwaysOn可用性组【3】。 它也被用于一些非关系数据库,包括MongoDB,RethinkDB和Espresso 【4】。 最后,基于领导者的复制并不仅限于数据库:像Kafka 【5】和RabbitMQ高可用队列【6】这样的分布式消息代理也使用它。 某些网络文件系统,例如DRBD这样的块复制设备也与之类似。
1.1同步/异步复制:
同步复制:在向用户报告写入成功,并使结果对其他用户可见之前,Master需要等待Follower的确认,确保Follower已经收到写入操作。以及在使写入对其他客户端可见之前接收到写入。(Follower复制成功之前不向用户返回响应。保证了用户收到响应时,Master和Follower之间的数据是一致的)——优点是,从库保证有与主库一致的最新数据副本。如果主库突然失效,我们可以确信这些数据仍然能在从库上上找到。缺点是,如果同步从库没有响应(比如它已经崩溃,或者出现网络故障,或其它任何原因),主库就无法处理写入操作。主库必须阻止所有写入,并等待同步副本再次可用。
异步复制:Master发送消息,但不等待Follower的响应。(用户收到写入成功的响应时,Follower可能尚未写入成功,这是Master和Follower之间的数据是不一致的)——在这种情况下,如果Master失效且不可恢复,则任何尚未复制给Follower的写入都会丢失。 这意味着即使已经向客户端确认成功,写入也不能保证 持久(Durable) 。 然而,一个完全异步的配置也有优点:即使所有的Follower都落后了,Master也可以继续处理写入。
半同步复制:其中一个Follower是同步的,而其他的则是异步的。如果同步Follower变得不可用或缓慢,则使一个异步Follower同步。这保证你至少在两个节点上拥有最新的数据副本:Master和同步Follower。
1.2复制延迟问题的处理:
在同步复制策略中,如果有任何一个Follower故障则会导致用户写入失败。因此,通常同步复制策略是不可靠的,会显著降低数据库系统的可用性。
在异步复制策略中,由于Master和Follower之间同步数据会存在延迟,因此,会导致数据库中的数据不一致。当用户对Master和Follower分别执行相同的查询操作,可能会得到不同的结果。这种不一致是一种暂时的状态,如果通知写操作并等待一段时间,最终Follower中的数据会和Master完全一致(数据同步完成)。这种数据一致性被成为——最终一致性。
问题1:由于存在Master和Follower之间的复制延迟,因此当用户执行完写操作后立即执行读操作,由于数据复制需要一段时间,用户可能无法查询到刚才写入的数据。
针对这种问题,我们需要读写一致性(read-after-write consistency),也称为 读己之写一致性(read-your-writes consistency):
保证用户读取自己写入的数据是一致的,不保证其他用户能读取到。通常方法包括:
1.根据上次更新的时间。例如,数据上次更新的时间在一分钟以内的读请求,只能走Master(yb:数据同步复制的时间不固定,这种办法也无法完全保证read-after-write)。还可以监控Follower的复制延迟,防止任向任何滞后超过一分钟的Follower发出查询。
问题2:由于存在Master和各Follower之间的复制延迟不同,因此当用户从不同Follower读取数据时,可能会出现“时光倒流”的问题。即,如果先访问延迟小的Follower,再访问延迟大的Follower。那么可能后面读到的反而是旧数据,这种现象被成为“时光倒流”。
针对这种问题,我们需要单调读(Monotonic reads):
保证用户如果先读取到较新的数据,后续不会读取到更旧的数据。通常做法包括:
1.确保每个用户的读请求都访问同一个Follower。例如,可以对每个用户进行hash,然后基于用户的hash值选择Follower。(yb:这样可能会导致不同Follower之间的负载不均衡)
1.3数据库结点故障处理:
Follower故障: 当Follower从故障中恢复时。由于,Master向 Follower同步数据是通过变更日志或变更流实现的。因此,在其本地磁盘上,每个Follower记录了从Master收到的数据变更。如果Follower崩溃并重新启动,或者,如果Master和Follower之间的网络暂时中断,则比较容易恢复:Follower可以从变更日志中知道发生故障之前处理的最后一个事务。因此,Follower可以从Master同步这个事务之后的所有变更。当应用完所有这些变化后,它就赶上了Master,并可以像以前一样继续接收数据变更流。
Master故障:Master的故障切换通常包含下列步骤:1.通过超时时间(Timeout)判断Master已经失效;2.通过选主,选取一个Follower为新Master,通常被选为新Master的Follower中的数据是和Master最相近的(最小化数据损失),并让其他Follower认可新Master;3.老Master恢复后,脑裂(Brain Split)问题的处理。
