k折交叉验证
留出法会造成数据信息量减少,解决这种问题的方法就是交叉验证法。
当k=m时,也叫留一法。
交叉验证首先将数据集分成大小相似的k个子集,然后在每一折交叉验证中将k-1个子集作为训练集,剩下的那个子集作为验证集用于评估模型。这样我们就可以找到验证集上分数最高的模型作为我们的最终模型用来测试test data。而对于评估模型的性能可以对k个验证集的评估结果取平均值作为泛化误差。
以下是5折交叉验证寻找超参数的图例:
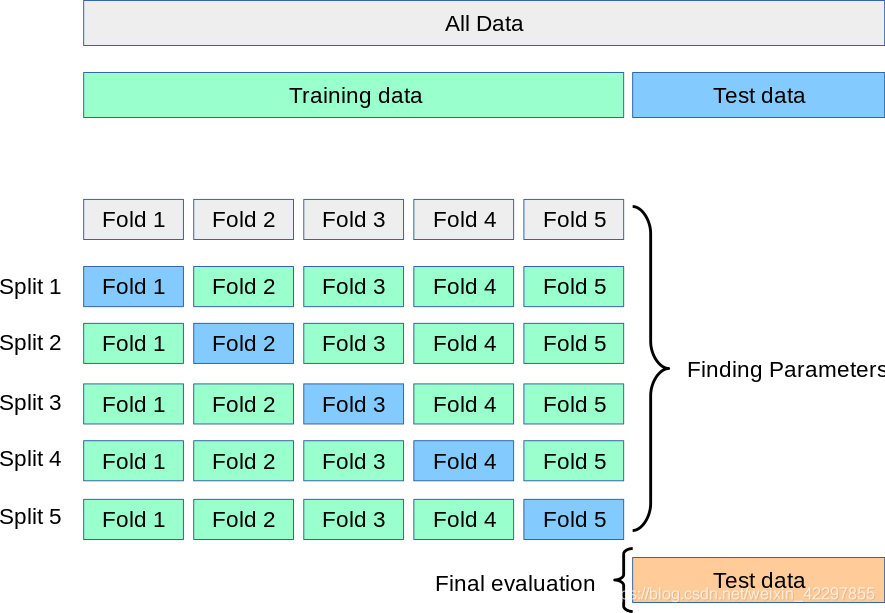
此图来源于sklearn官方文档
#Validation function
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf))
return(rmse)
Thanks for reading ----by LiHao
