遗传算法,模拟达尔文的自然选择和遗传学的机理的生物进化的计算模型。其实,遗传算法用到生物学的知识不多,一些中学的生物知识就足以应付。
其实,接触遗传算法是有一种熟悉的感觉。因为假期涉猎了机器学习,其中接触的第一个相关的算法就是梯度下降算法。(有关这个算法,以后再记录),这个算法的作用就是通过求偏导,使梯度不断下降,最终达到了一个局部的最优解。但是问题来了,在很多工业生产实践中,通常是不可微,不连续的,此时这些算法如梯度下降、牛顿法就有些力不从心了。进而一些智能算法就出现了,其中就有遗传算法,这些算法能够经过多次的迭代、概率的变化从而逐渐逼近全局最优解。
遗传算法依循“适者生存,优胜劣汰”的原则,通过模拟生物在自然选择中的进化过程,依靠选择,交叉,变异等机制对染色体
进行组合,实现染色体的不断更新,其中每条染色体对应一个解,每次迭代筛选群体中满足适应度的后代。
一、我们要进行编码,编码通常有两种。
1,实数编码:直观,无需解码,但是容易收敛,从而过早陷入局部最优解。简单理解来说,就是两个解之间的尺度太大了。
2,二进制编码:稳定性高,种群多样性大,不直观。
而我们在问题求解时倾向于用二进制编码的。二进制编码更有利于遗传算法的理解。
举一例子,如果x的定义范围是[0,4],则我们常规的编码成二进制是[0000,0100],那么解的可取范围就是,0000,0001,0010,0011.显然可供我们迭代的解的个数很少,但要是,我们将四位扩展成8位呢?
即令1111 1111=8,解的可取个数瞬间变大,当然我们可取上百位,但是由于计算机的资源的限制,我们通常二十位就好。
针对此例子,可以看作是染色体上有八个位点。
以上就是为啥要进行编码,当然我们还需要知道如何进行解码。x(10进制)=0+4*x/2^(8-1)。
二、关于交叉和变异。
生物进化就是染色体发生改变,包括形态,数量的变化的改变,其中染色体的是基因的载体,所以,基因的突变会导致生物的进化。其中的途径就是变异和交叉。其中,变异就是位点的改变(由于外界,自身的影响),具体就是碱基的突变,如A突变为G 等,而在遗传算法的计算模型中,变异就是0变为1,或者1 变为0.具体的规则可以自己去定义。关于交叉,其在发生在减数分裂染色体联会的时期,指同源染色体的非姐妹染色单体的片段发生交换。所以是两条染色体之间发生的交叉。对应于计算模型中,如,0111 0000 与1001 1111其交叉后的情形可能是1111 0000 与1001 0111。
以上就是变异和交叉的实现,那么为什么进行这样的操作?
其原因就是大大增加了随机性,也正是由于此,我们才有可能无限的逼近全局最优解。与梯度下降算法的对比为例,梯度下降(公式着实不好打出来)是一步步走向最优解,比如一个人在群山中旅游,他站在某个山的某个位置,这时他想要去这片群山的最低处,他应该怎末办?我们给他出个主意就是他应该持续不断往低处走,一直往下降的方向走。那么经过一段时间,他一定会来到当前山的最低处,发现这是最低点的斜率为零(理想情况下),那他按照这个主意的话,此时已经无路可走了(应该是原地打转)。但是他可能并没有达成他的愿望即到达整个群山的最低点。其实他现在所处的位置很大可能是局部最优解。
而遗传算法,则是赋予极其的跳跃能力,即当他到达局部最优解的时候,他可以跳到了另一座山上。有了这种随机的跳跃,我们就可逼近全局最优解。
三、关于适应度函数。
我们利用适应度函数来衡量这个生物是否适宜生存,用适应度来进行优胜劣汰,适应度大的个体会以较大的概率遗传给下一代,而小的有可能会遭到淘汰。
四,关于选择。
每次迭代都会产生大量的x值,如果不加以选择,那么内存会爆掉,同时会降低算法的效率。
我们计算出每个x的适应度y,然后求和得到sum。通常采用轮盘赌的方法,如果该个体的适应度y与sum的比值较大,则它有很大的概率会被选中。
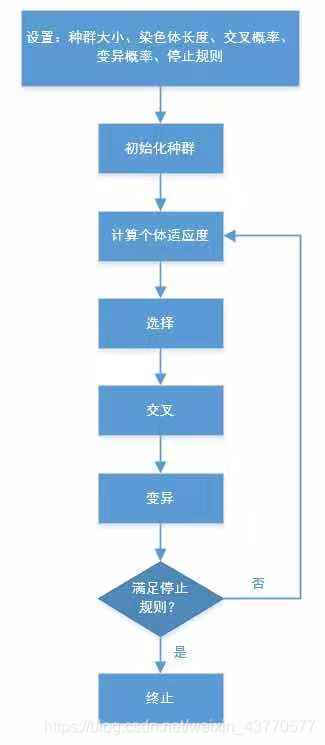
以上时整个算法的流程。
下面是关于各个步骤的matlab的代码片段,
pop_size=1000;%种群的大小
chromsome_size=17;%染色体的条数
generation=200;%迭代的次数
mutain=0.6;%变异的概率,这个变异的概率是位置变异的概率,如,染色体的长度是17,mutain是0.6,则变异的位置是round(0.6*17).