Master的故障会造成很大的麻烦:1.如果Master和Follower之间是异步复制,则会存在数据丢失的问题。2.老Master恢复后可能会出现脑裂问题。
2.多主复制(多Master&Slave模式):
首先对数据库做Sharding,将数据划分为多个Partition,每个Partition有自己独有的Master和Followers,Partition之间不相互影响。
每个Master同时扮演其他Master的Follower。再上文讲述的1Master&多Follower场景下,Master的角色的确定的。而在多Master的场景下,某个结点扮演的角色不固定,例如:它可能是Partiton1的Master,与此同时也是Partition2的Follower。
应用场景:多数据中心
假如你有一个数据库,副本分散在好几个不同的数据中心(也许这样可以容忍单个数据中心的故障,或地理上更接近用户)。 使用常规的基于领导者的复制设置,主库必须位于其中一个数据中心,且所有写入都必须经过该数据中心。
多领导者配置中可以在每个数据中心都有Master,在每个数据中心内使用常规的主从复制;在数据中心之间,每个数据中心的Master都会将其更改异步复制到其他数据中心的Master中。
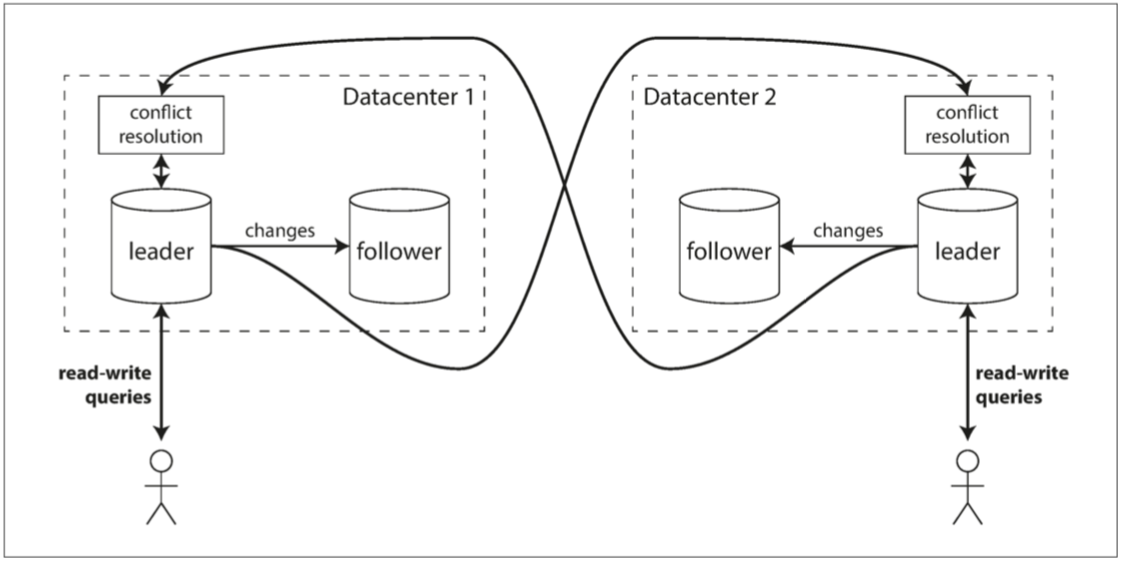
问题1:多Master操作相同数据时,会存在写入冲突,如图:

避免冲突: 处理冲突的最简单的策略就是避免它们:如果应用程序可以确保特定记录的所有写入都通过同一个Master,那么冲突就不会发生。
3.无主复制(Materless模式):
一些数据存储系统采用不同的方法,放弃Master和Follower的概念,允许任何Partition直接接收来自用户的写入——Dynamo和Cassandra等数据库采用了这种模式,因此这种模式被成为Dynamo模式。
在一些Masterless的实现中,用户直接将写入发送到到若干个Partition中;而另一些情况下,一个Coordinator节点代表用户进行写入。但与Master不同,Coordinator不执行特定的写入顺序。我们将会看到,这种设计上的差异对数据库的使用方式有着深远的影响。
仲裁一致性:
法定数量(Quorum):假设有一个有三个Partition的数据库,而其中一个Partition目前不可用。对于写操作,在基于Master&Slave的配置中,需要执行故障切换。而在Masterless模式中——只要写入时接收到请求的Partition数量超过法定数量(Quorum)则认为写入成功,并简单地忽略了某些不可用的Partition。对于读操作,当不可用的结点重新恢复后,整个数据库集群会存在数据不一致的情况。解决该问题的方法是——用户向数据库发送读取请求时,请求会并行地发送至多个Partition,用户会得到多个不同的响应结果,有的响应返回的是最新的完整数据、有的响应返回的是不一致的旧数据,通过版本号来确定哪个结果是最新的。
对于写入操作和读取操作的法定人数可以是不同的。假设数据库集群总共有N个结点,写入操作的法定人数为W,读取操作的法定人数为R,即——当执行写操作时,只有W个结点响应写入成功后,我们才认为写成功;当执行读操作时,需要将请求发送至R个结点,并等待R个响应。则当W+R>N时,能保证用户在读取时存在至少一个完整数据响应。
通常,我们会将N设置为奇数、W和R的取值为对N / 2的值向上取整,例如N为7,W和R则为4。
我们也可以根据不同业务需求修改W和R的取值——对于一个写少读多的情景,可将W值设置为N,将R设置为1,这样使得读操作更快,但是会导致写入时的强一致性。
不可用结点恢复后的数据修复:1.读修复(Read Repair),即读取时修复,用户读取数据时如果发现有的响应结果是旧数据,则用最新数据将其更新。2.反熵(Anti-entropy process),数据库后台创建扫描进程,不断扫描各Partition之间的数据差异,并将差异部分修复。
合并并发写入:
并发的概念:当多个用户在感知不到对方的存在的情况下对数据库的操作,被视为并发操作。即,其他用户操作完成之前对数据库进行操作。
写入合并算法:
1.数据库为每条数据建立一个版本号。
2.用户在对数据库进行操作时,首先需要读取数据库中当前的数据和数据对应的新版本号,然后将自己需要写入的数据合并在一起。
3.当数据写入时,只覆盖低版本号的数据,保留高版本号的数据。
4.如果数据写入时不包含版本号则不会覆盖任何数据。
删除标记:墓碑(tombstone),用于记录数据删除,防止并发合并错误结果。
版本向量:写入合并算法只能保证单个Partition的写入,多Partition的写入需要版本向量算法——除了对每条数据使用版本号之外,还需要在Partition中使用版本号。