104. 二叉树的最大深度
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例:
给定二叉树 [3,9,20,null,null,15,7],

返回它的最大深度3。
思路一:C++的三种方法实现(有注解)
递归、栈循环实现深度优先遍历;用队列循环实现层遍历。借鉴了伊利亚·穆罗梅茨的代码。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
//深度优先:递归版
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
int l=maxDepth(root->left)+1;
int r=maxDepth(root->right)+1;
return l>r?l:r;
}
};
//深度优先:用栈的循环版
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
stack<pair<TreeNode*,int>> s;
TreeNode* p=root;
int Maxdeep=0;
int deep=0;
while(!s.empty()||p!=NULL)//若栈非空,则说明还有一些节点的右子树尚未探索;若p非空,意味着还有一些节点的左子树尚未探索
{
while(p!=NULL)//优先往左边走
{
s.push(pair<TreeNode*,int>(p,++deep));
p=p->left;
}
p=s.top().first;//若左边无路,就预备右拐。右拐之前,记录右拐点的基本信息
deep=s.top().second;
if(Maxdeep<deep) Maxdeep=deep;//预备右拐时,比较当前节点深度和之前存储的最大深度
s.pop();//将右拐点出栈;此时栈顶为右拐点的前一个结点。在右拐点的右子树全被遍历完后,会预备在这个节点右拐
p=p->right;
}
return Maxdeep;
}
};
//广度优先:使用队列
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
deque<TreeNode*> q;
q.push_back(root);
int deep=0;
while(!q.empty())
{
deep++;
int num=q.size();
for(int i=1;i<=num;i++)
{
TreeNode* p=q.front();
q.pop_front();
if(p->left) q.push_back(p->left);
if(p->right) q.push_back(p->right);
}
}
return deep;
}
};
作者:zzxh
链接:https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/solution/cde-san-chong-fang-fa-shi-xian-you-zhu-jie-by-zzxh/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我的:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root)
{
if(root == NULL)
{
return 0;
}
int l = maxDepth(root -> left) + 1;
int r = maxDepth(root -> right) + 1;
return l > r?l:r;
}
};
108. 将有序数组转换为二叉搜索树
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
示例:

思路一:详细通俗的思路分析,多解法
解法一 递归
如果做了 98 题 和 99 题,那么又看到这里的升序数组,然后应该会想到一个点,二叉搜索树的中序遍历刚好可以输出一个升序数组。
所以题目给出的升序数组就是二叉搜索树的中序遍历。
根据中序遍历还原一颗树,又想到了 105 题 和 106 题,通过中序遍历加前序遍历或者中序遍历加后序遍历来还原一棵树。前序(后序)遍历的作用呢?提供根节点!然后根据根节点,就可以递归的生成左右子树。
这里的话怎么知道根节点呢?平衡二叉树,既然要做到平衡,我们只要把根节点选为数组的中点即可。
综上,和之前一样,找到了根节点,然后把数组一分为二,进入递归即可。注意这里的边界情况,包括左边界,不包括右边界。

解法二 栈 DFS
递归都可以转为迭代的形式。
一部分递归算法,可以转成动态规划,实现空间换时间,例如 5题,10题,53题,72题,从自顶向下再向顶改为了自底向上。
一部分递归算法,只是可以用栈去模仿递归的过程,对于时间或空间的复杂度没有任何好处,比如这道题,唯一好处可能就是能让我们更清楚的了解递归的过程吧。
自己之前对于这种完全模仿递归思路写成迭代,一直也没写过,今天也就试试吧。
思路的话,我们本质上就是在模拟递归,递归其实就是压栈出栈的过程,我们需要用一个栈去把递归的参数存起来。这里的话,就是函数的参数 start,end,以及内部定义的 root。为了方便,我们就定义一个类。

第一步,我们把根节点存起来。

然后开始递归的过程,就是不停的生成左子树。因为要生成左子树,end - start 表示当前树的可用数字的个数,因为根节点已经用去 1 个了,所以为了生成左子树,个数肯定需要大于 1。

