E-R模型向关系模型转换
1.为E-R图中的每个实体建立一张表。
2.为每张表定义一个主键(如果需要,可以向表添加一个没有实际意义的字段作为该表的主键)
3.增加外键表示一对多关系。
4.建立新表表示多对多关系。
5.为字段选择合适的数据类型。
6.定义约束条件(如果需要)。
7.评价关系的质量,并进行必要的改进。
使用规范化减少数据冗余
冗余的数据需要额外的维护,并且容易导致“数据不一致”、“插入异常”以及“删除异常”等问题的发生。
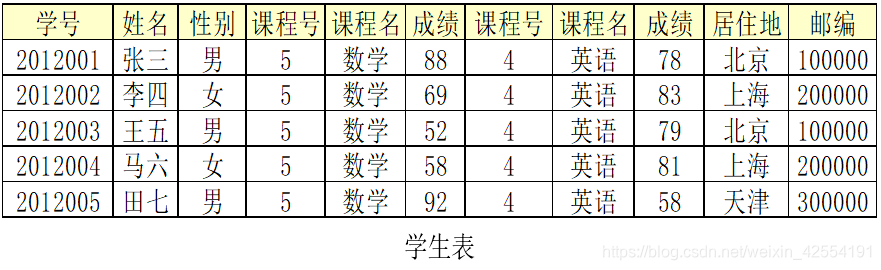
场景一:插入异常。添加一学生信息(学号2012006,姓名张三丰,居住地北京,邮编10000)
场景二:修改复杂。将课程号为5的课程名修改为“高等数学”
场景三:删除异常。将学号为2012005的学生信息删除,但“居住地”与“邮编”的对应关系保留
规范化是通过最小化数据冗余来提升数据库设计质量的过程,规范化是基于函数依赖以及一系列范式定义的,最为常用的是第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
函数依赖:对应于属性组合X的不同值, Y属性必有不同的取值,则称X决定Y,或称Y函数依赖于X。记为:X→Y。
完全函数依赖和部分函数依赖:如果X→Y成立,但对X的任意真子集X1,都有X1→Y不成立,称Y完全函数依赖于X,否则,称Y部分函数依赖于X。
传递函数依赖:设X,Y,Z是关系表R的不同属性集,若X→Y(并且Y→X不成立),Y→Z,称X传递决定Z,或称Z传递函数依赖于X。
第一范式
如果一张表内同类字段不重复出现,该表就满足第一范式的要求。
第二范式
一张表在满足第一范式的基础上,如果每个“非关键字”字段都完全函数依赖于主键,那么该表满足第二范式的要求。
第三范式
如果一张表满足第二范式的要求,并且不存在“非关键字”字段函数依赖于任何其他“非关键字”字段,即不满足传递函数依赖,那么该表满足第三范式的要求。
避免数据经常发生变化
统计学生的个人资料时,如果读者是一名数据库开发人员,应该让学生上报年龄信息,还是让学生上报出生日期?一个人年龄每隔一年就要执行“加1”操作,但是出生日期不会随着时间的推移而变化。
对于“选课系统”中如何确保每一门课程选报学生的人数,不超过人数上限?
方案一:在“课程表 ”中增加一个字段用于标记每一门课程剩余的学位,其初始值设置为课程的人数上限,每选进来一个学生就减1,当值为0时,表示已满。
course(course_no, course_no,course_name,
up_limit,description,status,teacher_no, available)
方案二:数据库表无需进行任何更改,而是通过“课程人数上限”减去“选课choose”表中统计得出的“已选学生人数”字段的值 。
方案一是增加了冗余字段“available”,但能方便几百名学生同时查询哪些课程已满;但是如果几百学生同时选课、调课、退课的话,“available”字段值会时刻发生变化,这不利于数据维护也容易出现数据不一致。反过来,方案二无需维护冗余数据,也不用担心数据不一致,但却不利于数据查询。
