文章目录
1、Cassandra 简介
1.1、简述
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra集群来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。
1.2、突出特点
-
模式灵活
使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部署上。 -
真正的可扩展性
Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。 -
多数据中心识别
你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
2、CentOS 操作 Cassandra
2.1、下载 Cassandra
官方下载地址:http://cassandra.apache.org/download/
地址列表:https://supergsego.com/apache/cassandra/
吐槽一下Cassandra安装包的下载速度太慢了,所以我上传了一份到csdn
csdn下载地址:https://download.csdn.net/download/u014597198/11252289
下载 2.2.14 版本
curl -O https://supergsego.com/apache/cassandra/2.2.14/apache-cassandra-2.2.14-bin.tar.gz
解压
tar -zxvf apache-cassandra-2.2.14-bin.tar.gz
移动文件夹
mv apache-cassandra-2.2.14 /usr/local/cassandra
效果

2.2、检测是否安装了java环境
如果没装,安装一个java环境即可,装了的话可以不用重复装

2.3、修改配置文件 cassandra.yaml
- 配置文件

- 集群名称,可以不改

- 去除掉注释,数据文件存放路径

- 去除掉注释,操作日志文件存放路径

- 去除掉注释,缓存文件存放路径

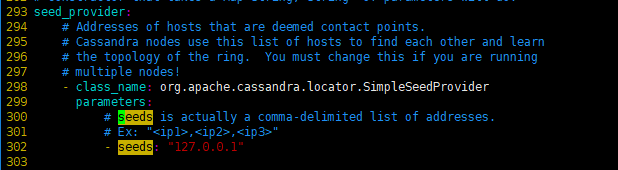
- 集群种子节点ip,新加入集群的节点从种子节点中同步数据。可配置多个,中间用逗号隔开
- 需要监听的IP或主机名。改成本机IP
这里解释一下 listen_address :该配置是为了告诉集群中其他节点如何连接到该节点上。永远不要指定0.0.0.0,总是错的。
一个集群中该节点的 address 必须唯一,因为该地址就像一个独一无二的身份id,只有知道该连接,Cassandra集群才可以建立连接,可以设置为空。Cassandra 通过 InetAddress.getLocalHost() 可以从系统获取本地地址。
如果 Cassandra 找不到正确的地址,你可以指定IP地址或者主机名称。
如果是单节点集群,你可以使用默认配置( localhost )。

- 修改 rpc_address(用于监听客户端连接的地址)
解释一下 rpc_address :默认值localhost,Thrift RPC 服务和本地传输服务都会使用该地址,简单的可以理解为client与Cassandra服务端通信的地址。如果不设置该项,将会采用listen_address的设置。该配置可以设置为0.0.0.0,但是如果这样设置了,你必须设置broadcast_rpc_address为其他地址,broadcast_rpc_address不能被设置为0.0.0.0,broadcast_rpc_address是rpc地址广播到驱动和其他节点上的地址,默认值1.2.3.4。

- 默认端口9160端口,可以不改

2.4、修改配置文件 cassandra-env.sh
- 这里如果不更改,机器默认的是这样的

这里可以按照我们的需要进行更改,我的更改如下

2.5、后台启动
nohup /usr/local/cassandra/bin/cassandra > /usr/local/cassandra/cassandra.log 2>&1 &
2.6、检测cassandra进程是否开启
ps aux|grep cassandra
刚打开:

过一段时间,已经初始化,再次查询进程

3、Python3 操作Cassandra
3.1、安装 pycassa
pip install cassandra-driver
github地址:https://github.com/datastax/python-driver
如果上述命令没成功,可以用以下命令直接从github上拉取
pip install git+https://github.com/datastax/python-driver.git

