HADOOP简介
Doug Cutting 和Mike Carfarella开发搜索引擎的时候遇到抓取完大量数据之后存储的问题,在看到google的一篇论文<Google File System>之后设计出了hadoop,它包含两个核心:HDFS和MapReduce
大数据拥有以下5个特点:
-
海量,数据量非常庞大,都是TB\PB级别的
-
高速,数据量持续高速增长
-
数据多样性,图片、视频、日志等数据
-
价值密度低,1TB数据中可能只有几KB数据价值比较突出
-
真实性,用海量数据表达真实性,由量到质的过程
Hadoop版本:
第一代Hadoop和第二代Hadoop
Hadoop1.0:分别是0.20.x,0.21.x和0.22.x
Hadoop2.0:分别是0.23.x和2.x。
2.0版本完全不同于Hadoop 1.0,是一套全新的架构,加入了Yarn资源协调管理框架。
Hadoop1.0和Hadoop2.0简要架构图
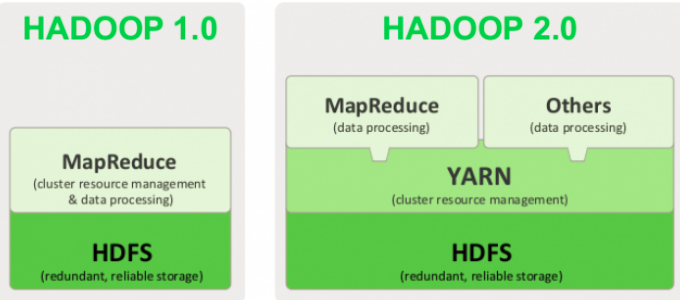
Yarn 资源调度框架——>实现对资源的细粒度封装(cpu,内存,带宽)
此外,还可以通过yarn协调多种不同计算框架(MR,Spark)
最新Hadoop3.0 2017年9月已经发布
HDFS
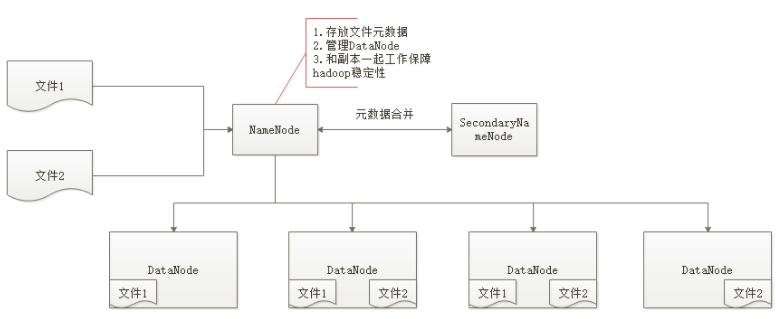
HDFS(hadoop distributed file system)是hadoop的核心之一,用来存储数据,它有两大块,NameNode和DataNode
NameNode:存储文件的元数据,保存文件存储的位置,文件切块数(文件被切分成N个块存储,每个块默认128M,1.0版本是64M)等信息
DataNode:存储文件,一般文件存储都是有三个副本,以保证一个机器挂掉,数据不会丢失,亦即避免集群单点故障出现
HDFS架构图
安装伪分布式Hadoop
配置主机
1.安装JDK
下载JDK,要求版本高于1.7
上传JDK,解压到自己专门用于存放程序的目录
配置环境变量(使用root用户登录)
vi /etc/profile
按照自己JDK所在目录进行配置
####################### jdk ############################### export JAVA_HOME=/home/jionsvolk/proc/jdk1.8.0_65 export JAVA_BIN=$JAVA_HOME/bin export PATH=$PATH:$JAVA_HOME/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export CLASSPATH
切换主机用户,执行source /etc/profile
测试JDK配置是否有问题
java -version
2.修改主机名
vi /etc/sysconfig/network
NETWORKING=yes HOSTNAME=hadoop01
将HOSTNAME=localhost改成HOSTNAME=自己的主机名
vi /etc/hosts
#将localhost后面的都删掉 127.0.0.1 localhost ::1 localhost #配置主机IP和hostname 192.168.245.141 hadoop01
因为修改的是内核参数,配置完成后需要重启主机(reboot)
配置Hadoop
1.安装hadoop(我用的2.7.1版本)
将hadoop-2.7.1_64bit.tar.gz上传到虚拟机
解压:tar -xf hadoop-2.7.1_64bit.tar.gz
2.配置hadoop环境变量
切换到root用户
vi /etc/profile
######################## hadoop ########################### HADOOP_HOME=/home/hadoop/proc/hadoop-2.7.1 PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_HOME PATH
切换回自己用户
source /etc/profile
