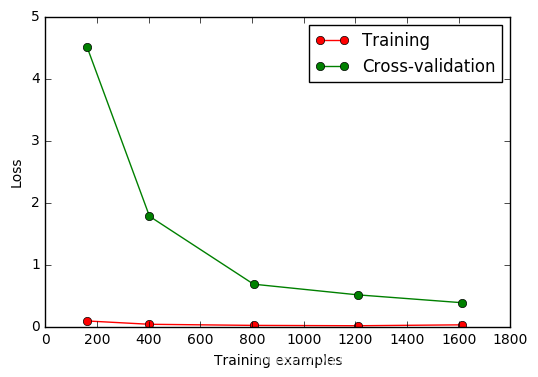
sklearn.learning_curve 中的 learning curve 可以很直观的看出我们的 model 学习的进度, 对比发现有没有 overfitting 的问题. 然后我们可以对我们的 model 进行调整, 克服 overfitting 的问题.
Learning curve 检视过拟合
加载对应模块:
from sklearn.model_selection import learning_curve #学习曲线模块
from sklearn.datasets import load_digits #digits数据集
from sklearn.svm import SVC #Support Vector Classifier
import matplotlib.pyplot as plt #可视化模块
import numpy as np
加载digits数据集,其包含的是手写体的数字,从0到9。数据集总共有1797个样本,每个样本由64个特征组成, 分别为其手写体对应的8×8像素表示,每个特征取值0~16。
digits = load_digits()
X = digits.data
y = digits.target
观察样本由小到大的学习曲线变化, 采用K折交叉验证 cv=10, 选择平均方差检视模型效能 scoring=‘mean_squared_error’, 样本由小到大分成5轮检视学习曲线(10%, 25%, 50%, 75%, 100%):
train_sizes, train_loss, test_loss = learning_curve(
SVC(gamma=0.001), X, y, cv=10, scoring='mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
#平均每一轮所得到的平均方差(共5轮,分别为样本10%、25%、50%、75%、100%)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
可视化图形:
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
连续三节的交叉验证(cross validation)让我们知道在机器学习中验证是有多么的重要, 这一次的 sklearn 中我们用到了sklearn.learning_curve当中的另外一种, 叫做validation_curve,用这一种曲线我们就能更加直观看出改变模型中的参数的时候有没有过拟合(overfitting)的问题了. 这也是可以让我们更好的选择参数的方法.
validation_curve 检视过拟合
继续上一节的例子,并稍作小修改即可画出图形。这次我们来验证SVC中的一个参数 gamma 在什么范围内能使 model 产生好的结果. 以及过拟合和 gamma 取值的关系.
from sklearn.model_selection import validation_curve #validation_curve模块
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#digits数据集
digits = load_digits()
X = digits.data
y = digits.target
#建立参数测试集
param_range = np.logspace(-6, -2.3, 5)
#使用validation_curve快速找出参数对模型的影响
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='mean_squared_error')
#平均每一轮的平均方差
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
#可视化图形
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation")
plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
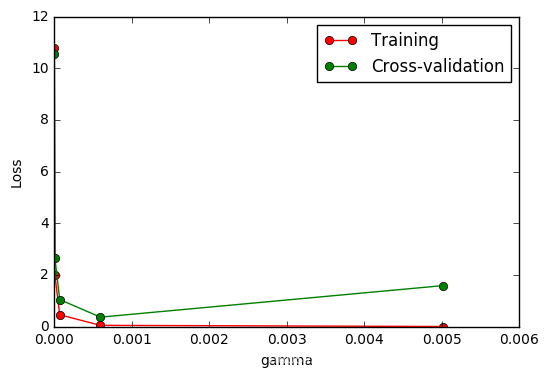
由图中可以明显看到gamma值大于0.001,模型就会有过拟合(Overfitting)的问题。
扫描二维码关注公众号,回复:
5928004 查看本文章