3.2、效果图

3.3、简单的讲解
3.3.1、创建会话(如果有该会话直接连接即可)
# 创建会话
def create_key_space(keyspacename,ster):
session = ster.connect()
return session
# 连接会话(获取指定keyspace的会话连接)
def connect_key_space(keyspacename,ster):
session = ster.connect(keyspace=keyspacename)
return session
3.3.2、创建表单(如果有该表单就没必要创建了)
session.execute("create table stu(name text, id int primary key);")# 创建table
print("创建table")
3.3.3、进行增、删、改、查
# 增加
sql = 'insert into stu(id,name) values(%s, %s)'
session.execute(sql, (1, 'ShaShiDi'))
session.execute(sql, (2, 'ShaShiDi'))
print("增加id=1和2,name=ShaShiDi")
# 更新
sql='update stu set name=%s where id=%s'
session.execute(sql, ('SHA SHI DI', 2))
print("根据ID更新某项的字段,这里更新id=2的name为SHA SHI DI")
# 查询所有
sql = 'select * from stu'
rs = session.execute(sql)
print("查询所有:",rs.current_rows)
# 主键id查询/条件查询
sql = 'select * from stu where id=%s'
rs = session.execute(sql, [2]) #另一种写法,其它类似
print("查询(写法1):",rs.current_rows)
rs = session.execute(sql, (2,))
print("查询(写法2):",rs.current_rows)
# 删除
sql = 'delete from stu where id=%s '
session.execute(sql, (2,))
print("按照ID删除某项")
3.3.4、关闭会话连接
# 关键连接
session.shutdown()
3.4、完整源码
注意以下源码是未创建会话,直接连接的会话,在未创建会话之前,要先创建会话哦~
# -*- coding:utf8 -*-
from cassandra.cluster import Cluster
from cassandra.policies import RoundRobinPolicy
# 创建会话
def create_key_space(keyspacename,ster):
session = ster.connect()
return session
# 连接会话(获取指定keyspace的会话连接)
def connect_key_space(keyspacename,ster):
session = ster.connect(keyspace=keyspacename)
return session
# 打印会话连接key_spaces
def print_key_spaces(ster):
print("-------打印会话连接key_spaces------")
print(ster.metadata.keyspaces)
print("-----------------------------------")
# 打印表单tables
def print_tables(ster,keyspacename):
print("------------打印表单tables---------")
print(ster.metadata.keyspaces[keyspacename].tables)
print("-----------------------------------")
if __name__ == '__main__':
# 获取集群
ster = Cluster(contact_points=['127.0.0.1'],
port=9042,
load_balancing_policy=RoundRobinPolicy())
# 会话连接名称
keyspacename = "demoshashidi"
session = connect_key_space(keyspacename, ster)
print_key_spaces(ster)
print_tables(ster, keyspacename)
session.execute('drop table stu;')# 删除table
print("删除table")
session.execute("create table stu(name text, id int primary key);")# 创建table
print("创建table")
# 增加,和update类似
sql = 'insert into stu(id,name) values(%s, %s)'
session.execute(sql, (1, 'ShaShiDi'))
session.execute(sql, (2, 'ShaShiDi'))
print("增加id=1和2,name=ShaShiDi")
# 更新,和insert类似
sql='update stu set name=%s where id=%s'
session.execute(sql, ('SHA SHI DI', 2))
print("根据ID更新某项的字段,这里更新id=2的name为SHA SHI DI")
# 查询所有
sql = 'select * from stu'
rs = session.execute(sql)
print("查询所有:",rs.current_rows)
# 主键id查询/条件查询
sql = 'select * from stu where id=%s'
rs = session.execute(sql, [2]) #另一种写法,其它类似
print("查询(写法1):",rs.current_rows)
rs = session.execute(sql, (2,))
print("查询(写法2):",rs.current_rows)
# 删除
sql = 'delete from stu where id=%s '
session.execute(sql, (2,))
print("按照ID删除某项")
# 查询所有
sql = 'select * from stu'
rs = session.execute(sql)
print("查询所有:",rs.current_rows)
# 关键连接
session.shutdown()