3.配置hadoop的配置文件
core-site.xml
<configuration> <property> <!-- NameNode所在主机及端口 其中hadoop01是自己的主机名 --> <name>fs.defaultFS</name> <value>hdfs://hadoop01:9000</value> </property> <property> <!-- 元数据文件存放位置,真正使用的时候会被加载到内容中 --> <name>hadoop.tmp.dir</name> <value>/home/hadoop/data/hadoop/tmp</value> </property> </configuration>
去创建/home/hadoop/data/hadoop/tmp目录
cd /home/hadoop/data
mkdir hadoop
mkdir tmp
mapred-site.xml
默认是没有mapred-site.xml,需要执行
cp mapred-site.xml.template mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
用yarn来协调mr调度
yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
slaves
hadoop01
伪分布模式只有一台机器,所以只配置了一个slave,就是主机名-hostname
hdfs-site.xml
<configuration> <property> <!-- DataNode副本数,伪分布模式配置为1 --> <name>dfs.replication</name> <value>1</value> </property> <property> <!-- 远程访问权限打开 --> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
配置完就可以启动hadoop了
hadoop-env.sh
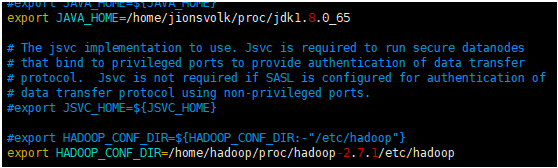
修改JAVA_HOME和HADOOP_CONF_DIR路径
在启动hadoop之前还需要两个操作
1.格式化namenode,其实就是生成fsimages和edits
hadoop namenode -format 因为之前配置了环境变量,该命令任何目录都可以执行
命令执行完之后需要看到这样的字样

2.配置SSH免密登录(在hadoop安装用户下执行)
ssh-keygen
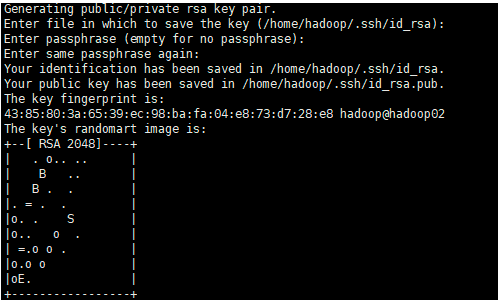
中间的操作直接敲回车
ssh-copy-id hadoop@hadoop02
hadoop:用户名
hadoop02:主机名
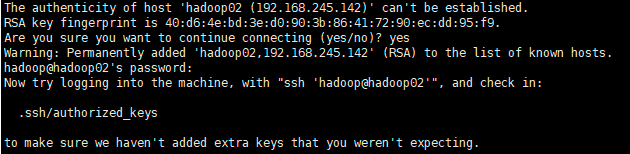
中间会要求输入hadoop用户密码
启动Hadoop
启动:sh start-dfs.sh
查看启动是否成功:jps命令

查看启动日志:

在圈出来的地方去查看启动日志
停止:sh stop-dfs.sh
测试1:创建一个目录
hadoop fs -mkdir /dir01
hadoop fs -ls /

测试2:在目录下上传一个文件
echo helloworld > 1.txt
hadoop fs -put 1.txt /dir01
hadoop fs -ls /dir01
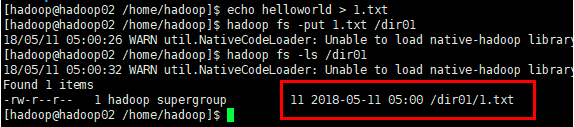
测试3:删除一个目录
hadoop fs -rmdir /dir01 删除空目录才会成功
hadoop fs -rmr /dir01 可以删除非空目录
浏览器控制台查看Hadoop
http://192.168.245.142:50070/explorer.html#/
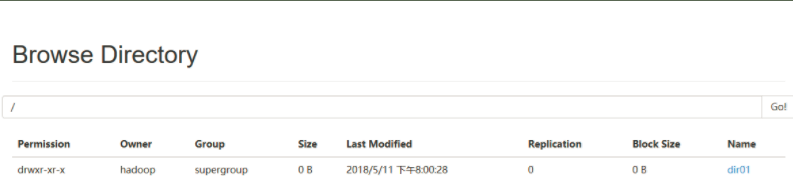
HDFS常用命令
| 命令 | 说明 |
|---|---|
| 执行:hadoop fs -mkdir /park | 在hdfs 的根目录下,创建 park目录 |
