scala在语法上和java千差万别,他的函数很多,但是他却完美的兼容java的语法和对象,今天我们就说一下他是如何兼容java的map的。
java的map
Map<String,String> map = new HashedMap();
map.put("name","zhangsan");
map.put("sex","male");
map.get("name");可能我们常用的就是这两个方法,当然还有remove,keySet,entrySet,这些方法,那么在scala里边如何实现的呢。
scala的map
在Scala里边,如果要实现将java的map转化成scala的map,需要引入jar包,他会给我们实现相应的转化,引入的就是import scala.collection.JavaConversions.mapAsScalaMap,这样我们就可以在这两者自由切换,例如如下代码
@Test
def testJavaMaptoScalaMap(): Unit = {
var javaMap: util.HashMap[String, AnyRef] = new util.HashMap[String, AnyRef]()
javaMap.put("name", "zhangsan")
javaMap.put("sex", "male")
javaMap.put("age", "23")
javaMap += ("ciyt" -> "beijing")
for (v <- javaMap.keySet) println(v + "====" + javaMap(v))
}结果如下:

当然上边的语法我们慢慢来解析,但是javaMap.put(“name”,”zhangsan”)这句话大家应该非常的熟悉吧。
map语法介绍
scala的无论是put还是get都和java的不太一样,在这方便,他更家的面型函数,例如添加键值对。他的语法是map(key1->value1,key2->value2,…),如果是在原有的map上新加元素,则map +=(key,value),如果是修改的话map(key)=value,当然获取他的key集合和java一样。
@Test
def testMapScala(): Unit = {
val map = Map("name" -> "zhangsan", "sex" -> "man", "age" -> 23)
val map2 = scala.collection.mutable.Map("name" -> "li", "sex" -> "women", "age" -> 18)
map2("name") = "lisimeimei"
map2 += ("city" -> "beijing", "nickname" -> "wangshisuuifeng")
for (v <- map2.keySet) println(v + "====" + map2(v))
println("=============================")
//map的keyvalue反转
val map3 = for ((k, v) <- map2) yield (v, k)
for (v <- map3.keySet) println(v + "-====" + map3(v))
}如果是不可变得的map,直接Map(key->value),如map,但是如果是可变的map,则必须要类型明确标明scala.collection.mutable.Map,否则编译器不会报错,但是执行的话会报错误。
结果如下

上边我们会看到(k,v),在scala里边,这叫做元组,而这个也是最简单的元组,元组里边可以有多个,例如(”person”,”zhangsan”,”male”,29)这就是一个元组,这就是我上边遍历的时候出现的 for ((k, v) <- map2),map里边会有多个元组。
@Test
def testChain(): Unit = {
val symbols = Array("<", "-", ">")
val counts = Array(2, 10, 2)
val pairs = symbols.zip(counts)
for((k,v) <- pairs) print(k*v)
pairs.toMap.foreach(a=>{
println(a._1)
})
}上边的代码symbols和counts都是元组,而zip在scala中是一个拉链操作,可以将元组元素组合在一起。例如上边的的pair,我们执行一下

获取元组的数组,是symbols._1,_2,_3….,有几个咱们就可以_N,并且可以执行这个乘积操作。
扩展Any
在上边我们会看到我new一个java的map的时候,类型指定的时候我写的是AnyRef,其实在scala里边还有Any,AnyVal,这三者的区别非常的简单,在scala里边,也有类似java的引用类型和值类型,
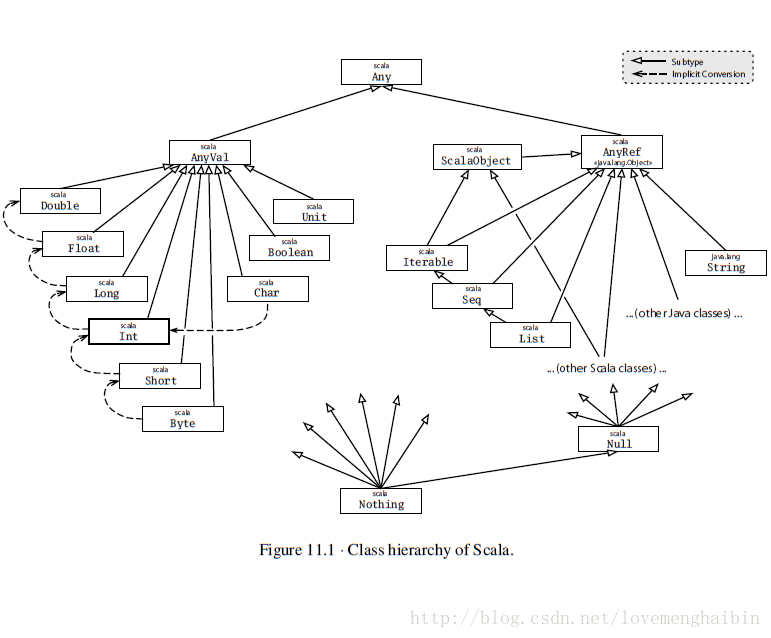
AnyVal一共有9种,之后都是AnyRef
与其他语言稍微有点不同的是,Scala还定义了底类型
其中Null类型是所有引用类型的底类型,及所有AnyRef的类型的空值都是Null
而Nothing是所有类型的底类型,对应Any类型
var javaMap: util.HashMap[String, Any] = new util.HashMap[String, Any]()
javaMap.put("name", "zhangsan")
javaMap.put("sex", "male")
javaMap.put("age", 23)如果age我用23这个Int类型的话,就必须用Any,他是基类,否则AnyRef和AnyVal都会报错。
小结
通过比较我们发现,其实在scala中,我们的语法和java的语法差很多,不过个人感觉对于scala,尽管他的语法更加复杂,但是如果能运用好的话,也是事半功倍,毕竟有很多的功能,是人家就给咱们写好的。
