引言
其实我很早之前就想写关于java参数传递的内容,因为早在大学老师讲编程基础的时候就教我们参数的传递机制:值传递和引用传递,在很多java相关的书籍上也说明了java的传递机制有两种:值传递和引用传递,其实这种说法是不严谨的,严格来讲,java的参数传递机制只有一种——值传递,下面且听我细细道来。
值传递和引用传递
下面的表格阐述了何为值传递和引用传递:
| 传递类型 | 说明 |
|---|---|
| 值传递 | 在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数,如我们常见的基本数据类型作为参数即为值传递 |
| 引用传递 | 在调用函数时将实际参数的地址直接传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数 |
下面我们来写一段代码来说明问题,有助于加深理解:
public class passByValue {
public static void main(String[] args) {
int i = 10;
changeValue(i);
System.out.println(i);
}
private static void changeValue(int i) {
i = 100;
}
}
代码十分简单,int类型为基本数据类型,所以毫无疑问,这是值传递,在changeValue方法中修改的 i 其实是一个复制品,所以修改复制品,并不会影响原装产品的值,所以运行结果输出为10。
让我们再看下面一段代码:
public class passByValue {
public static void main(String[] args) {
String str = "test";
changeValue(str);
System.out.println(str);
}
private static void changeValue(String str) {
str = "change";
}
}
上面的代码运行结果是什么呢,相信有少部分人会有所犹豫,但经过仔细考虑给出的答案应该是“test”,没错,答案是正确的,但是其中的原因是什么呢,String并不是基本数据类型,为什么也出现了值传递才有的结果?
这个时候有些人会说String是final类型的,不允许引用发生变化,所以给它再次赋值对原来的String来说是无效的,听起来似乎有些道理,但这种说法其实并不对,属于偷换概念。final修饰的类不能被继承,但是被final修饰的类声明的变量的值是可以改变的,只要这个变量没有被final修饰即可。
好,让我们再看一段代码,如下:
public class passByValue {
public static void main(String[] args) {
Person person = new Person();
person.setName("小红");
changeValue(person);
System.out.println(person);
}
private static void changeValue(Person person) {
person.setName("小明");
}
}
class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
'}';
}
}
首先我声明了一个Person对象的引用,然后经过changeValue方法setName,那么最终执行的结果输出的person对象的名字是小红还是小明呢?哈哈,相信这个答案百分之99.9的人都可以答对,必然是小明!person是Person对象的引用,在changeValue方法中改变了它的name属性,所以最后的name属性也发生了变化,这也符合引用传递的特点。
好,让我们继续往下看:
public class passByValue {
public static void main(String[] args) {
Person person = new Person();
person.setName("小红");
changeValue(person);
System.out.println(person);
}
private static void changeValue(Person person) {
person = new Person();
person.setName("小明");
}
}
class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
'}';
}
}
这段代码跟上段代码的区别就在于changeValue方法里加了一行 person = new Person();,结果就大不一样了,没错,最终name还是小红,而不是小明,怎么回事,不是引用传递吗,如果是直接传递引用的内存地址,那么 new 了一个Person之后,地址应该指向 new 的Person才对,最后应该是小明呀,为什么还是小红呢?好了,让我们画图来分析一下吧,相信会让你豁然开朗!
堆栈图解
让我们假设person是引用传递,那么在堆栈当中应该是如下的状态:
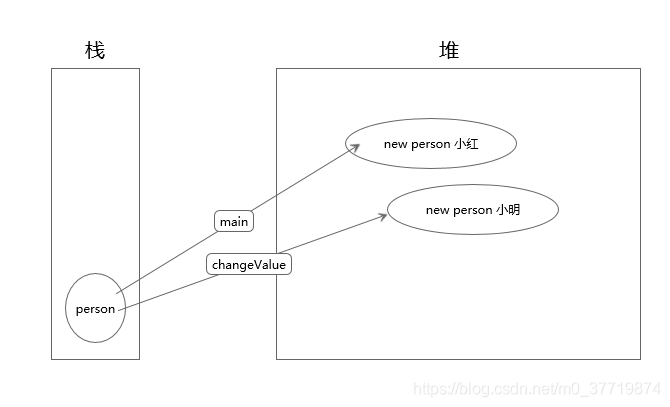
很明显,最后的结果就应该是小明,但是执行结果却是小红,好了,不卖关子,这是因为java并不是引用传递,而是值传递,提一句,上图在C#中是适用的。
好了,画图解析一下吧!
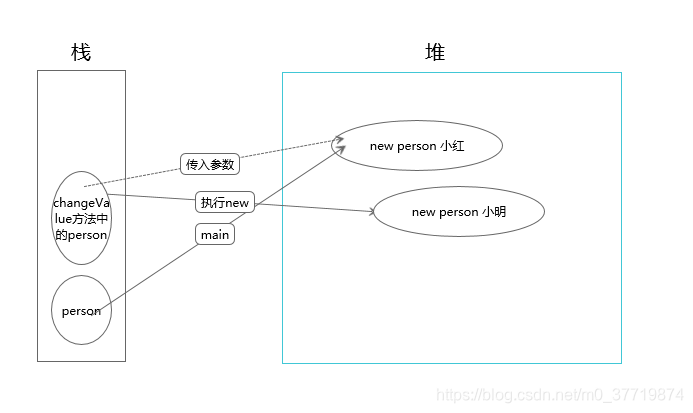
如上图,这就是真相,相信你已经一目了然,没错,正如你所看到的,在进行参数传递的时候,jvm复制了一份传递的引用指向小红,然后当 new 一个Person对象的时候指向新的内存空间,所以再去改变属性不会影响原来的引用,改变的只是副本的属性,导致程序最终的执行结果还是小红。 new 与 不 new 的区别就在于person副本有没有指向新的内存空间。
小结
好,到这里关于Java的参数传递便讲解完毕,因为我发现身边的很多同事和朋友对这个概念模糊不清,所以一直想写这么一篇博客。至于为什么java采用副本的方式传递参数,我想大概是为了安全吧,举个例子,一个人你好久不见,再见的时候他肯定还是本人,有可能他换了发型,换了名字,但他还是他,不可能是别人,如果再见的时候他变成了另外一个人岂不是太奇怪了!所以说java的开发者也许考虑到了这一点,而且这样做也可以有效的避免空指针异常的发生,因为有人总喜欢把传过来的对象赋值为null,这样副本的好处就体现出来了,原来的引用不会因此也变为null。希望这篇文章对你有所帮助,感谢您的观看,再见!