cross=0.01;%交叉的概率
%假定目标函数是f(x)=sin(x)+7cos(X)
%同时目标函数也是适应度函数
%假设x范围是[0,4];
%创建初始种群的函数
G=1;
%while G<=100%假设迭代100次
function creatpop=initpop(pop_size,chromsome_size)
creatpop=round(rand(pop_size,chromsome_size));
pop_decimal=pop_binary(creatpop);
fitvalue=cal(creatpop);%计算出每个个体的适应值
%创建了1000*17的矩阵,其中每一行代表该个体的染色体,round函数是四舍五入函数,rand函数是随机生成【0,1】的随机数。
%1,解码,2,带入计算适应的的函数式
%二进制数转为十进制数的函数
function pop_decimal=pop_binary(creatpop)
[px,py]=size(creatpop);
for j=1:py
value(:,j)=creatpop(:,j)*2^(py-j);
end
temp=sum(value,2);
pop_decimal=temp.*4/2^(17-1);%变为【0,4】范围内的十进制数,这就是解码的过程。
%计算适应度的函数
function value=cal(creatpop)
x=pop_binary(creatpop);
value=f(x);
end
%选择算法
%算法思想,将个体的适应度除以总适应度的值按从小到大进行排序,为之后的二分查找做准备。产生随机数,进行轮盘赌的选择法
fitness_sum(1)=fitvalue(1);
for i=2:pop_size%pop_size=1000
fitness_sum(i)=0;
fitness_sum(i)=fitvalue(i)/sum(value,2)+fitness_sum(i-1);
end
%接下来对fitness_sum进行排序,虽然matlab有sortrows函数可以实现排序,但是我们对fitness_sum进行排序后,fitness_sum的编号与createpop的编号一致,所以我们可以考虑用快排,冒泡等
% 接下来用冒泡排序进行实现
for i=pop_size-1:-1:1
for j=1:i
temp=0;
temp1=0;
if fitness_sum(i)>fitness_sum(i+1)
temp= fitness_sum(i);
fitness_sum(i)=fitness_sum(i+1);%两者进行交换
fitness_sum(i+1)=fitness_sum(i);
temp1(i,:)=creatpop(i,:);%种群同时进行交换
creatpop(i,:)=creatpop(i+1,:);
end
%进行二分查找
for i=1:pop_size
r=rand(1);
first=1;
last=pop_size;
flag=1;
while first~=last&&flag==1
s=first+last;
mid=round(s/2);
if r>fitness_sum(mid)
first=mid;
elseif r<fitness_sum(mid)
last=mid;
elseif r==fitness_sum(mid)
index=mid;
flag=0;
end
if last==first+1
index=last;
flag=0;
end
new_pop(i,:)=creatpop(i,:);
end
end
creatpop=new_pop;%选出了新的群体
%下面是变异操作
function new_pop=mutain(creatpop)
[px,py]=size(creatpop)
for i=1:px
r=rand(1);
if r<=mutain
if creat(i,r*pop_size)==1
creat(i,r*pop_size)=0;
end
end
end
new_pop=creatpop;
%下面是交叉的操作,交叉概率是交叉位置的概率
function new_pop=crosspop(creatpop)
for i=1:2:pop_size-1%每隔一个取一对
temp1=zeros(1000,pop_size);
temp2-zeros(1000,pop_sizse);
r=rand(1);
if r<=cross
dis=round(r*pop_size);
temp1(i,1:dis)=creatpop(i,1:dis);
temp2(i,dis+1:pop_size)-creatpop(i,dis+1:pop_size);
creatpop(i,1:dis)=creat(i+1,dis+1:pop_size);
creatpop(i,dis+1:pop_size)=creat(i+1,1:dis);
temp1(i,1:dis)=creat(i+1,dis+1:pop_size);
temp2(i,dis+1:pop_size)=creat(i+1,1:dis);
end
end
附:matlab刚刚学,分了两天写的,用matlab 不利索。但是基本原理均已体现,可以自己在写一下。