| 执行:hadoop fs -ls / | 查看hdfs根目录下有哪些目录 |
| 执行:hadoop fs -put /root/1.txt /park | 将linux操作系统root目录下的1.txt放在hdfs的park目录下 |
| 执行:hadoop fs -get /park/jdk /home | 把hdfs文件系统下park目录的文件下载到linux的home目录下 |
| 执行:hadoop fs -rm /park/文件名 | 删除hdfs 的park目录的指定文件 |
| 执行:hadoop fs -rmdir /park | 删除park目录,但是前提目录里没有文件 |
| 执行:hadoop fs -rmr /park | 删除park目录,即使目录里有文件 |
| 执行:hadoop fs -cat /park/a.txt | 查看park目录下的a.txt文件 |
| 执行:hadoop fs -tail /park/a.txt | 查看park目录下a.txt文件末尾的数据 |
| 执行:haddop jar xxx.jar | 执行jar包 |
| 执行:hadoop fs -cat /park/result/part-r-00000 | 查看 /park/result/part-r-00000文件的内容 |
| 执行:hadoop fs –mv /park02 /park01 | 将HDFS上的park02目录重名为park01命令。 |
| 执行:hadoop fs -mv /park02/1.txt /park01 | 将park02目录下的1.txt移动到/park01目录下 |
| 执行:hadoop fs -touchz /park/2.txt | 创建一个空文件 |
| 执行:hadoop fs -getmerge /park /root/tmp | 将park目录下的所有文件合并成一个文件,并下载到linux的root目录下的tmp目 |
| 执行:hadoop dfsadmin -safemode leave 离开安全模式 执行:hadoop dfsadmin -safemodeenter 进入安全模式 | 离开hadoop安全模式 在重新启动HDFS后,会立即进入安全模式,此时不能操作hdfs中的文件,只能查看目录文件名等,读写操作都不能进行。namenode启动时,需要载入fsimage文件到内存,同时执行edits文件中各项操作一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件(这个步骤不需要SNN的参与)和一个空的编辑文件。此时namenode文件系统对于客户端来说是只读的。在此阶段NameNode收集各个DataNode的报告,当数据块达到最小复本数以上时,会被认为是“安全”的,在一定比例的数据块被确定为安全后,再经过若干时间,安全模式结束当检测到副本数不足的数据块时,该块会被复制直到到达最小副本数,系统中数据块的位置并不是namenode维护的,而是以块列表的形式存储在datanode中。 当启动报如下错误时:org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode |
| 执行:hadoop dfsadmin -rollEdits | 手动执行fsimage文件和Edis文件合并元数据,这两个文件是NameNode上核心文件,fsimage保存元数据,Edits是记录操作日志,由SecondaryNameNode进行合并回传给NameNode,默认合并周期是1小时 |
| 执行:hadoop dfsadmin -report | 查看存活的datanode节点信息 |
| 执行:hadoop fsck /park | 汇报/park目录 健康状况 |
| 执行:hadoop fsck /park/1.txt -files -blocks -locations -racks | 查看1.txt 这个文件block信息以及机架信息 |
| hadoop fs -expunge | 手动清空hdfs回收站 |
对linux比较熟悉的同学应该已经发现所有HDFS的命令都和linux文件系统命令类似