在递归中,返回null以后,开始生成右子树。这里的话,当end-start<= 1,也就是无法生成左子树了,我们就可以出栈,来生成右子树。

然后把上边几块内容组合起来就可以了。
class MyTreeNode {
TreeNode root;
int start;
int end;
MyTreeNode(TreeNode r, int s, int e) {
this.root = r;
this.start = s;
this.end = e;
}
}
public TreeNode sortedArrayToBST(int[] nums) {
if (nums.length == 0) {
return null;
}
Stack<MyTreeNode> rootStack = new Stack<>();
int start = 0;
int end = nums.length;
int mid = (start + end) >>> 1;
TreeNode root = new TreeNode(nums[mid]);
TreeNode curRoot = root;
rootStack.push(new MyTreeNode(root, start, end));
while (end - start > 1 || !rootStack.isEmpty()) {
//考虑左子树
while (end - start > 1) {
mid = (start + end) >>> 1; //当前根节点
end = mid;//左子树的结尾
mid = (start + end) >>> 1;//左子树的中点
curRoot.left = new TreeNode(nums[mid]);
curRoot = curRoot.left;
rootStack.push(new MyTreeNode(curRoot, start, end));
}
//出栈考虑右子树
MyTreeNode myNode = rootStack.pop();
//当前作为根节点的 start end 以及 mid
start = myNode.start;
end = myNode.end;
mid = (start + end) >>> 1;
start = mid + 1; //右子树的 start
curRoot = myNode.root; //当前根节点
if (start < end) { //判断当前范围内是否有数
mid = (start + end) >>> 1; //右子树的 mid
curRoot.right = new TreeNode(nums[mid]);
curRoot = curRoot.right;
rootStack.push(new MyTreeNode(curRoot, start, end));
}
}
return root;
}
解法三 队列 BFS
参考 这里。 和递归的思路基本一样,不停的划分范围。
class MyTreeNode {
TreeNode root;
int start;
int end;
MyTreeNode(TreeNode r, int s, int e) {
this.root = r;
this.start = s;
this.end = e;
}
}
public TreeNode sortedArrayToBST3(int[] nums) {
if (nums.length == 0) {
return null;
}
Queue<MyTreeNode> rootQueue = new LinkedList<>();
TreeNode root = new TreeNode(0);
rootQueue.offer(new MyTreeNode(root, 0, nums.length));
while (!rootQueue.isEmpty()) {
MyTreeNode myRoot = rootQueue.poll();
int start = myRoot.start;
int end = myRoot.end;
int mid = (start + end) >>> 1;
TreeNode curRoot = myRoot.root;
curRoot.val = nums[mid];
if (start < mid) {
curRoot.left = new TreeNode(0);
rootQueue.offer(new MyTreeNode(curRoot.left, start, mid));
}
if (mid + 1 < end) {
curRoot.right = new TreeNode(0);
rootQueue.offer(new MyTreeNode(curRoot.right, mid + 1, end));
}
}
return root;
}
最巧妙的地方是它先生成 left 和 right 但不进行赋值,只是把范围传过去,然后出队的时候再进行赋值。这样最开始的根节点也无需单独考虑了。
扩展 求中点
前几天和同学发现个有趣的事情,分享一下。
首先假设我们的变量都是int值。
二分查找中我们需要根据start和end求中点,正常情况下加起来除以2 即可。
int mid = (start + end) / 2
但这样有一个缺点,我们知道int的最大值是 Integer.MAX_VALUE ,也就是2147483647。那么有一个问题,如果 start = 2147483645,end = = 2147483645,虽然 start 和 end都没有超出最大值,但是如果利用上边的公式,加起来的话就会造成溢出,从而导致mid计算错误。
解决的一个方案就是利用数学上的技巧,我们可以加一个 start 再减一个start将公式变形。
(start+end) / 2 = (start + end + start - start) / 2 = start + (end - start) / 2
这样的话,就解决了上边的问题。
然后当时和同学看到jdk源码中,求mid的方法如下
int mid = (start + end) >>> 1
它通过移位实现了除以 2,但。。。这样难道不会导致溢出吗?
首先大家可以补一下 补码 的知识。
其实问题的关键就是这里了>>> ,我们知道还有一种右移是>>。区别在于>>为有符号右移,右移以后最高位保持原来的最高位。而>>>这个右移的话最高位补 0。
所以这里其实利用到了整数的补码形式,最高位其实是符号位,所以当 start + end 溢出的时候,其实本质上只是符号位收到了进位,而>>>这个右移不仅可以把符号位右移,同时最高位只是补零,不会对数字的大小造成影响。
但>>有符号右移就会出现问题了,事实上 JDK6 之前都用的>>,这个 BUG 在 java 里竟然隐藏了十年之久。
作者:windliang
链接:https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by-24/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
思路二:

https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/solution/c-er-fen-fa-di-gui-qiu-jie-100-by-zhengjingwei/
我的:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums)
{
if(nums.empty())
{
return NULL;
}
return helper(nums,0,nums.size()-1);
}
TreeNode* helper(vector<int>& nums,int left,int right)
{
if(left > right)
{
return nullptr;
}
int mid = (left + right)/2;
TreeNode *root = new TreeNode(nums[mid]);
root -> left = helper(nums,left,mid - 1);
root -> right = helper(nums,mid + 1,right);
return root;
}
};
101. 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树[1,2,2,3,4,4,3]是对称的。
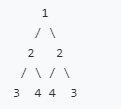
但是下面这个[1,2,2,null,3,null,3]则不是镜像对称的:

**说明:**如果你可以运用递归和迭代两种方法解决这个问题,会很加分。
思路一:
方法:递归
如果一个树的左子树与右子树镜像对称,那么这个树是对称的。
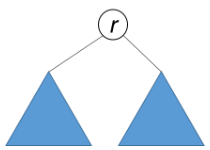
因此,该问题可以转化为:两个树在什么情况下互为镜像?
如果同时满足下面的条件,两个树互为镜像:
1.它们的两个根结点具有相同的值。
2.每个树的右子树都与另一个树的左子树镜像对称。

就像人站在镜子前审视自己那样。镜中的反射与现实中的人具有相同的头部,但反射的右臂对应于人的左臂,反之亦然。
上面的解释可以很自然地转换为一个递归函数,如下所示:

复杂度分析
时间复杂度:O(n),因为我们遍历整个输入树一次,所以总的运行时间为 O(n),其中 n是树中结点的总数。
空间复杂度:递归调用的次数受树的高度限制。在最糟糕情况下,树是线性的,其高度为O(n)。因此,在最糟糕的情况下,由栈上的递归调用造成的空间复杂度为O(n)。
方法二:迭代
除了递归的方法外,我们也可以利用队列进行迭代。队列中每两个连续的结点应该是相等的,而且它们的子树互为镜像。最初,队列中包含的是 root 以及 root。该算法的工作原理类似于 BFS,但存在一些关键差异。每次提取两个结点并比较它们的值。然后,将两个结点的左右子结点按相反的顺序插入队列中。当队列为空时,或者我们检测到树不对称(即从队列中取出两个不相等的连续结点)时,该算法结束。

复杂度分析
时间复杂度:O(n),因为我们遍历整个输入树一次,所以总的运行时间为 O(n),其中n是树中结点的总数。
空间复杂度:搜索队列需要额外的空间。在最糟糕情况下,我们不得不向队列中插入O(n)个结点。因此,空间复杂度为O(n)。
作者:LeetCode
链接:https://leetcode-cn.com/problems/symmetric-tree/solution/dui-cheng-er-cha-shu-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我的:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSymmetric(TreeNode* root)
{
return ismirror(root,root);
}
bool ismirror(TreeNode* t1,TreeNode* t2)
{
if(t1 == NULL && t2 == NULL)
{
return true;
}
if(t1 == NULL || t2 == NULL)
{
return false;
}
return (t1->val == t2->val)&&ismirror(t1->left,t2->right)&&ismirror(t1->right,t2->left);
}
};
